El 3 de noviembre de 2015, el Director del Programa de Big Data y Business Intelligence, Alex Rayón, entrevistó a través de un webinar a tres expertos profesionales en cada uno de los tres sectores citados: Pedro Gómez (profesional del ámbito financiero), Joseba Díaz (profesional con experiencia en proyectos sanitarios y profesional Big Data en HP) y Jon Goikoetxea (Director de Comunicación y Marketing del Grupo Noticias y el diario Deia y alumno de la primera edición del Programa Big Data y Business Intelligence).
En la sesión pudimos conocer la aplicación del Big Data a los tres sectores (finanzas, sanidad y comunicación&marketing), conociendo experiencias reales y enfoques prácticos de la puesta en valor del dato. Os dejamos el enlace donde podéis escuchar el podcast de la sesión.
Son muchas las estadísticas que hacen referencia a la oportunidad de empleo que existe alrededor del Big Data. Según Gartner, en 2015 van a ser necesarios 4,4 millones de personas formadas en el campo del análisis de datos y su explotación. En este sentido, McKinsey sitúa en torno al 50% la brecha entre la demanda y la oferta de puestos de trabajo relacionados con el análisis de datos en 2018. Es decir, existe un enorme déficit de científicos y analistas de datos.
Por otro lado, el Big Data está empezando a entrar en los procesos de negocio de las organizaciones de manera transversal. Anteriormente, era empleado para necesidades concretas (evitar la fuga de clientes, mejora de las acciones del marketing, etc.), siendo impulsado mayoritariamente por los equipos técnicos y tecnológicos de las compañías. Se están creando nuevas herramientas analíticas diseñadas para las necesidades de las unidades de negocio, con sencillas, útiles e intuitivas interfaces gráficas. De este modo, el usuario de negocio impulsa la adopción de soluciones Big Data como soporte a la toma de decisiones de negocio.
La llegada de Big Data al usuario de negocio representa una oportunidad de ampliar el número de usuarios y extender el ámbito de actuación. Se prevé así que cada vez entren más proveedores, tanto de soluciones tecnológicas como de agregadores de datos. Y es que el Big Data comienza a ser el elemento principal para la transformación de las organizaciones (en constante búsqueda de la eficiencia y la mejora de sus procesos) e inclusos de sus modelos de negocio (nuevas oportunidades de monetización). En este sentido, son muchas las organizaciones que han pasado de productos a servicios, y necesitan reinventarse sobre el análisis de los datos.
Con todo ello, y ante la multidimensionalidad de esta transformación económica y tecnológica, se están creando nuevos perfiles y puestos de trabajo desconocidos en nuestra sociedad y que tienen que ver con los datos. Big Data implica un cambio en la dirección y organización de las empresas. El que no esté preparado para hacer las preguntas adecuadas, sabiendo que se lo puede preguntar a los sistemas, estará desperdiciando el potencial de su organización. Y en ello necesitará un perfil que conozca del ámbito técnico, del económico, del legal, del humano, etc., y de competencias genéricas como la inquietud, el trabajo en equipo, la creatividad, orientación a la calidad y el cliente, etc. Queda claro así, que esto no es un campo sólo técnico; es mucho más amplio y diverso.
Las empresas están empezando a entender la necesidad de trabajar con los datos, y eso teniendo en cuenta que actualmente sólo se usa el 5% del todo el caudal de datos. Pero es manifiesta la falta de talento.
Por todo ello, organizamos un ciclo de eventos que hemos denominado «El empleo hoy: oportunidades de mañana. Big Data y Business Intelligence«. El primero de ellos, será el próximo 2 de Diciembre. Contaremos con la presencia de protagonistas de este cambio. Empresas, que sí tienen esta visión del dato como elemento transformador de su organización y su modelo de negocio. Empresas, que demandan este talento que todavía es muy escaso. Puedes registrarte en este formulario, con una inscripción totalmente gratuita. El evento lo celebraremos entre las 9:15 y 13:30, en la Sala Ellacuría de la Biblioteca-CRAI de la Universidad de Deusto.
Todos los detalles del programa los podéis encontrar en la parte inferior de este artículo. Contaremos con la presencia de un reputado conferencista internacional, Patricio Moreno, CEO de la empresa Datalytics. Con mucha presencia en varios países de Latinoamérica y Europa, nos ofrecerá una visión global de las oportunidades de transformación que trae el Big Data a las organizaciones y a las personas para su desempeño laboral futuro. Además, Natalia Maeso, gerente en Deloitte, nos contará cómo desde el mundo de la consultoría (Deloitte es la primera firma en consultoría a nivel mundial), las oportunidades laborales que trae el Big Data. Los niveles de contratación del mundo de la consultoría en este sector son realmente altos.
Por último, cerraremos la jornada con una mesa redonda, en la que además de Patricio y Natalia, contaremos con Antonio Torrado de HP, Marita Alba de CIMUBISA y David Ruiz de Smartup, para debatir y conversar sobre las competencias, conocimientos y técnicas necesarias para los profesionales que hacen que las organizaciones evolucionen hacia la ventaja competitiva que ofrece la explotación de los datos.
Os esperamos a todos el 2 de Diciembre. Os dejamos el formulario de inscripción aquí.
Programa
9:15- 9:30: Recepción de asistentes y entrega de documentación.
11:45- 12:15: Caso práctico: Las oportunidades laborales que trae el Big Data. Natalia Maeso, gerente en Deloitte.
12:15- 13:30: Mesa redonda: Competencias, conocimientos y técnicas necesarias para los proyectos Big Data en diferentes sectores estratégicos de la economía.
Suelo decir en los cursos que el gran reto que nos queda por resolver es «pintar bien el Big Data«. Con estas palabras semánticamente pobres, lo que trato de decir es que la representación visual del dato no es un tema trivial; y que nos podemos esforzar en hacer un gran proyecto de tratamiento de datos, integración y depuración, etc., que si luego finalmente no lo visualizamos apropiadamente, el usuario puede no estar completamente satisfecho con ello. Por ello, he querido dedicar este artículo para hablar del área del Visual Analytics o visualización analítica e inteligente de datos.
Antoine de Saint-Exupery, autor de “El principito”, dijo eso de “La perfección se alcanza no cuando no hay nada más que añadir, sino cuando no hay nada más que quitar”. Es decir, un enfoque minimalista. Y es que la visualización de información es una mezcla entre narrativa, diseño y estadística. Estos tres campos tienen que ir inexorablemente unidos para no correr el peligro de perderse con la interpretación de la idea a través de estímulos visuales. Las buenas representaciones gráficas, deben cumplir una serie de características:
Señalar relaciones, tendencias o patrones
Explorar datos para inferir nuevo conocimiento
Facilitar el entendimiento de un concepto, idea o hecho
Permitir la observación de una realidad desde diferentes puntos de vista
Y permitir recordar una idea.
Estos serán nuestros cinco objetivos cuando representamos algo en una gráfica o representación visual. A partir de hoy, nuestras cinco obsesiones cuando vayamos a representar una idea o relación de manera gráfica. ¿Cumplen estas características tus visualizaciones de datos e información? La puesta en valor del dato, como ven, no es algo trivial. Para prueba, un caso, cogido medianamente al azar:
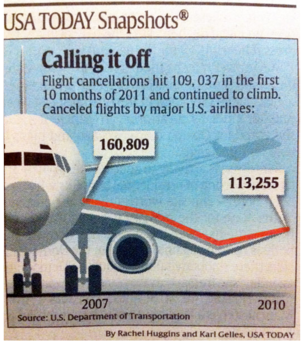
Cancelaciones de aviones desde 2007 a 2010 (Fuente: USA TODAY)
¿Problemas? En primer lugar, ¿qué quiere señalar? Si es una relación, tendencia o patrón, ¿no debería darnos más idea de si los números son relevantes o no? ¿qué significan? ¿cómo me afectan? No facilita entender un concepto, sino que introduce varias dimensiones (tiempo, cancelaciones de vuelos, variación de la tendencia, etc.). Y, encima, lo hace representándolo sobre el ala de un avión. ¿Quiere transmitir seguridad o inseguridad? Genera dudas. Hubiera sido esto más simple si fuera como una cebolla con una única capa: una idea, una relación, un concepto clave. No hace falta más.
La representación visual es una forma de expresión más. Como las matemáticas, la música o la escritura, tiene una serie de reglas que respetar. Hoy en día, en que la cantidad de datos y la tecnología ya no son un problema, el reto para las empresas recae en conocer los conceptos básicos de representación visual. Es lo que se ha venido a conocer como la ciencia del Visual Analytics, definida como la ciencia del razonamiento analítico facilitado a través de interfaces visuales interactivas. De ahí que hoy en día los medios de comunicación utilicen cada vez estas representaciones gráficas de datos e información con las que podemos interactuar.
El uso de representaciones visuales e interactivas de elementos abstractos permite ampliar y mejorar el procesamiento cognitivo. Por lo tanto, para transladar ideas y relaciones, ayuda mucho disponer de una gráfica interactiva. Hay muchos teóricos y autores que se han dedicado a generar teoría y práctica en este campo de la representación visual de información. De hecho, la historia de la visualización no es algo realmente nuevo. En el Siglo XVII, ya destacaron autores como Joseph Priestley y William Playfair. Más tarde, en el Siglo XIX, podemos citar a John Snow, Charles J. Minard y F. Nightingale como los más relevantes (destacando especialmente el primero, que a través de una representación geográfica logró contener una plaga de cólera en Londres). Ya en el Siglo XX, Jacques Bertin, John Tukey, Edward Tufte y Leland Wilkinson son los autores más citados en lo que a visualización y representación de la información se refiere.
Representación gráfica del brote de cólera de John Snow: nacen así, los Sistemas de Información Geográfica o SIG (Fuente: http://blog.rtwilson.com/john-snows-cholera-data-in-more-formats/)
Tufte es quizás el autor más citado. Su libro “The Visual Display of Quantitative Information”, una biblia para los equipos de visualización eficientes y rigurosas. De hecho, los principios de Tufte, los podemos resumir en la integridad gráfica y el diseño estético. Siempre destaca cómo los atributos más importantes el color, el tamaño, la orientación y el lugar de la página donde presentamos una gráfica. Y es que, por mucho que nos sorprenda o por simple que nos parezca, la codificación del valor (datos univariados, bivariados o multivariados) y la codificación de la relación de valores (líneas, mapas, diagramas, etc.), no es un asunto trivial. Un ejemplo de esto sería la siguiente gráfica:
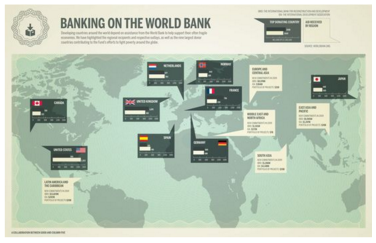
Banking the World Bank (Fuente: http://blogs.elpais.com/.a/6a00d8341bfb1653ef0153903125d9970b-550wi)
Si cogemos el gráfico anterior y yo os hago preguntas relacionadas con la identificación del mayor donante o el mayor receptor, ustedes tendrían problemas. Quizás con un patrón de color esto se hubiera resuelto. Pero ni con esas. Un mapa no es la mejora manera de representar este tipo de datos (y hoy en día se abusa mucho de los mapas). Si quiero responder a las preguntas anteriores, tengo que realizar una búsqueda de las cifras, memorizarlas y luego compararlas. Lo dicho al comienzo; una idea, un patrón, una relación, y luego, búsqueda de la mejor gráfica para ello. Por eso los gráficos de tarta… mejor dejarlos para el postre 😉 (los humanos no somos especialmente hábiles comparando trozos de un círculo cuando hablamos de áreas… que es lo que propone un gráfico de tarta con los trocitos en los que descomponemos un círculo)
Quizás la referencia más importante de todo esto que estamos hablando se encuentre en el artículo que en 1985 escribieron Cleveland y McGill, titulado “Ranking of elementary perceptual tasks”. Dos investigadores de AT&T Bell Labs, William S. Cleveland y Robert McGill, publicaron este artículo central en el Journal of the American Statistical Association. Propone una guía con las representaciones visuales más apropiadas en función del objetivo de cada gráfico, lo cual nos ofrece otro pequeño manual para ayudarnos a representar la información de manera inteligente y eficiente.
“A graphical form that involves elementary perceptual tasks that lead to more accurate judgements than another graphical form (with the same quantitative information) will result in a better organization and increase the chances of a correct perception of patterns and behavior.” (William S. Cleveland y Robert McGill, 1985)
Dicho todo esto, y con la aparición del Big Data, muchos autores comenzaron a trabajar en crear metodologías eficientes para la visualización de información. Lo que hemos denominado al comienzo como Visual Analytics: la visualización analítica, eficiente e inteligente de datos que ayuda a aumentar el entendimiento e interpretación de una idea, una relación, un patrón, etc.
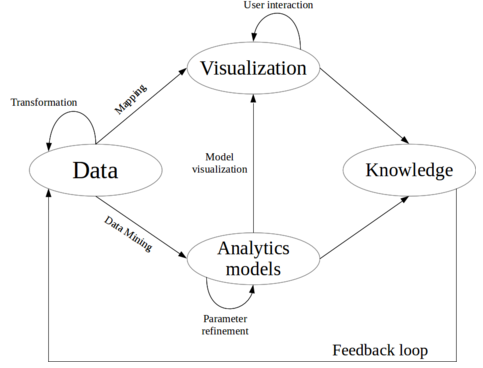
En nuestro Programa de Big Data y Business Intelligence, celebraremos próximamente una sesión en la que precisamente hablaremos de todo esto. Cómo seguir una serie de pasos y criterios a considerar para ayudar al lector, al usuario, a entender y pensar mejor. Un campo que se nutre de los conocimientos del área de Human-Computer-Interaction (HCI) y de la visualización de información. Y, como muestro en la siguiente figura (un proceso de Visual Analytics basado en trabajos de Daniel Keim y otros), aplicaremos un método para pasar del dato al conocimiento, a través de los modelos analíticos y la visualización de información que no confunda, y como decía Saint-Exupery, simplifique.
Proceso de Visual Analytics (Fuente: elaboración propia)
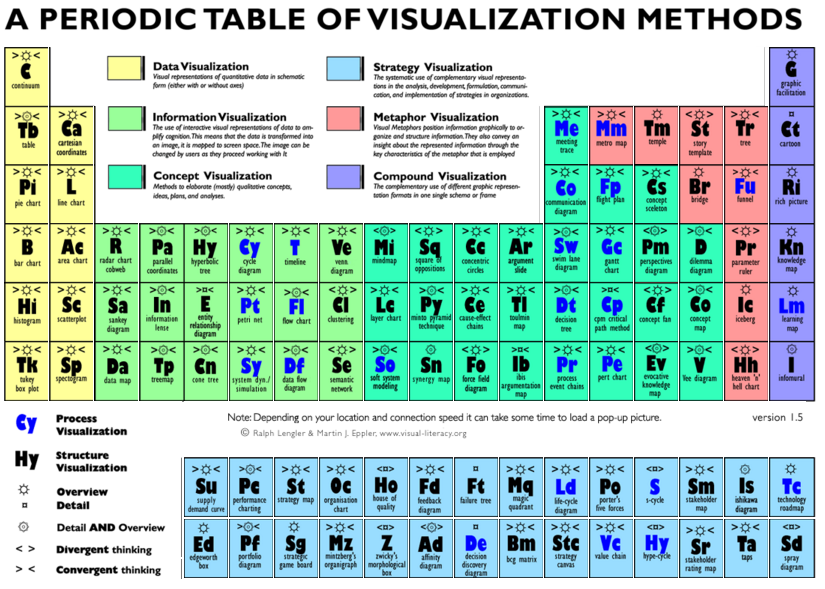
¿Cuál será el resultado de esta sesión? Un dashboard, un informe, un panel de mando de KPIs bien diseñado y elaborado. Es decir, conocimiento eficiente e inteligente para ayudar a las organizaciones a tomar decisiones apoyándose en gráficos bien elaborados. Un dashboard que cumpla con nuestros cinco principios y que permita al estudiante llevarse su tabla periódica de los métodos de visualización eficiente.
Tabla periódica de los métodos de visualización (Fuente: http://www.visual-literacy.org/periodic_table/periodic_table.html)
Asistimos en estos últimos años a una gran revolución silenciosa en el ámbito tecnológico: Internet de las cosas, aplicaciones móviles, smart cities, big data, etc. Son temas que están a diario en los blogs y publicaciones digitales, y también en boca de los profesionales. Y en mi opinión el gran desconocido en toda esta evolución es el asesor jurídico del proyecto.
Siempre que un tecnólogo, informático o emprendedor en general oye la mención al asesoramiento jurídico huye como de ello como de la pólvora. Sin embargo, es la clave para que un proyecto tecnológico salga adelante o no.
El problema es encontrar a alguien que aporte al proyecto una visión facilitadora, que provoque que el proyecto avance pero que al mismo tiempo consiga que el proyecto no se salga de los raíles de lo legalmente permitido.
Si no conseguimos este equilibrio, el resultado siempre será malo, y pueden darse dos casos de fracaso: No tengo en cuenta el asesoramiento, hasta el final del proyecto, y por lo tanto, si no estoy cumpliendo los requisitos legales, el proyecto puede quedar paralizado por este incumplimiento; o lo tengo en cuenta, pero no es el asesoramiento adecuado, y consigue paralizar o hacer inútil el proyecto.
Este equilibrio es la clave. Actualmente existen metodologías innovadoras que permitirán que los proyectos tecnológicos, bien asesorados, avancen y sean exitosos, el secreto es saber implementarlas y utilizarlas adecuadamente, y siempre con la perspectiva de que el proyecto tenga una buena orientación .
Sin embargo, y en el momento en que nos encontramos debemos mantener una doble perspectiva: debemos cumplir en lo sustancial la normativa en vigor (Ley Orgánica de Protección de Datos y Reglamento de desarrollo), pero al mismo tiempo debemos enfocar la nueva normativa, insertando estos principios en los proyectos innovadoras. Las herramientas por lo tanto deben de ser dobles, y adaptadas permanentemente.
Y ello sin olvidar las modificaciones que introducirá el Reglamento Europeo de Protección de Datos una vez que sea aprobado, el cual previsiblemente introducirá la obligación de realizar evaluaciones en todos los procesos en los que haya tratamiento masivo de datos personales, lo que, de aquí en adelante, será lo habitual.
Como conclusión, un panorama que reivindica el papel del experto en Derecho en este mundo tecnológico y reivindica además una visión jurídica estricta de este problema. Y en todo ello, destaca la protección de datos como elemento a cuidar y respetar.
El proceso de Extracción (E), Transformación (T) y Carga (L, de Load en Inglés) -ETL- consume entre el 60% y el 80% del tiempo de un proyecto de Business Intelligence. Suelo empezar con este dato siempre a hablar de las herramientas ETL por la importancia que tienen dentro de cualquier proyecto de manejo de datos. Tal es así, que podemos afirmar que proceso clave en la vida de todo proyecto y que por lo tanto debemos conocer. Y éste es el objetivo de este artículo.
La cadena de valor de un proyecto de Business Intelligence la podemos representar de la siguiente manera:
Cadena de valor de un proyecto de BI (Fuente: http://www.intechopen.com/books/supply-chain-management-new-perspectives/intelligent-value-chain-networks-business-intelligence-and-other-ict-tools-and-technologies-in-suppl)
Hecha la representación gráfica, es entendible ya el valor que aporta una herramienta ETL. Como vemos, es la recoge todos los datos de las diferentes fuentes de datos (un ERP, CRM, hojas de cálculo sueltas, una base de datos SQL, un archivo JSON de una BBDD NoSQL orientada a documentos, etc.), y ejecuta las siguientes acciones (principales, y entre otras):
Validar los datos
Limpiar los datos
Transformar los datos
Agregar los datos
Cargar los datos
Esto, tradiocionalmente se ha venido realizando con código a medida. Lo que se puede entender, ha traído muchos problemas desde la óptica del mantenimiento de dicho código y la colaboración dentro de un equipo de trabajo. Lo que vamos a ver en este artículo es la importancia de estas acciones y qué significan. Por resumirlo mucho, un proceso de datos cualquiera comienza en el origen de datos, continúa con la intervención de una herramienta ETL, y concluye en el destino de los datos que posteriormente va a ser explotada, representada en pantalla, etc.
¿Y por qué la importancia de una herramienta ETL? Básicamente, ejecutamos las acciones de validar, limpiar, transformar, etc. datos para minimizar los fallos que en etapas posteriores del proceso de datos pudieran darse (existencia de campos o valores nulos, tablas de referencia inexistentes, caídas del suministro eléctrico, etc.).
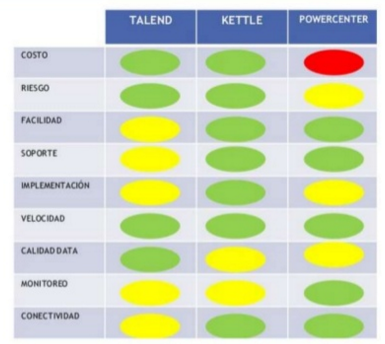
Este parte del proceso consume una parte significativa de todo el proceso (como decíamos al comienzo), por ello requiere recursos, estrategia, habilidades especializadas y tecnologías. Y aquí es donde necesitamos una herramienta ETL que nos ayude en todo ello. ¿Y qué herramientas ETL tenemos a nuestra disposición? Pues desde los fabricantes habituales (SAS, Informatica, SAP, Talend, Information Builders, IBM, Oracle, Microsoft, etc.), hasta herramientas con un coste menor (e incluso abiertas) como Pentaho Kettle, Talend y RapidMiner. En nuestro Programa de Big Data y Business Intelligence, utilizamos mucho tanto SAS como Pentaho Kettle (especialmente esta última), por lo que ayuda a los estudiantes a integrar, depurar la calidad, etc. de los datos que disponen. A continuación os dejamos una comparación entre herramientas:
Comparación Talend vs. Pentaho Kettle
¿Y qué hacemos con el proceso y las herramientas ETL en nuestro programa? Varias acciones, para hacer conscientes al estudiante sobre lo que puede aportar estas herramientas a sus proyectos. A continuación destacamos 5 subprocesos, que son los que se ejecutarían dentro de la herramienta:
Extracción: recuperación de los datos físicamente de las distintas fuentes de información. Probamos a extrar desde una base de datos de un ERP, CRM, etc., hasta una hoja de cálculo, una BBDD documental como un JSOn, etc. En este momento disponemos de los datos en bruto. ¿Problemas que nos podemos encontrar al acceder a los datos para extraerlos? Básicamente se refieren a que provienen de distintas fuentes (la V de Variedad), BBDD, plataformas tecnológicas, protocolos de comunicaciones, juegos de caracteres y tipos de datos.
Limpieza: recuperación de los datos en bruto, para, posteriormente: comprobar su calidad, eliminar los duplicados y, cuando es posible, corrige los valores erróneos y completar los valores vacíos. Es decir se transforman los datos -siempre que sea posible- para reducir los errores de carga. En este momento disponemos de datos limpios y de alta calidad. ¿Problemas?ausencia de valores, campos que tienen distintas utilidades, valores crípticos, vulneración de las reglas de negocio, identificadores que no son únicos, etc. La limpieza de datos, en consecuencia, se divide en distintas etapas, que debemos trabajar para dejar los datos bien trabajados y limpios.
Depurar los valores (parsing)
Corregir (correcting)
Estandarizar (standardizing)
Relacionar (matching)
Consolidar (consolidating)
Transformación: este proceso recupera los datos limpios y de alta calidad y los estructura y resume en los distintos modelos de análisis. El resultado de este proceso es la obtención de datos limpios, consistentes y útiles. La transformación de los datos se hace partiendo de los datos una vez “limpios” (la etapa 2 de este proceso)(. Transformamos los datos de acuerdo con las reglas de negocio y los estándares que han sido establecidos por el equipo de trabajo. La transformación incluye: cambios de formato, sustitución de códigos, valores derivados y agregados, etc.
Integración: Este proceso valida que los datos que cargamos en el datawarehouse o la BBDD de destino (antes de pasar a su procesamiento) son consistentes con las definiciones y formatos del datawarehouse; los integra en los distintos modelos de las distintas áreas de negocio que hemos definido en el mismo.
Actualización: Este proceso es el que nos permite añadir los nuevos datos al datawarehouse o base de datos de destino.
Para concluir este artículo, os dejamos la presentación de una de las sesiones de nuestro Programa de Big Data y Business Intelligence. En esta sesión, hablamos de los competidores y productos de mercado ETL.
En nuestro workshop del pasado 27 de Octubre, también estuvo como ponente Jesús Barrasa, Field Engineer de Neo Technology. Básicamente, el objetivo de su ponencia fue contarnos cómo poder prevenir el fraude a través de la modelización de la información en grafos. Este formalización matemática, que ha ganado bastante popularidad en los últimos años, permite una expresividad de información tan alta, que para muchas aplicaciones donde el descubrimiento de la información es crítica (como es el evitar el fraude), puede ser vital.
Pero, empecemos por lo básico. Jesús, nos describió lo que es un grafo. Un conjunto de vértices (o nodos), que están unidos por arcos o aristas. De este modo, tenemos una información representada a través de relaciones binarias entre el conjunto de elementos. Fue Leonhard Euler, matemático suizo, el inventor de la teoría de grafos en 1736. Por lo tanto, no estamos hablando de un instrumento matemático nuevo.
Un grafo, como conjunto de vértices y arcos (Fuente: https://www.flickr.com/photos/thefangmonster/352461415/in/photolist-x9suX-fDVc6-88T8hQ-7X9u8d-afsXkh-i6KLs-6PpBb6-836Ttv-85z1hy-rA46-rjfq-5RTzeU-bDcg8x-f5s1g3-a1Jv37-bsDVCK-7i62o-5WbpbF-i6LKS-aRBH8x-5RPjSa-h1Xkr2-4d5ypn-DifCQ-7SGo1D-9C4Y3c-noNEE9-7noTPo-7dYzTc-7dYzxZ-d672zw-99Z1f9-bz2Y9P-bquhCW-881tVy-4vn6sS-7Zebpn-4t7P4n-bdYG1z-ePUf2-aVcE68-f7Tsq-7JdUAY-bmhmrn-e2KEC6-63bkHm-e8zMaZ-88V6bY-9ZjTax-7SGo6Z)
Pues bien, este tipo de representación de información (en grafos) es el tipo de bases de datos que más está ganando en popularidad en los últimos años (consultar datos aquí). Su uso en aplicaciones como las redes sociales (y todo lo que tiene que ver con el Análisis de Redes Sociales o Social Network Analysis), el análisis de impacto en redes de telecomunicaciones, sistemas de recomendación (como los de Amazon), logística (y la optimización de los puntos de entrega -vértices- a través de la distancia entre puntos – longitud de las aristas -), etc., son solo algunos ejemplos de la potencia que tiene la representación de la información en grafos.
Jesús nos introdujo un caso concreto que desde Neo Technology han trabajado para la detección y prevención del fraude. Un contexto de aplicación, que además de tener cierta sensibilidad social en los últimos años, no solo es aplicable al ámbito económico, sino también a muchos otros donde el fraude ha sido recurrente y muy difícil de detectar. El problema hasta la fecha es que los límites del modelo relacional de bases de datos (el que ha imperado hasta la fecha) han traído siempre una serie de asuntos que complicaban la detección:
Complejidad al modelizar relaciones (por asuntos como la integridad relacional, etc.)
Degradación del rendimiento al aumentar el número de asociaciones y con el volumen de datos
Complejidad de las consultas
La necesidad de rediseñar el esquema de datos cuando se introducen nuevas asociaciones y tipos de datos
etc.
Estos puntos (entre otros), hacen que las bases de datos relacionales tradicionales resulten hoy en día inadecuadas cuando las asociaciones entre puntos de datos son útiles y valiosas en tiempo real. Y aquí es donde las bases de datos NoSQL (orientadas a documentos, las columnares, las de grafos, etc.), son bastante útiles para soliviantar este problema.
Introducida esta necesidad por las bases de datos de grafos, Jesús nos contó el caso concreto de los defraudadores. Personas que solicitan líneas de crédito, actúan de manera aparentemente normal, extienden el crédito y de repente desaparecen. De hecho, decenas de miles de millones de dólares son defraudados al año solo a bancos estadounidenses. 25% del total de créditos personales son amortizados como pérdidas. Para prevenir esto, la modelización de los datos como grafos puede ayudar.
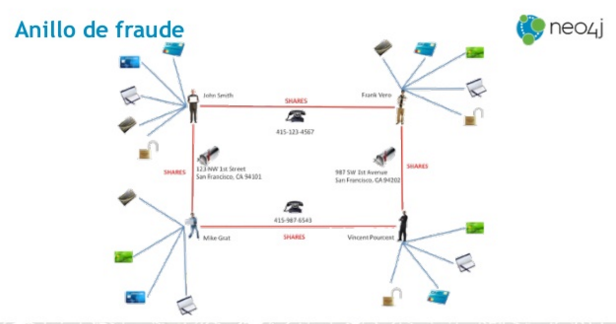
¿Qué es lo que se representa como un grafo? ¿Qué datos/información? Lo que Jesús denominó los anillos de fraude (que podéis encontrar en la imagen debajo de estas líneas). Acciones que va realizando un usuario, y que como son representadas a través de relaciones, permite no solo detectar el fraude, sino también minimizar pérdidas y prevenirlo en la medida de lo posible a través de cadenas de conexión sospechosas.
Anillo de fraude (Fuente: Neo Technology)
Como siempre, os dejamos al final de este artículo las diapositivas empleadas por Jesús. Otro caso más de aplicación del Big Data y de mejora de las sociedades, empresas e instituciones a través de la puesta en valor de los datos. En este caso, los grafos.
En el workshop que organizamos el pasado 27 de Octubre, también participó CIMUBISA, entidad municipal del Ayuntamiento de Bilbao. Básicamente, nos habló sobre la formulación estratégica de ciudad que tenía Bilbao, y cómo el Big Data impactaba sobre ella.
CIMUBISA expuso la formulación estratégica de ciudad que tiene Bilbao. Una estrategia que gira en torno a 5 ejes de actuación:
Administración 4.0
Tecnologías en el espacio urbano
Ciudadanía digital y calidad de vida
Desarrollo económico inteligente
Gobernanza
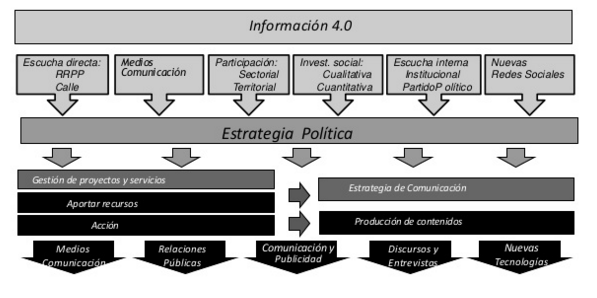
Y en esta estrategia, el dato, la información, resultan clave para ayudar a decidir. No podemos construir una administración inteligente sin una información de calidad para tomar decisiones que beneficien a la sociedad en su conjunto. Prueba de ello es la representación esquemática que se muestra a continuación, en la que la estrategia política, se artícula en torno a diferentes fuentes de información, que la estrategia «Smart City Bilbao» procesa y pone en valor. Fuentes como la escucha directa en la calle, lo que los medios de comunicación señalan sobre la ciudad, lo que se obtiene del fomento de la participación, investigaciones cuantitativas y cualitativas, escucha institucional interna, redes sociales, etc.
La información para decidir, estrategia de Smart Bilbao (Fuente: http://www.slideshare.net/deusto/smart-bilbao-los-datos-al-servicio-de-la-ciudad-big-data-open-data-etc)
¿Y con todos estos datos recogidos que se hace en Bilbao? Un análisis descriptivo, predictivo y prescriptivo. Es decir, técnicas de data mining para extraer más información aún de los datos ya capturados. Un carácter descriptivo para saber lo que pasa en Bilbao; un carácter predictivo para simular lo que pudiera pasar en Bilbao cuando se den unos valores en una serie de variables; y un carácter prescriptivo para recomendar a Bilbao en qué parámetros se ha de incidir para mejorar la gestión y la administración en aras de maximizar el bienestar del ciudadano.
En última instancia, esos datos capturados y tratados con carácter descriptivo, predictivo y prescriptivo, es visualizado. ¿De qué manera? Gráficos, tablas, dashboards, mapas de calor, etc., en áreas como la movilidad y el tráfico, la seguridad y emergencias, la gestión de residuos, eficiencia energética, etc.
Mapas para la visualización de datos de la ciudad de Bilbao (Fuente: http://www.slideshare.net/deusto/smart-bilbao-los-datos-al-servicio-de-la-ciudad-big-data-open-data-etc)
Por último, nos hablaron del proyecto Big Bilbao, un nuevo concurso que aspira a posicionar a Bilbao en el mapa en esto del Big Data. Un proyecto transformador de inteligencia de ciudad. El principal objetivo de este proyecto es crear una plataforma que permita explotar datos de distintas fuentes, estructurados y no estructurados, que permitan mejorar la eficiencia de la gestión de la ciudad. Es decir, una smart city con funcionalidades avanzadas y de altas prestaciones.
El workshop, titulado como «Aplicación del Big Data en sectores económicos estratégicos«, tenía como principal objetivo mostrar la aplicación del Big Data en varios sectores estratégicos para la economía Española (finanzas, sector público, cultura, inversión y turismo). La primera de las intervenciones corrió a cargo de Jorge Monge, de Management Solutions, que nos expuso cómo elaborar un scoring financiero y su relevancia en la era del Big Data.
La revolución tecnológica se produce a magnitudes nunca antes observadas. El sector financiero no es ajeno a ese cambio, conjugando una reestructuración sin precedentes, con un cambio de perfil de usuario muy acusado. Así, se está pasando de la Banca Digital 1.0 a la 4.0, una innovación liderada por el cliente, y donde la analítica omnicanal con datos estructurados y no estructurados se torna fundamental.
La Banca Digital 4.0 (Fuente: Management Solutions)
Las entidades financieras, gracias a esta transformación digital, disponen de gran cantidad de información pública, con la que hacer perfiles detallados no solo a sus clientes actuales, sino también a sus clientes potenciales. Dado que la capacidad de procesamiento se ha visto multiplicado por las nuevas arquitecturas del Big Data, esto tampoco supone un problema. Los modelos de scoring (como el que Jorge expuso) pertenecen al ámbito de riesgos de las entidades bancarias, intentando clasificar a los clientes potenciales en función de su probabilidad de impago. Nos contó un proyecto real en el que con datos anonimizados de una cartera de 72.000 clientes potenciales, se mezclaron datos tradicionales de transacciones, con datos de redes sociales, para conformar un modelo analítico. Éste, conformado por variables significativas de cara a evaluar el incumplimiento, permitía mejorar el poder precitivo del scoring bancario.
El reto actual radica en la gran cantidad de datos. Jorge señaló cómo aunque se genere gran cantidad de información, esta no sería útil si no pudiera procesarse. Sin embargo, la capacidad de procesamiento se ha visto multiplicada por las nuevas arquitecturas de Big Data. Destacó, aquí, Hadoop, Hive, Pig, Mahout, R, Python, etc. Varias de las herramientas que ya comentamos en un post pasado.
Por último, destacaba, que el reto ya no es tecnológico. El reto es poder entender el procesamiento que hacen estas herramientas. Así, ha surgido un nuevo rol multidisciplinar para hacer frente a este problema: el data scientist, que integra conocimientos de tecnología, de programación, de matemáticas, de estadística, de negocio, etc. Hablaremos de este perfil más adelante. Y, cerraba la sesión, destacando la importancia de la calidad de la información, el reto que suponen las variables cualitativas y la desambiguación.
Os dejamos, para finalizar el artículo, la presentación realizada por Jonge Monge. Aprovechamos este artículo para agradecerle nuevamente su participación y aportaciones de valor.