El carácter de derecho fundamental de la protección de datos personales, pone en jaque la convivencia con otros derechos como por ejemplo, la competencia económica dentro del seno de la Unión Europea.
Este hecho se refleja en el posicionamiento de la Unión en cuanto a las condiciones que la ley establece en la formación del consentimiento del interesado: toda manifestación de voluntad libre, específica, informada e inequívoca por la que el interesado acepta, ya sea mediante una declaración o una clara acción afirmativa, el tratamiento de datos personales que le conciernen”. Digamos que la variedad principal es la eliminación del consentimiento tácito.
Sin embargo, y como veremos a continuación, esta novedad no parece que cumpla con el objetivo del Reglamento en devolver al ciudadano el control de sus datos.
En primer lugar, hasta el día de hoy, prácticamente nadie se lee las políticas de privacidad. Al fin y al cabo, las misma están redactadas en un lenguaje jurídico nada aterrizado al ciudadano y el coste de invertir tiempo en entenderlos sigue siendo con la RGPD, alto. Por otra parte, el entender un texto de privacidad no implica comprender el alcance de la vida de los datos personales en la red ni que el ciudadano, descubra el poder de su privacidad a través de un click.
En segundo lugar, la ley no resuelve el consentimiento en los casos de asimetrías de poder frente a los servicios de las gigantes tecnológicas como Google o Facebook, ni en aquéllos casos que se consiente la cesión de datos en aras de recibir un servicio que sin otro modo no se logra. Muy en contrario, el Reglamento restringe la competencia al eliminar la privacidad como motor entre ofertantes en el mercado, puede causar un incremento en el precio e incluso restringir el acceso a datos de consumidores en el mercado. Siendo las principales perdedoras las start ups que aún no disponen de los mismos.
En tercer lugar, tampoco tenemos alternativas a los Estados actuales proclives a utilizar la seguridad nacional y el interés público como justificación de utilización de datos para su propio beneficio. Incluso, en casos como en brechas de seguridad por parte de las empresas, el Estado obtiene acceso legalizado a los datos.
En definitiva, el Reglamento de manera contra-producente restringe la competencia y crea barreras de entrada a las start-ups que podrían desestabilizar a las gigantes bajo políticas de privacidad (o otros métodos) más atractivas. No será la ley en última instancia quién otorgue la solución, sino que será la tecnología a través de sus métodos innovadores quien se adapte.
Política de privacidad en el RGPD (Fuente: https://www.adaptacionlopdonline.com/blog/?politica-de-privacidad-en-el-rgpd–7-)
Resulta sorprendente que uno de los puntos más confusos del nuevo Reglamento General de Protección de Datos (RGPD), sea la propia contextualización social en la que se sustenta: la imprecisa conexión entre la privacidad y los datos de carácter personal.
Reglamento Europeo de Protección de Datos o RGPD (Fuente: https://tulopd.es/wp-content/uploads/sites/8/2016/09/RGPD.png)
Veamos ahora porqué este criterio puede hacer del reglamento una ley inefectiva:
El concepto de privacidad ha sido objeto de evolución y re-definición a lo largo de los tiempos a medida que la sociedad avanzaba y se adaptaba a los retos del momento. No debemos entender el concepto de privacidad como absoluto, pues la privacidad es un conjunto de atributos personales que competen a la persona y la cesión que realiza en el día a día de cada atributo que la compone, la valora el propio sujeto en base a lo que recibe a cambio.
Desde que internet se materializó como parte de nuestra actividad diaria, el mundo del dato ha impulsado la re-valorización de la privacidad. De hecho, el propio concepto de privacidad ha sido transformado por todos nosotros durante la última década al interactuar en el espacio digital a cambio de beneficios económicos y sociales. Sin embargo, la cesión de privacidad de los individuos ha traído una ola de incertidumbre presente y de futuro.
Por ello, uno de los puntos clave del Reglamento es el controldel usuario de sus datos durante toda la vida del dato con especial hincapié en el procesamiento de los mismos. Por tanto, el legislador europeo faculta al usuario del derecho a controlar sus datos personales y la capacidad para disponer y decidir sobre los mismos [1]. De manera que, este derecho dota al individuo de un campo mayor de ejercicio, donde el Reglamento también es aplicable en aquéllos casos que no se vulnera o genera un riesgo real a la privacidad de las personas.
Esto tiene varias acepciones desde el punto de vista del dato y del usuario:
Que el reglamento intervenga en la vida del dato cuando no comporta ningún riesgo y que por tanto, se establezcan prohibiciones que vulneren el valor del dato. En última instancia, repercutirán en los servicios que proporcionan a los propios usuarios.
Que el ciudadano, al no poder realizar un cálculo de impacto en su esfera privada desconozca las implicaciones de sus decisiones en todo el proceso de la vida de sus datos. Y que por tanto, el ciudadano no sea capaz de tener un control efectivo sobre ellos.
En definitiva, puede generar un desequilibrio entre el mundo físico del usuario y el universo digital del dato que podría optimizarse si la legislación en lugar de ser resultado de la planificación de los gobiernos, facilitara la fusión de los dos mundos.
[1] Agencia Española de Protección de Datos: http://www.agpd.es/portalwebAGPD/CanalDelCiudadano/derechos/index-ides-idphp.php
La nueva economía digital se enmarca en una era en la que mucha gente piensa que lo que hacemos en Internet, lo que usamos, en muchas ocasiones, es gratis. Los economistas suelen decir eso de que «nada es gratis«. Obviamente, algo o alguien tiene que pagar los servicios y productos que consumimos. Y esos, son los datos.
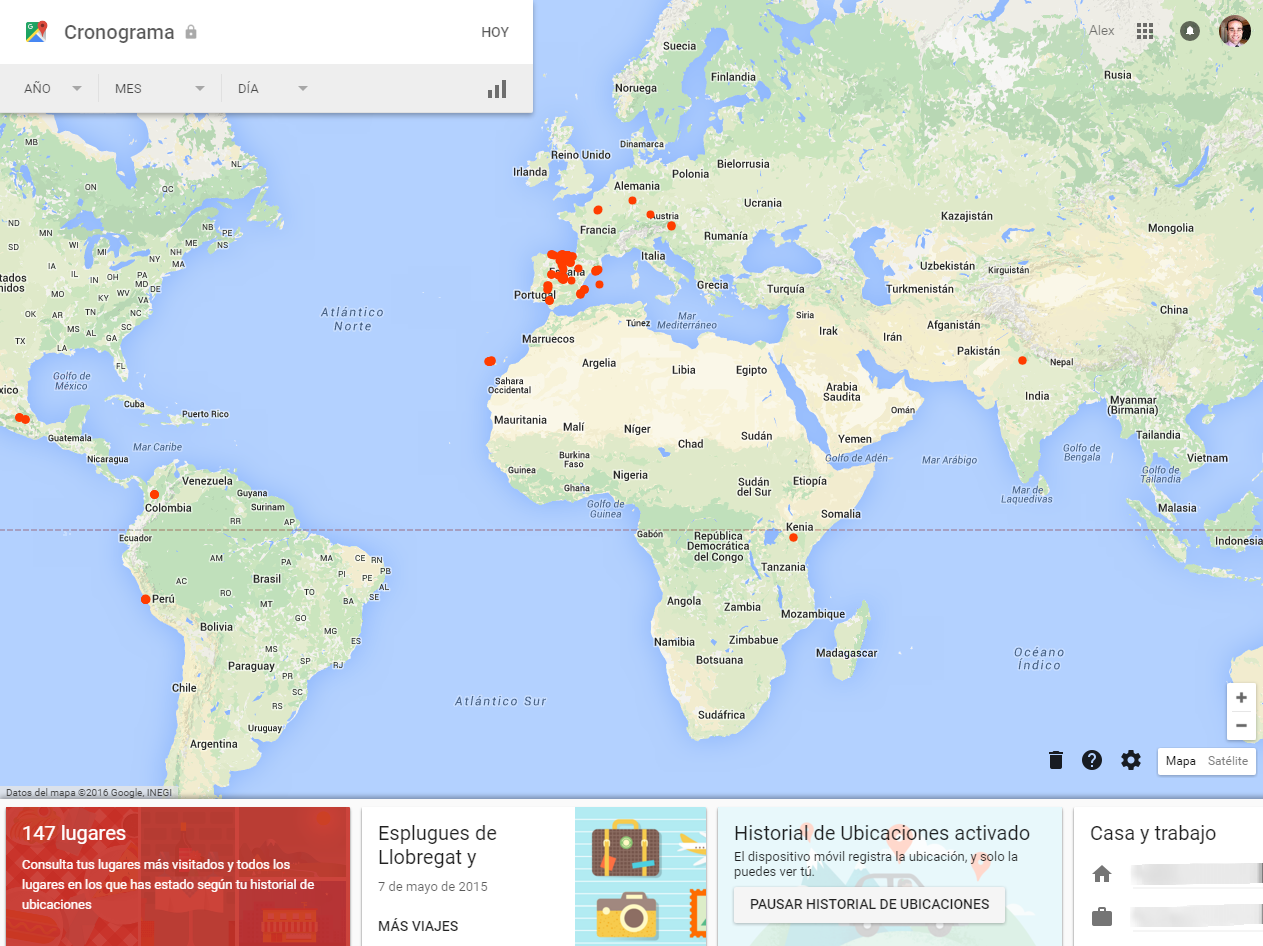
Hace unos años, comprábamos un GPS que nos costaba entre 200 y 300 € (mínimo). Hoy en día tenemos Google Maps y Waze. No nos cuesta nada poder usarlo, salvo la conexión a Internet… y los datos personales de por dónde nos desplazamos que es lo que les cedemos a cambio. No sé si alguna vez han probado a introducir en su navegador maps.google.com/locationhistory. A mí me sale esto (fijaros que incluso infiere donde trabajo y donde resido, que es el área que he difuminado):
Historial de localizaciones en Google Maps (Fuente: elaboración propia a partir de Google Maps)
Esto no es exclusivo de Google. Prueben en su dispositivo móvil. Por ejemplo, los que tienen un iPhone. Vayan en Ajustes, a Privacidad, luego a Servicios de Localización, y abajo del todo, les aparecerá un menú titulado «Servicios del sistema«. Miren cuántas cosas salen ahí… incluso el menú «Localizaciones frecuentes«.
Estos datos se los cedemos a cambio de un servicio, que, no me negarán, es bastante útil, nos ofrece una funcionalidad mejorada. Pero, también, en muchas ocasiones, se lo venden a terceros. Y puede entenderse; al final, de una manera más o menos clara, ya sabemos que Google lo hará, y además, deberá monetizar la gigantesca inversión que hacen para que podamos usar Google Maps apropiadamente.
¿Es esto bueno o malo? Responder esta pregunta siempre es complicado. Por eso a mí me gusta más responder en clave de costes y beneficios. Nada es gratis, como decía antes. Para obtener un determinado beneficio, tenemos que asumir un coste. Si el beneficio no compensa el coste que nos genera ceder los datos históricos de localización, entonces es un servicio que no debiéramos tener activado. Siempre se puede desactivar o comprar servicios de «anonimización» como www.anonymizer.com, que por menos de 100 dólares al año, nos permite anonimizar nuestro uso de servicios.
El caso del FBI vs. Apple ha abierto una nueva discusión en torno a la protección de la privacidad. Un dilema ético difícil de dirimir. ¿Tiene una empresa privada -Apple- que dar los datos de un usuario porque el interés público general -FBI- así lo requiere para la seguridad de los ciudadanos? Apple, de hecho, antepone la seguridad de sus usuarios, como si fuera un país más defendiendo sus intereses (con el tamaño que tiene, literalmente, como «si fuera un país»).
Este tipo de situaciones nos ha solido llevar a la creencia que el «Gran Hermano» de los gobiernos era un problema que no podíamos dejar crecer. Sin embargo, no sé si estoy muy de acuerdo con esta visión de que el «Gran Hermano» son los gobiernos. Me parece que incluso en muchos casos son proyectos «Small Data«. En la mayoría de los casos, los gobiernos, los ministerios del interio, no se fijan más que en metadatos en muchos casos de unos usuarios concretos, los que guardan una mayor probabilidad de cometer algún delito, por ejemplo. Como suelo contar cuando me preguntan por ello: «No creo que Obama tenga tiempo de leer mis documentos en Google Drive«.
El «Big Data» y donde realmente sí tienen muchos datos nuestros, es en el mundo de la empresa. En esta era digital donde dejamos traza de todo lo que hacemos (búsquedas, compras, conducciones, lecturas, etc.), alguien guarda y emplea esos datos. Y suelen ser empresas privadas. Y esto sí que debe ser de preocupación por todos nosotros. Y sí que debe ser algo que desde los gobiernos debiera «controlarse». O por lo menos, certificar su buen tratamiento.
Sin embargo, tengo la sensación la gente ignora que esto es así. En un paper de 2013 de los economistas Savage y Waldman titulado «The Value of Online Privacy«, sugerían que los humanos estamos dispuestos a pagar porque nuestros datos no sean recopilados por las apps. Es decir, lo decimos, pero luego no nos preocupamos por ello. ¿Pereza? ¿Dificultad? ¿Ignorancia? Por otro lado, nos contradecimos. En el paper «The value of privacy in Web search«, solo el 16% de los que participaron en la encuestas estarían dispuestos a pagar porque su navegación en la web fuera totalmente privada. En un reciente paper de dos investigadores de la Universidad de Chicago titulado «Is Privacy Policy Language Irrelevant to Consumers?«, aparece como solo una pequeña fracción de usuarios está dispuesta a pagar 15 dólares para detener la invasión de privacidad.
Todo esto, como ven, está generando muchas interrogantes y dilemas no siempre fáciles de responder. Esta nueva economía digital en la que pagamos con datos personales el uso de productos y servicios, ha hecho que los gobiernos -quizás tarde- comiencen a regular algunas cuestiones. La FCC -Federal Communications Commission o Comisión Federal de Comunicaciones-, ha estado trabajando hasta estos días en nuevas reglas que pone pequeños obstáculos a este uso de datos. Si bien solo aplica a las compañías de telecomunicaciones, no a las de Internet.
Entiendo que veremos muchos casos de demandas una vez que la gente comience a darse cuenta de muchas de estas cuestiones. Es solo cuestión de que como en los papers que antes comentábamos, la gente se vaya dando cuenta de ello, y lo considere un derecho fundamental. Ahí, y sin pagos por medio, entiendo que las personas sí que se mostrarían más conservadoras y garantes de su privacidad a la hora de ceder sus datos. Ya estamos viendo casos. Uno en el que se demandaba a Google por la lectura de emails que hace con Gmail (hubiera expuesto a Google a una multa de 9 billones de dólares), el software de reconocimiento facial que emplea Facebook y otros, que al parecer atentan contra las leyes estatales de Illinois. A sabiendas que la ley castiga con 5.000 dólares por violación de la privacidad, podría Facebook que tener que hacer frente a 30.000 millones de dólares de multa.
En esta economía digital, nuestra privacidad, los datos que generamos en el día a día son la nueva divisa. ¿Somos conscientes de ello? ¿Pagaríamos porque dejara de ser así? ¿El beneficio compensa el coste? Cuestiones interesantes que en los próximos años generarán casos y sentencias. La privacidad, otro elemento más que en la era del Big Data se ve alterado.
En esta era de la personalización, del consumidor exigente, una cosa que obviamos es que sí, las empresas saben más de nosotros que nunca. Y quieren saber cada vez más. Según el estudio The Talent Dividend, elaborado por la revista MIT Sloan Management Review y la empresa de software analítico SAS, basado en entrevistas a 28 ejecutivos de firmas internacionales y encuestas a 2.719 empleados, el 50% de las compañías asegura que entre sus prioridades está aprender a transformar los datos en acciones de negocio.
¿Sabemos realmetne lo que hacen las empresas con nuestros datos e información? ¿Cómo la protegen? ¿Qué hacen con ella? ¿La venderán? ¿Cumplen con lo que nos dicen? Datos que vamos dejando sin daros cuenta cada vez que hacemos una búsqueda en Google, cada vez que compartimos un tweet, un post, una fotografía en Instagram o un comentario en Facebook. Por poner solo varios ejemplos.
Cuando de forma voluntaria accedes a compartir datos con tus apps, parece de justicia, que el uso de esa información te traiga ciertos beneficios. De ahí, podemos decir que es importante que te digan qué harán con esa información. Por todo ello, aparecen las preocupaciones por la privacidad. En Europa, es algo que nos preocupa. Por eso también saber dónde dejamos esos datos: si es un proveedor americano, ¿está en Europa también? ¿o los manda para EEUU automáticamente?
Para resolver todas estas inquietudes y preguntas abiertas, el grupo de trabajo del artículo 29, un organismo consultivo de la Comisión Europea, se dedica a efectuar recomendaciones en materia de privacidad.
Grupo de Trabajo del Artículo 29 (Fuente: http://ec.europa.eu/justice/data-protection/article-29/index_en.htm)
El pasado 2014, elaboró una opinión (Dictamen 8/2014), sobre los riesgos a la privacidad de este mundo conectado. Esas líneas de reflexión, posiblemente generen regulaciones futuras, y se centraban en dos elementos: «privacy by design» y el «security by design«. ¿Qué es esto?
Básicamente, se trata de un enfoque que aboga por la privacidad y la necesidad de tener en cuenta la seguridad en el mismo momento del diseño de los objetos inteligentes. Es decir, en lugar de tener que hacer este ejercicio de protección y seguridad a posteriori, hagámoslo antes de fabricar los objetos.
Este enfoque está ganando especial relevancia ante el previsible auge de los objetos conectados a Internet. Es decir, el paradigma Internet of Things. Cuando estemos interaccionando a través de Internet con «todos» los objetos que nos rodean (el microondas, el coche, el teléfono móvil, el autobús, la tarjeta de crédito, etc.), obviamente, la cantidad de datos que vamos a generar va a ser aun mayor que la actual. Es por ello, que tenemos «Big Data» para rato. Pero también debemos tener preocupación por la privacidad de los datos que generamos, y sobre todo, hacerlo en un marco de seguridad.
Pues bien, este Grupo de Trabajo del artículo 29, habla del Privacy y Security by design como una forma de enfocar el diseño y desarrollo de los objetos conectados a Internet de los que nos rodearemos a futuro. Y me ha parecido especialmente relevante citar estas cuestiones debido a que el software que deberemos desarrollar para poner en valor esos datos, deberá cumplir estos principios también.
¿De qué estamos hablando? Básicamente, de la protección de datos y de aspectos relacionados como:
El Dictamen plantea tres escenarios donde se debe prestar especial atención:
Tecnología para llevar puesta (wearable computing)
Dispositivos capaces de registrar información relacionada con la actividad física de las personas
La domótica
Los objetos que recogen datos relacionados con la salud y el bienestar del ciudadano, pese, a ser anónimos en un principio, pueden revelar aspectos específicos de hábitos, comportamientos y preferencias, configurando patrones de la vida de las persona (con los consiguienres riesgos morales que puede suponer).
Recomendaciones de utilidad en el desarrollo de estándarestecnológicos en el ámbito del Internet de las Cosas (y así evitar problemas para el usuario a la hora de querer cambiar de un contexto a otro)
Alerta que el usuario puede perder el control sobre la difusión de sus datos si la recogida y el procesamiento de los mismos se realiza de manera transparente o no (la importancia de tener claro el marco donde serán tratados esos datos)
Manifestar claramente que la información personal sólo puede ser recogida para unos fines determinados y legítimos
Considerando estos aspectos antes de empezar el diseño y fabricación de un objeto, el dictamen asegura que evitaríamos muchos problemas y retos legales y éticos que tenemos en la actualidad.
Ya ven, de nuevo, que la era del Big Data, además de que nos vaya a dar mucho trabajo a futuro, también chocará con los marcos normativos. Por eso es importante también considerar enfoques tan novedodos como el «Privacy y Security by design«, y así evitar limitaciones de diseño y desarrollo a futuro, chocando con el ámbito jurídico.
Una de las cuestiones que más hemos tratado en nuestros últimos eventos tiene que ver con la transformación de diferentes modelos de negocio, industrias y organizaciones sobre la base de la introducción de la «economía del dato» o «tecnologías Big Data».
Estas realidades de transformación, es un aspecto que veremos en cada vez más industrias y sectores. El informe de Accenture «El Internet de las Cosas en la estrategia de los ejecutivos Españoles«, se recoge como el 60% de la alta dirección ve mucho potencial en el Internet of Things. Esto abre una enorme oportunidad para los datos, porque la sensorización de «nuestra vida, y los objetos que nos rodean«, obviamente tiene una capacidad de generación de datos descomunal. Pero en este mismo informe se recoge como se estima que se emplea menos del 1% de la información y los datos que se generan gracias al IoT.
Uno de los sectores con mayor potencial en dicho informe es el de los vehículos personales, con la inclusión de sistemas de diagnóstico a bordo que monitorizan los patrones de conducción para poder ofrecer pólizas a medida. La «personalización de la economía» llegando a otro sector más. De hecho, según el Informe Global de Automoción, El 82% de los conductores espera beneficios de los datos que genere su vehículo.
Dentro de la industria de los seguros, hablamos de las pólizas de vehículos, dada la transformación que está viviendo en los últimos años. Comencemos por EEUU, donde las cosas suelen ir más rápido que por otras latitudes y longitudes. Compañías como Allstate con su programa «Drivewise», State Farm con «Drive Safe and Save» y Progressive con «Snapshot», ofrecen ahora a sus clientes un esquema de relación basada en: yo monitorizo cómo conduces, y si te comportas bien acorde a unos parámetros conocidos, pagarás menos. Es lo que se ha venido a llamar «Usage-based insurance«. Como ya pagamos por el consumo que hacemos de electricidad (bueno, más o menos) o por la gasolina, pues eso mismo, pero en el sector asegurador. Una tendencia que cada vez veremos en más sectores.
El Big Data lo que introduce es la reducción de costes que habitualmente se generan por la asimetría de información. Como yo no sé si te vas a portar bien, por si las moscas, te cobro una póliza mayor. Para ello, las compañías aseguradoras te instalan un GPS que monitorizan patrones de conducción. Estos datos, que tú consientes ceder a la compañía, son, con una granularidad/frecuencia de muestro de entre 1 y 5 segundos:
Ubicación: latitud y longitud por donde te vas desplazando.
Grado de aceleración/desaceleración: km/h ganados o perdidos, y su comparación en términos de segundos para saber la brusquedad
Vector de giro: fuerzas G, que mide en cierto modo la fuerza del giro y su grado de cambio para detectar brusquedad, agresividad, etc.
Hora y día: sello de tiempo, para saber sobre qué horas y días te desplazads
Con estos datos (que seguramente tengan más), podemos saber, para un conductor dado:
Cómo de brusco conduce: aceleración/desaceleración (el acelerómetro que incorpora lo permite)
Cómo gira: fuerzas G de giro para saber su agresividad en las mismas
Lugares por los que ha pasado: ¿lugares seguros? ¿carreteras principales o secundarias? etc.
Carreteras que más frecuentemente emplea (ya sabemos que las secundarias tienen una tasa de siniestralidad superior)
Horas y días de más frecuencia de conducción, para saber si conduce en «rush hours» u «horas pico» (por ejemplo, ya sabemos que a las noches, y en carreteras secundarias, el índice de mortalidad y riesgo es también mayor)
Velocidad y estadísticos básicos: media, moda, mediana, máxima, mínima (y poder sacar así patrones)
Respeto a las señales de circulación: dado que sabemos por dónde se ha movido, y tenemos datos cartográficos con las limitaciones de velocidad integradas, podemos sacar un «score de buena conducta«, incluso con «grados de cumplimiento» para saber si respeta las normas de circulación.
etc.
Según he podido entender, basan su modelo analítico de scoring en estos datos, de manera que obtienen un «score de conductor«. Un poco en la línea de lo que es disponer de un «score crediticio» (como ya hablamos aquí). Este score permite que con una fórmula de ahorro, podamos decirle a cada conductor cuánto le vamos a cobrar dado su riesgo de conducción. Este modelo de «Pay How You Drive» (PHYD) abre muchas nuevas puertas y seguro vemos recorrido en todo ello próximamente.
Score de conducción (Fuente: https://i.ytimg.com/vi/gj-RO5FE5q4/maxresdefault.jpg)
Obviamente en todo esto, no podemos dejar de lado el trade-off entre «Ahorro» vs. «Privacidad». ¿Qué riesgos pueden existir? Que se sepa dónde estemos en todo momento (y el consiguiendo y manido «Gran Hermano»), la «Third-party doctrine» (si cedo los datos a un tecero, no puedo luego reclamarlos de vuelta) y que esto de la información despersonalizada es un mito. Ahora bien, veo «ahorros» no solo individuales, sino globales:
Cuando una persona se autodiagnostica, gana en conciencia, por lo que es más probable que cambie de comportamiento. En este punto, y con el objetivo de hacer algún contraste, sería interesante ir perdiendo endogamía en la muestra (actualmente todos los conductores que en EEUU están contratando estos seguros son precisamente los que ya mejor conducían…). Aunque también es cierto que si se acaban metiendo todos «los buenos», los que se quedarían fuera, ¿entiendo reaccionarían? Muy interesante esta línea desde el punto de vista sociológico.
Si el «score de conducción» fuese elevado a «Dato público de interés general», podríamos mejorar mucho el sector. Si las compañías aseguradores debieran pasarse ese dato a través de un «Registro Central del Estado«, mucho mejoraría. Como ya funciona para evitar el fraude, por ejemplo. De hecho, entiendo, el primer interesado en esto sería el Ministerio del Interior.
Hacer coches y carreteras más seguras, dado que sabríamos cómo se comportan, en agregado los conductores que pasen por determinados puntos. Esto, seguro que a la Dirección General de Tráfico le puede interesar.
Se podría llegar a acuerdos con comercios habitualmente relacionados con el vehículo (estaciones de repostaje, compra de productos en tiendas, grandes centros comerciales a los que habitualmente nos desplazamos en vehículos, estaciones de radio, etc.) para ofrecer descuentos a comercios asociados o los que quieran asociar su branding a determinados patrones de conducción.
etc.
Hay factores de riesgo al volante que dejamos de lado (micrófonos para el ruido, cámaras para la mirada, copiloto -según un estudio de la Fundación Línea Directa la mujer al volante y el hombre como acompañante es la fórmula de menor riesgo-, etc.), pero quizás veamos pronto todo esto integrado también. Haciendo un rápido Googling para España, he dado con Next Seguros, compañía aseguradora que basa su modelo de negocio en mucho de lo que aquí hemos explicado. En Rastreator salen también algunas otras genéricas que también ofrecen estas posibilidades.
Por último, nunca olvidar del plano legal y la importancia del «Compliance Officer» y garantizarnos que todo esto es posible (a sabiendas que EEUU no es España/Europa, y que la nueva Directiva de Protección de Datos está a la vuelta de la esquina).
Ya ven que esto del «Usage-based insurance» abre muchas cuestiones a reflexionar y transforma muchos elementos de un sector (modelo de negocio, tarificación, plano legal, etc.). Una más, entre las industrias, que el Big Data está dotando de nuevas capacidades.