La pandemia del COVID-19 no detiene a los datos. Máxime en una era en la que la digitalización ha traído tantos datos, que precisamente tenemos el problema contrario: ¿cómo separar la señal del ruido? ¿cómo entender esas complejas gráficas que nos muestran? ¿cómo saber qué información es cierta y cuál no? Desde Deusto BigData se ha organizado el 7 de abril de 2020 el webinar «Mirando al COVID-19 desde otra perspectiva: analizando datos de Google Trends» con Enrique Onieva.
Entendiendo al consumidor: la experiencia Eroski con Ana Cuevas
El procesamiento de grandes volúmenes de datos y su transformación en conocimiento es fundamental para conseguir ventajas competitivas. De todo esto y mucho más hablamos con Ana Cuevas, Directora mix comercial Grupo Eroski en otro webinar de Deusto BigData
Sistemas de recomendación con Gorka Barrenetxea
Gorka Barrenetxea, CEO y Founder de Solvenup, nos habló en un webinar de Deusto Big Data sobre los sistemas de recomendación como forma de mejorar la experiencia de usuario en la compra de productos o servicios, así como camino hacia la personalización de la oferta y beneficios.
Las empresas customer centric utilizan los sistemas de recomendación con la finalidad de complementar la humanización del uso de los datos, con el beneficio de ofrecer a los usuarios lo que realmente necesitan, y encajando con sus preferencias y búsqueda de lo idóneo y adecuado para ellos.
Webinar Deusto Big Data. “Entendiendo al algoritmo”
La Inteligencia Artificial, impulsada principalmente por el Machine Learning y Deep Learning en los últimos años, ha mostrado avances excepcionales.
El objetivo clave del área ha sido abordar y resolver problemas del mundo real, automatizar tareas complejas y hacer nuestra vida más fácil y mejor. Los algoritmos utilizados aprenden patrones y relaciones no evidentes en los datos, por lo que, explicar su funcionamiento siempre plantea sus desafíos. En particular, en aquellos ámbitos donde la toma de decisiones es sensible y puede tener impacto en el bienestar de las personas.
La técnicas de interpretabilidad y explicabilidad buscan entender y explicar el por qué y el cómo un algoritmo llega a su decisión final. De todo esto nos habla en este webinar Enrique Onieva Professor & Researcher – Artificial Intelligence, Machine Learning and Data Science de la Universidad de Deusto
Neurocomputación e Inteligencia Artificial: hackeando el cerebro
Aitor Moreno, responsable del área de Inteligencia Artificial en Ibermática y profesor del Programa de Big Data y BI en la Universidad de Deusto, nos explica que tienen en común la Neurocomputación y la Inteligencia Artificial en este webinar de Deusto Big Data.
Webinar Implementando una solución de alta demanda de Analytics – con Patricio Moreno y Owen Dempsey
El 29 de diciembre de 2020, Patricio Moreno (Partner – Director LATAM Datalytics) entrevistó a Owen Dempsey, Technology Head Latam South (Argentina, Chile, Bolivia, Paraguay, Uruguay) de Anheuser-Busch InBev (la mayor productora de cerveza del mundo con marcas tan conocidas como Coronita o Franziskaner).
Análisis de los textos de los programas para el 10 de noviembre: elecciones en españa
(Elaboración realizada por nuestro estudiante Alexander Seoane, de la 5ª promoción del Programa de Big Data y Business Intelligence en nuestra sede de Bilbao)
¿Sin tiempo para leer los programas o ver los debates electorales? Un análisis de texto con Tidytext , ggplot e igraph sobre los programas de cada partido puede ayudar a hacernos una idea de las grandes cuestiones en liza en 1 minuto. @ciudadanos @maspais_es @pp @psoe @unidaspodemos @vox
El MIT creará una facultad de Inteligencia Artificial
Dos noticias de estos últimos días han llamado mi atención. Por un lado, hemos sabido que en el Instituto de Tecnología de California (Caltech) la asignatura con mayor número de estudiantes, a pesar de ser optativa, vuelve a ser Machine Learning. Los estudiantes provienen de 23 diferentes especializaciones (fiel a la tradición americana de elección de asignaturas a lo largo de la carrera de especialización). Aquí el tweet que lo cuenta:
It’s official: #MachineLearning course by Professor Yaser Abu-Mostafa is (again) the biggest class at @Caltech, undergraduate or graduate in all departments, in spite of being an elective offered every year. The students come from 23 different majors!#DataScience #AI #BigData
— Caltech Telecourse (@telecourse) October 19, 2018
Por otro lado, y de bastante más envergadura, el MIT anuncia que va a crear una nueva facultad para trabajar la Inteligencia Artificial (IA). Un total de 1.000 millones de dólares serán invertidos. Tiene sentido que sea el MIT nuevamente, que ya tuvo mucho que ver en el nacimiento de esta disciplina que trata de desarrollar métodos que aprendan del comportamiento de los datos para luego poder generalizar. Es ya la mayor inversión realizada hasta la fecha por una institución académica en el campo de la IA.

Como se puede leer en la noticia, el MIT está diseñando la facultad mezclando inteligencia artificial, machine learning (métodos de aprendizaje sobre datos) y la propia ciencia de datos. Pero, no se quedará ahí, dado que pretende mezclarlo con otras áreas de conocimiento. Me han resultado especialmente reveladoras las palabras pronunciadas por el Rector del MIT, Rafael Reif, al hacer el anuncio:
“Computing is no longer the domain of the experts alone,”
“It’s everywhere, and it needs to be understood and mastered by almost everyone.”
De nuevo, la misma idea expresada anteriormente: los datos están transformando el mundo y sus diferentes contextos, por lo que se vuelve necesario conocer las principales técnicas para poder hacer uso de la capacidad organizativa, transformadora y de soporte que traen los métodos de gestión basados en modelos analíticos. Como dice el Rector, no es un campo propio solo de la ingeniería o la informática, sino que empieza llegar a nuevos terrenos. La inteligencia artificial, con la llegada de los grandes volúmenes de datos, ha vuelto a escena para transformar el mundo.
Otro de los aspectos reseñables de este anuncio es que introducirán la ética en sus programas de estudio. Entender el potencial impacto que tienen estos modelos inteligentes sobre los diferentes planos de la sociedad es importante. Especialmente, para los que adquirirán esas capacidades de transformación. No solo en política, sino en salud, educación, servicios sociales, etc., puede tener un impacto donde la ética no quede bien parada si no queda explícitamente reflejada. Los humanos creamos la tecnología, por lo que debemos enseñar que a la hora de hacerlo, nuestros sesgos y prejuicios debemos dejarlos de lado y hacer tecnología neutra o bien compensada.
Esto último ha vuelto a salir a escena estos días con la noticia en la que conocíamos que el algoritmo que Amazon usaba para seleccionar a sus trabajadores y trabajadoras discriminaba a las mujeres. Tarde, pero Amazon ya ha prescindido de él. Este lamentable hecho), no pensemos que existe sólo contra las mujeres y en el contexto laboral. Se pueden dar en cualquier espacio que tenga esos sesgos en el mundo real, como bien explicaba este artículo de Bloomberg.
Hace unos meses escribí un artículo sobre los movimientos que se estaban dando en diferentes países para el diseño y la creación de Ministerios de Inteligencia Artificial. Vemos como otro de los agentes sociales más relevantes para entender las consecuencias de las máquinas inteligentes, las universidades, también se están moviendo. Es interesante seguir esta tendencia para saber hasta dónde podremos llegar. ¿Veremos estas tendencias pronto por Europa?
Como dije en ese artículo:
La intencionalidad del ser humano es inherente a lo que hacemos. Actuamos en base a incentivos y deseos. Disponer de tecnologías que permiten hacer de manera automatizada un razonamiento como sujetos morales (simulando a un humano), sin que esto esté de alguna manera regulado, al menos, genera dudas. Máxime, cuando las reglas que gobiernan esos razonamientos, no las conocemos.

Velocidad, motores y big data: Evolución y retos en la Fórmula 1
Myriam Abuin Lahidalga*
El Mundial de fútbol acaba de comenzar y con él la recopilación de grandes cantidades de datos sobre pases, faltas, estrategias y rendimiento de cada jugador. Desde 2015 las distintas selecciones han comenzado a utilizar la tecnología incorporando sensores en las camisetas de entrenamiento para recabar datos que, convenientemente interpretados, sirven para encontrar la alineación ganadora o la mejora táctica del equipo.
Pero el uso de los big data no es nuevo en el deporte. Diseñadores y escuderías de Fórmula 1 llevan aplicándola desde la década de los 80. Se trataba de los primeros pasos de la telemetría aplicada al deporte. Los sensores distribuidos a lo largo de todo el monoplaza permiten testar en tiempo real las condiciones del vehículo y pilotaje, y calcular en tiempo real cómo conseguir ventaja frente a los rivales sin detenerse en boxes. Una operación que requiere no sólo un piloto experto, sino una tecnología capaz de gestionar esa ingente cantidad de datos. Pero ¿cómo funciona?

Los circuitos son espacios abiertos, diseñados en parte para minimizar los riesgos cuando se conduce a 300 kilómetros por hora y en parte para liberar de obstáculos las transmisiones de microondas (de radio) necesarias para poner en contacto el equipo con la pista. Sin embargo, algunos de ellos poseen trazados urbanos, como Mónaco o Monza, con túneles, edificios y barreras urbanas que dificultan la propagación de datos. La solución fue dotar a las pistas de un sistema parecido al de la telefonía móvil, garantizando la cobertura con un mínimo retraso de un milisegundo en la recepción. De esta manera los ingenieros de carrera pueden detectar cualquier anomalía, informar al piloto y tomar una decisión inmediata.
Hoy en día, cada monoplaza cuenta con unos doscientos sensores que envían información precisa sobre cuántas veces se acelera o se pisa el freno, cómo está el nivel de combustible o cuál es el desgaste de los neumáticos. Son datos cruciales para planificar una parada técnica que reste los menos segundos posibles a la posición del piloto en la carrera. Todo ello se recoge en un receptor/emisor, aparato que realiza ambas funciones y que además encripta la información recibida, enviándola luego a dos pequeñas antenas situadas en la parte delantera y trasera del monoplaza. A su vez, éstas remiten a un servidor.

Cada circuito cuenta con una zona reservada para cada escudería. No se trata sólo de las salas a pie de pista donde trabajan los mecánicos del equipo, sino de un amplio aparcamiento de camiones en el que se alinean varios remolques con antenas exteriores. Allí está el corazón del sistema: la sala de telemetría. Un potente servidor desencripta los datos recibidos y los prepara para que los ingenieros de cada escudería puedan gestionarlos en forma de gráficos monitorizados en varias pantallas. De este modo pueden contactar con el muro de boxes, donde están los directores de carrera y los mecánicos, en un envío mutuo de información que mejore sus opciones en tiempo real.
Pero la interpretación de esos datos no sólo sirve para mejorar la conducción o variar la estrategia en función de las circunstancias de la carrera, sino también es útil a los ingenieros de diseño, probadores de coches y a los propios pilotos. Estos últimos tienen así una visión precisa de sus errores y posibilidades de mejorar su conducción. Pero ¿cómo convertir todos esos datos en un equipo ganador?

Cada temporada las escuderías pasan muchos meses diseñando los nuevos coches. Aerodinámica, modelos matemáticos, ensayos de los prototipos en el túnel de viento… Pero la teoría no ofrece una exacta simulación de la realidad. Se necesita que el coche ruede por una pista, y tener un circuito de pruebas no está al alcance de todos los equipos. Por ello, los datos recogidos en cada gran premio son estudiados, seleccionados cuidadosamente y volcados en un ordenador que simulará el comportamiento de las piezas y comprobará la validez del nuevo diseño. Es evidente que la información en sí misma no es suficiente, pero sí puede ayudar a corregir hábitos de conducción y observar desde fuera de la pista cómo se comportará el coche en determinadas circunstancias. Por tanto, aquel equipo que sepa interpretar mejor los datos de las simulaciones tendrá muchas más posibilidades de éxito.
Además, los pilotos no tienen por qué probar físicamente el nuevo monoplaza, sino que pueden hacerlo en un simulador parecido al usado en los videojuegos de conducción. Habitualmente consiste en un sillón y una pantalla de ordenador, pero Mercedes y Ferrari construyeron una esfera montada sobre soportes hidráulicos en la que se pueden testar todas las condiciones y todos los circuitos. Otras, como Red Bull, contratan a jugadores de videojuegos para ponerse a los mandos del simulador y dejar a sus pilotos sólo las instrucciones precisas para cada carrera.
Apoyar cada decisión sobre los datos para predecir el comportamiento de los rivales o las condiciones de la carrera no es suficiente, aunque innegablemente importante. Francisco Gago, director de tecnologías digitales de la plataforma de gestión de datos Minsait de Indra, cree que los datos no ofrecen soluciones irrefutables. Y durante los últimos años se ha comprobado que es como dice. En 2010, por ejemplo, durante el Campeonato de Abu Dabi, Ferrari se tomó demasiado en serio los datos recogidos y señaló a Webber como su principal rival, haciendo caso omiso de Vettel, pero fue Vettel quien finalmente ganó la carrera. Esto se debe a que las principales variables presentes en el análisis son escasas, dado que incluyen los neumáticos, el nivel de combustible y las paradas en boxes. En el Campeonato de China de 2016, un error en el pronóstico con respecto a la temperatura de la pista hizo que Ferrari seleccionara neumáticos blandos, lo que le costó la carrera cuando se enfrentaron a los neumáticos medio duros montados por Mercedes.
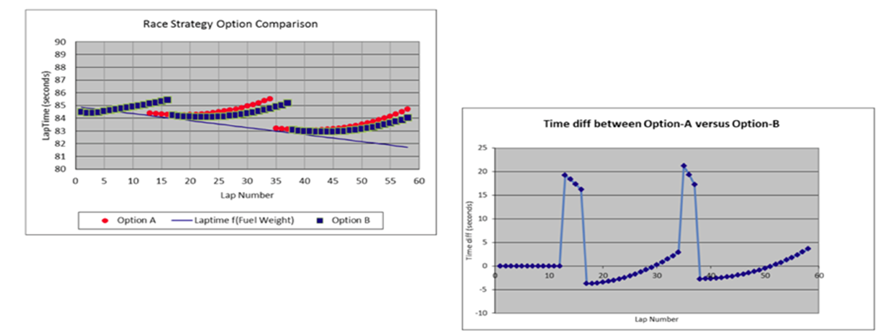
Una de las causas de estas fallas es, en primer lugar, aceptar los resultados de los algoritmos sin cuestionamiento, sin contrastarlos con las voces autorizadas en Fórmula 1. Otra razón es que cualquier imprecisión en el software de procesamiento de datos o en la cadena de transmisión, por pequeña que sea, puede tener un efecto negativo en la estrategia. La tercera y última razón es porque las variables no se contrastan y amplían con otra información. El análisis predictivo basado en big data funciona con información pasada y presente, algo que da un porcentaje de probabilidad, pero no de certeza. Dar a los algoritmos la misma fuerza que los abogados otorgan a las leyes impide que la propia experiencia y criterio del piloto (más las variables que no se tienen en cuenta) brille a la luz del pronóstico dado por los datos.
* Myriam Abuin Lahidalga es alumna del grado de Derecho y Relaciones Internacionales de Deusto. Este post está basado en su trabajo para Media in International Relations.

El perfil laboral ‘de moda’: el de analista de datos
Esta es la versión completa de una entrevista con Miren Gutiérrez, Directora del Programa de Comunciación de Datos, con David García-Maroto (@David4210) en El Independiente publicada hoy.
Estoy elaborando un reportaje sobre el perfil laboral ‘de moda’, el de analista de datos. Quería saber con detalle en qué consiste..
Es el o la especialista en los procesos de obtención, limpieza y análisis, y a veces visualización, de datos utilizando razonamiento y herramientas analíticas. Existe una variedad de métodos de análisis de datos específicos, algunos de los cuales incluyen obtención de datos, análisis estadístico, análisis de redes mediante teoría de grafos, análisis de texto y de sentimientos, inteligencia artificial y visualizaciones de datos. Cada punto en la cadena de valor del dato puede generar una especialización.
Cómo se forma un analista de datos
Depende para qué. Yo dirijo un postgrado en Deusto que se dedica a facilitar herramientas accesibles, no solo tecnológicas, sino también legales, estratégicas y sobre todo de comunicación para abordar cualquier proyecto de datos.

Pero depende. Si estamos hablando de grandes proyectos con big data, entonces una sola persona, por muy formada que esté, no es suficiente. Generalmente se trabaja en equipo, en los que buscas una mezcla de competencias y conocimientos de la industria que se esté estudiando.
Por ejemplo, un estudio un estudio de las principales plataformas big data dedicadas a observar la pesca, que acabo de publicar con el Overseas Development Institute, indica que, aunque ofrecen grandes oportunidades para la vigilancia de la pesca, aún hay mucho camino por delante. Desde la liberación del mercado de los datos satelitales hace más de una década, han ido surgiendo plataformas de datos privadas dedicadas al seguimiento de los barcos pesqueros de cierto tamaño, obligados por seguridad a emitir señales regularmente mientras están operativos. Pero el informe del ODI destaca graves fallas en estas plataformas privadas. Por ejemplo, un tercio de los 75,000 buques de pesca que figuran en la plataforma Global Fishing Watch respaldada por Google en el momento en el que investigábamos son duplicados o buques que no participan en la pesca.

Para ese tipo de proyectos se confía en profesionales que han hecho una carrera universitaria o tienen una gran experiencia escribiendo código y trabajando con inteligencia artificial. Pero también deben integrar equipos que sepan de la industria para no caer en errores como los que indicaba antes. Si te fías solo del algoritmo, éste puede identificar como barco pesquero a otro, por ejemplo uno que carga bananas, porque tiene algún comportamiento comçun con un pesquero, que es lo que le pasó a Global Fishing Watch. Hace falta saber mucho conocimiento de las industrias para hacer informes certeros y poder interpretar bien los análisis de grandes datos.
¿Qué aplicaciones tiene?
Los sectores que hasta ahora han maximizado el análisis de datos son algunas agencias gubernamentales, sobre todo en cuestiones de vigilancia masiva, y el sector privado, a veces trabajando juntos, como se vio en las revelaciones de Snowden en 2013, quien reveló que Verizon y otras telefónicas habían estado proporcionando datos de sus clientes, sin su conocimiento, a la agencia de seguridad nacional.
Como investigadora estoy más interesada en cómo se usa la infraestructura de datos, entendida como los procesos, el hardware y el software necesarios para analizar datos y extraer valor, en la sociedad civil y el periodismo.
Pero hay aplicaciones en todos los sectores. Por ejemplo, el estudio de archivos históricos, que están gradualmente digitalizándose. Un ejemplo es la edición en coreano del siglo XIII del canon budista, que incluye 52 millones de caracteres distribuidos en 166.000 páginas. Examinado con métodos tradicionales, se tenían que recurrir al análisis selectivo de fragmentos. Hoy en día la infraestructura de datos permite el estudio integral con enorme precisión de casi cualquier corpus documental digitalizado; e impulsa un cambio en la investigación, en la que ahora cobra mucha más importancia la validación de las fuentes, y las formas de comunicar conocimiento.
De las cosas más interesantes que he visto hacer con datos es el mapa de Forensic Architecture llamado Liquid Traces en el que visualiza la deriva de un barco con 72 emigrantes durante 14 días en las costas de Libia. Solo sobrevivieron 9. El mapa, basado en las mismas tecnologías de visualización de señales del Sistema de Identifiación Automática AIS, demuestra que diversos barcos de Frontex y NATO los vieron y no hicieron nada.

¿Qué empresas demandan estas competencias?
Todas. Aunque la pregunta sería qué empresas u organizaciones las necesitan y cuáles las demandan. Hay mucha necesidad en el tercer sector, pero no necesariamente se traduce en demanda. Por ejemplo, me cuenta la directora de DataKind UK, una organización que se dedica a colocar científicos y científicas de datos en ONG, que no le faltan voluntarios y voluntarias dispuestos a trabajar pro bono en una ONG, pero que no hay tantas ONG que tengan la capacidad de absorber esta capacidad y conocimiento.
Hace poco celebramos una conferencia en Madrid con representantes de organizaciones que financian proyectos sociales con datos, que los facilitan que generan plataformas y herramientas, y que hacen periodismo y activismo de datos, y una de las conclusiones que los datos pueden generar cambios sociales pero las organizaciones también deben transformarse.