El 29 de diciembre de 2020, Patricio Moreno (Partner – Director LATAM Datalytics) entrevistó a Owen Dempsey, Technology Head Latam South (Argentina, Chile, Bolivia, Paraguay, Uruguay) de Anheuser-Busch InBev (la mayor productora de cerveza del mundo con marcas tan conocidas como Coronita o Franziskaner).
Todas las entradas de: Álex Rayón
Análisis de los textos de los programas para el 10 de noviembre: elecciones en españa
(Elaboración realizada por nuestro estudiante Alexander Seoane, de la 5ª promoción del Programa de Big Data y Business Intelligence en nuestra sede de Bilbao)
¿Sin tiempo para leer los programas o ver los debates electorales? Un análisis de texto con Tidytext , ggplot e igraph sobre los programas de cada partido puede ayudar a hacernos una idea de las grandes cuestiones en liza en 1 minuto. @ciudadanos @maspais_es @pp @psoe @unidaspodemos @vox
El MIT creará una facultad de Inteligencia Artificial
Dos noticias de estos últimos días han llamado mi atención. Por un lado, hemos sabido que en el Instituto de Tecnología de California (Caltech) la asignatura con mayor número de estudiantes, a pesar de ser optativa, vuelve a ser Machine Learning. Los estudiantes provienen de 23 diferentes especializaciones (fiel a la tradición americana de elección de asignaturas a lo largo de la carrera de especialización). Aquí el tweet que lo cuenta:
It’s official: #MachineLearning course by Professor Yaser Abu-Mostafa is (again) the biggest class at @Caltech, undergraduate or graduate in all departments, in spite of being an elective offered every year. The students come from 23 different majors!#DataScience #AI #BigData
— Caltech Telecourse (@telecourse) October 19, 2018
Por otro lado, y de bastante más envergadura, el MIT anuncia que va a crear una nueva facultad para trabajar la Inteligencia Artificial (IA). Un total de 1.000 millones de dólares serán invertidos. Tiene sentido que sea el MIT nuevamente, que ya tuvo mucho que ver en el nacimiento de esta disciplina que trata de desarrollar métodos que aprendan del comportamiento de los datos para luego poder generalizar. Es ya la mayor inversión realizada hasta la fecha por una institución académica en el campo de la IA.

Como se puede leer en la noticia, el MIT está diseñando la facultad mezclando inteligencia artificial, machine learning (métodos de aprendizaje sobre datos) y la propia ciencia de datos. Pero, no se quedará ahí, dado que pretende mezclarlo con otras áreas de conocimiento. Me han resultado especialmente reveladoras las palabras pronunciadas por el Rector del MIT, Rafael Reif, al hacer el anuncio:
“Computing is no longer the domain of the experts alone,”
“It’s everywhere, and it needs to be understood and mastered by almost everyone.”
De nuevo, la misma idea expresada anteriormente: los datos están transformando el mundo y sus diferentes contextos, por lo que se vuelve necesario conocer las principales técnicas para poder hacer uso de la capacidad organizativa, transformadora y de soporte que traen los métodos de gestión basados en modelos analíticos. Como dice el Rector, no es un campo propio solo de la ingeniería o la informática, sino que empieza llegar a nuevos terrenos. La inteligencia artificial, con la llegada de los grandes volúmenes de datos, ha vuelto a escena para transformar el mundo.
Otro de los aspectos reseñables de este anuncio es que introducirán la ética en sus programas de estudio. Entender el potencial impacto que tienen estos modelos inteligentes sobre los diferentes planos de la sociedad es importante. Especialmente, para los que adquirirán esas capacidades de transformación. No solo en política, sino en salud, educación, servicios sociales, etc., puede tener un impacto donde la ética no quede bien parada si no queda explícitamente reflejada. Los humanos creamos la tecnología, por lo que debemos enseñar que a la hora de hacerlo, nuestros sesgos y prejuicios debemos dejarlos de lado y hacer tecnología neutra o bien compensada.
Esto último ha vuelto a salir a escena estos días con la noticia en la que conocíamos que el algoritmo que Amazon usaba para seleccionar a sus trabajadores y trabajadoras discriminaba a las mujeres. Tarde, pero Amazon ya ha prescindido de él. Este lamentable hecho), no pensemos que existe sólo contra las mujeres y en el contexto laboral. Se pueden dar en cualquier espacio que tenga esos sesgos en el mundo real, como bien explicaba este artículo de Bloomberg.
Hace unos meses escribí un artículo sobre los movimientos que se estaban dando en diferentes países para el diseño y la creación de Ministerios de Inteligencia Artificial. Vemos como otro de los agentes sociales más relevantes para entender las consecuencias de las máquinas inteligentes, las universidades, también se están moviendo. Es interesante seguir esta tendencia para saber hasta dónde podremos llegar. ¿Veremos estas tendencias pronto por Europa?
Como dije en ese artículo:
La intencionalidad del ser humano es inherente a lo que hacemos. Actuamos en base a incentivos y deseos. Disponer de tecnologías que permiten hacer de manera automatizada un razonamiento como sujetos morales (simulando a un humano), sin que esto esté de alguna manera regulado, al menos, genera dudas. Máxime, cuando las reglas que gobiernan esos razonamientos, no las conocemos.
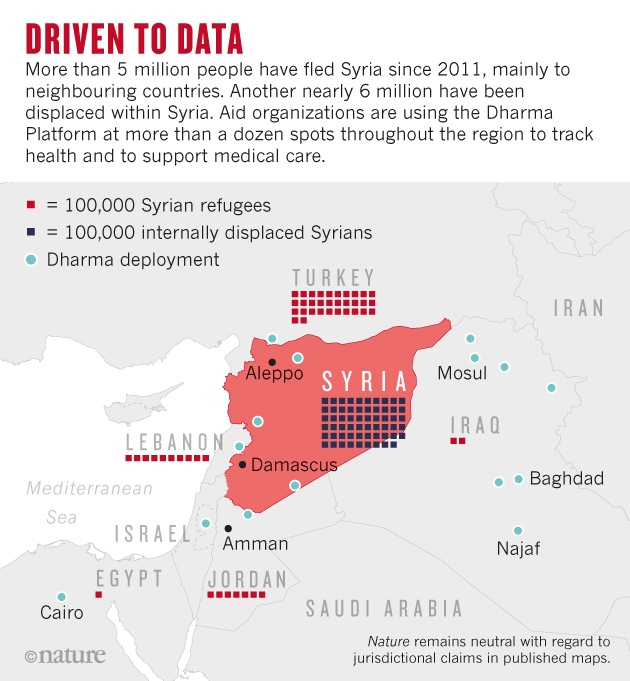
La ayuda humanitaria internacional descubre el poder del dato: la plataforma Dhalma en la crisis de Siria
(Artículo escrito por Elen Irazabal, alumni de Deusto Derecho y alumna de la II Edición del Programa en Tecnologías de Big Data en nuestra sede de Madrid)
La revista Scientific American el pasado octubre de 2017 hacía reflejo de la siguiente historia: la epidemióloga Jesse Berns había estado trabajando en conflictos humanitarios desde el año 2006. En el año 2013 y durante su estancia en Iraq, realizó un estudio sobre el estado de salud de los refugiados. Ella misma había creado un excel con los datos que había recabado desde su puño y letra, uniéndolos con otros datos y así generar un informe. Tal proceso le costó 5 meses, cuando el informe se realizó, los datos ya habían quedado obsoletos. Asimismo, en el año 2015 pudo experimentar cómo durante la crisis del ébola en el África Occidental, gastaron mucho dinero intentando encontrar la manera de transmitir datos de pacientes moribundos sin acceso a conexión wifi.
Es ahí cuando, junto con un científico de datos, Michael Roytman, crearon la plataforma Dharma: una plataforma que opera offline, capaz de transmitir información mediante bluetooth y resistente a los bombardeos. Está pensado para que profesionales sin una base técnica puedan adaptar la plataforma a sus necesidades.
La revista también cuenta, entre otras experiencias, la última prueba de Dharma que se ha realizado en Siria: un médico que comenzó a meter historiales médicos de sus pacientes para observar los progresos a medida que comparte los datos con sus compañeros de Amman.
Son más de 5 millones de personas huidas de Siria a países vecinos, otros 6 millones de desplazados dentro de Siria, las organizaciones humanitarias utilizan Dharma en más de doce puntos clave a lo largo de la región para poder recabar información sanitaria y proporcionar ayuda médica. [1]
El éxito de Dharma refleja el poder de la información en tiempos de guerra, desastres naturales o cualquier crisis humanitaria que surge a lo largo y ancho del globo. El principal problema a los que se enfrentaban las organizaciones era la obtención del dato fidedigno y la obtención de una infraestructura tecnológica capaz de aprovechar los datos de manera eficiente.
Si tuviésemos que describir, un antes y un después en la cooperación internacional, sería el avance tecnológico que capacita a la información que proporcionamos los individuos en la en forma de valor de dato. Las organizaciones son capaces de dar un servicio individualizado en acontecimientos de carácter global. Este hecho no tiene precedentes en la historia, donde las organizaciones como la ONU operan como actores más allá de los estados para crear puentes y alianzas (muy discutibles en muchos casos) entre naciones. Eran la fuente de información y canal de cooperación. Sin embargo, la tecnología desde todos sus aspectos ha recortado las distancias entre naciones diversas. Desde las redes sociales al propio lenguaje de programación, no existen muros.
Y ahora, con el análisis de datos, las naciones podemos responder con una rapidez y precisión que escapa a las decisiones políticas. Por eso, también la ONU ha descubierto el Big Data y ha incorporado a su Agenda de Desarrollo Sostenible, “Big Data para el Desarrollo Sostenible”. [2]
El futuro es del dato, no sólo como economía del dato, sino en todo lo que engloba las ciencias sociales con especial hincapié en las acontecimientos internacionales que tantos estudios han ocupado y tantas páginas de acuerdos internacionales han cubierto.
[1]https://www.scientificamerican.com/article/out-of-the-syrian-crisis-a-data-revolution-takes-shape/
[2]http://www.un.org/en/sections/issues-depth/big-data-sustainable-development/index.html
Big Data: la posición más difícil de cubrir en España
El pasado 7 de marzo, Cinco Días, publicaba esta noticia: «Big data, el perfil más difícil de cubrir en España«. Según el artículo y sus fuentes, las profesiones asociadas con las tecnologías de Big Data son las más difíciles de cubrir. Su fuente principal es el informe EPYCE 2017: Posiciones y Competencias más demandadas, elaborado por EAE Business School junto con la Asociación Española de Directores de Recursos Humanos (AEDRH), la CEOE, el Foro Inserta de la Fundación Once y Human Age Institute.
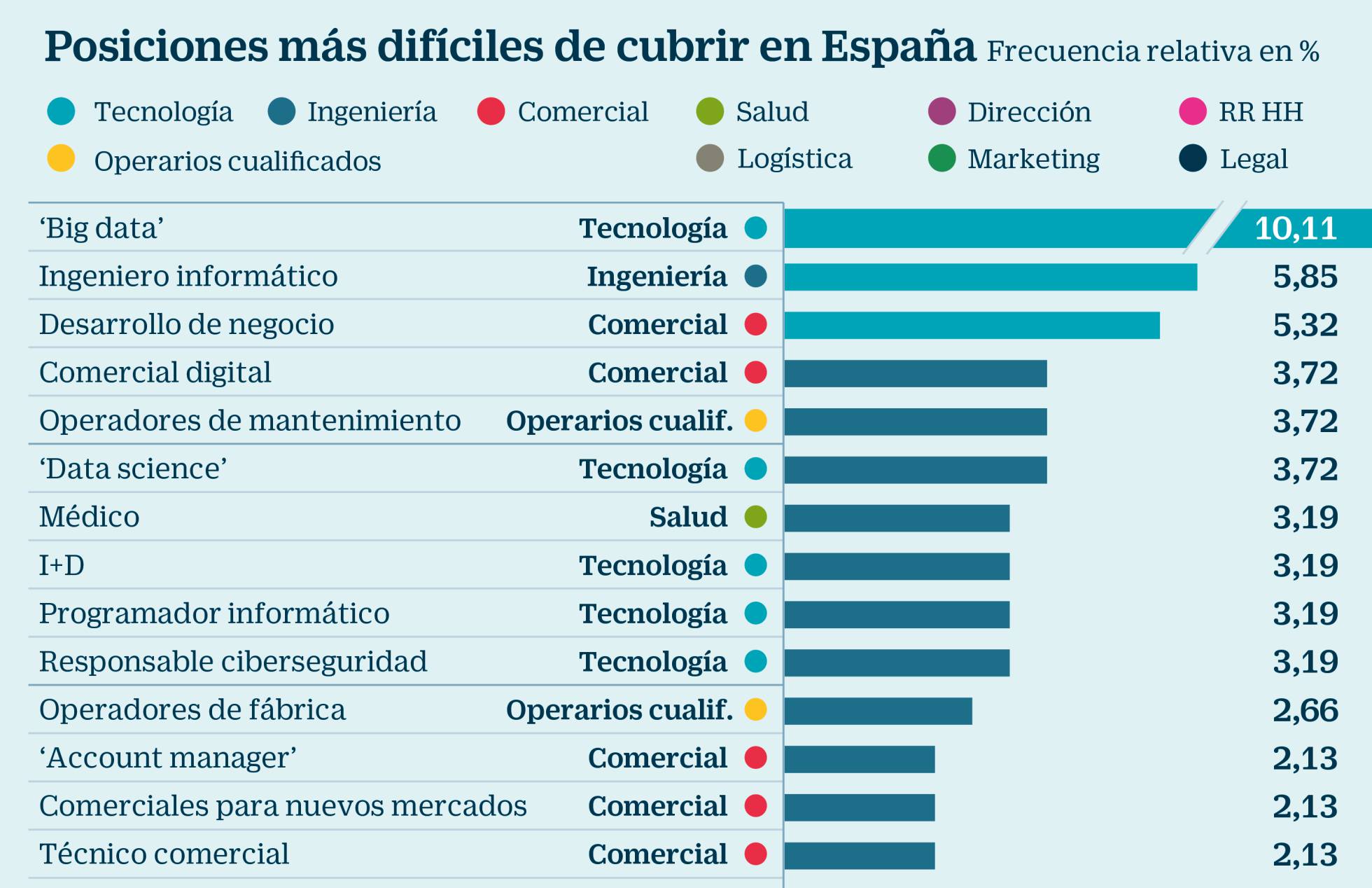
En un blog como éste, donde hablamos tanto del paradigma del Big Data y sus múltiples implicaciones en nuestras sociedades, naturalmente, no podíamos dejar sin sacar esta noticia. Llevamos años ya formando perfiles de Big Data en nuestros Programas de Big Data en Bilbao, Donostia y Madrid.
El informe original contiene aún más información. Aspecto que recomiendo revisar, para que se entienda bien no solo la metodología, sino los contenidos (datos) analizados. Miren por ejemplo esta gráfico que adjunto:
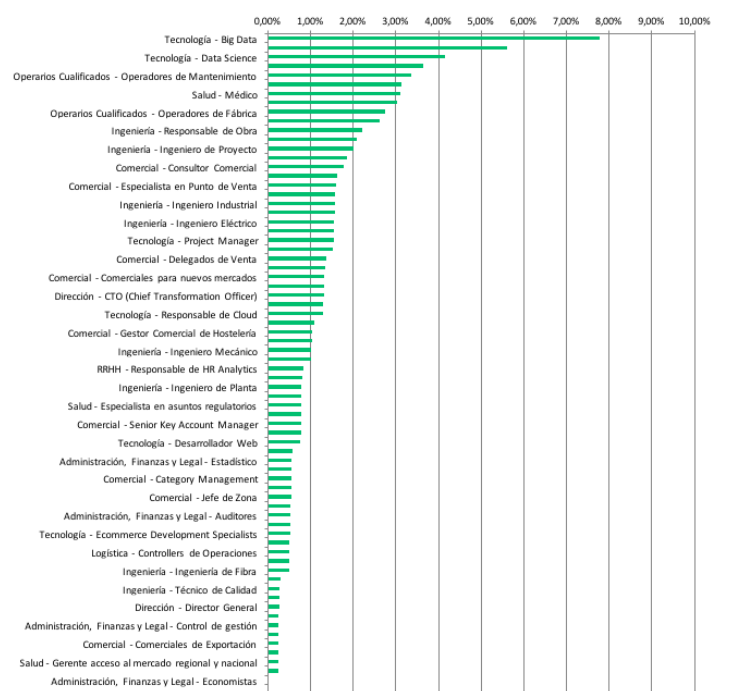
Con un nivel de detalle mayor, lo que vemos es que no solo la parte tecnológica (que siempre está en el top de los ranking de bajo desempleo), sino también la ciencia de datos (que son nuestras dos patas fundamentales en nuestros programas), son las más demandadas. En general, hay numerosas profesiones técnicas demandadas en todo el ranking y el informe. Lo cual nos viene a confirmar que efectivamente estamos viviendo una transformación tecnológica y digital en múltiples planos.
Lo que parece que viene a confirmar este informe es que estamos viviendo cierta brecha entre los perfiles que demandan las empresas y lo que realmente se dispone luego en el mercado de trabajo. Parece real esa velocidad a la que se está efectuando esta transformación digital de la sociedad, que está provocando que muchos perfiles no puedan seguirla, y no les dé tiempo a actualizar sus competencias y habilidades. El Big Data, la revolución de los datos, parece que ha venido para quedarse.
No obstante, en relación a todo esto, creo que cabría introducir tres elementos de reflexión. A buen seguro, a cualquier lector o lectora de estas estadísticas, le interesará conocer qué hay más allá de estas gráficas. Básicamente, porque la gestión de expectativas laborales en los programas formativos, creo que debe caracterizarse por la honestidad, para que luego no produzca frustraciones. Estos tres puntos son: (1) Descripción de «supermanes» y «superwomanes» en los puestos de trabajo de las empresas; (2) el concepto «experiencia» en las organizaciones; (3) el talento cuesta dinero.
En relación al (1), darse una vuelta por Linkedin suele ser muy ilustrativo a estos efectos. Las empresas, cuando buscan perfiles «de Big Data» (así en genérico y abstracto), suelen hacerlo solicitando muchas habilidades y competencias que me parece difícil que lo cubra una misma persona: conocimientos de programación (R, Python, Java, etc.), conocimiento de los frameworks de procesamiento de grandes volúmenes de datos y sus componentes (Spark y Hadoop, y ya de paso Storm, Hive, Sqoop, etc.), que sepa administrar un clúster Hadoop, que sepa cómo diseñar una arquitectura de Big Data eficiente y óptima, etc. Una persona que en definitiva, dé soporte a todo el proceso de un proyecto de Big Data, desde el inicio hasta el final. Este enfoque es bastante complicado de cubrir: para una persona manejar todo eso es realmente complicado, dado que no solo los códigos de pensamiento, sino también las habilidades, no suelen estar relacionadas.
En cuanto al (2), que se pida para estos puestos experiencia, me parece un poco temeroso. Estamos hablando de un paradigma que irrumpe con fuerza en 2013. Por lo que estar pidiendo experiencias de más de 2-3-4 años, es literalmente imposible de cubrir. Y menos en España donde todavía no hay tantas realidades en proyectos de Big Data como se cree. ¿Quizás la falta de cobertura de vacantes tenga que ver precisamente con esta situación? Por ello sería bueno saber realmente qué es lo que no están encontrando: ¿el puesto necesario? ¿el puesto definido por las empresas? ¿las expectativas mal gestionadas? Quizás sería bueno, y los empleadores bien saben que siempre les digo, que la formación es un buen mecanismo para poder prescindir de este factor de experiencia. Ahora mismo estamos colaborando con importantes empresas y organizaciones que están formando a varios perfiles a la vez porque son conocedores del límite de la experiencia del que hablamos.
Por último, en cuanto al (3). Hay una expresión inglesa que me gusta rescatar cuando hablo de esto: «You get what you pay«. Una expresión muy común también últimamente en el sector tecnológico. No podemos pretender pagar salarios bajos y que luego tengamos esos supermanes y superwomanes que decía anteriormente. Tenemos que ser coherente con ello. Nuestro conocimiento tecnológico, el talento técnico que formamos en España, está muy bien valorado en muchos lugares de Europa (Dublin, Londres, Berlín, etc.) y el mundo (San Francisco, New York, Boston, etc.). Es normal que en muchas ocasiones este talento se quiera ir al extranjero. ¿Pudiera estar aquí también parte de la explicación de la dificultad para cubrir puestos?
Las políticas de privacidad en internet: contra el paternalismo europeo
(Artículo escrito por Elen Irazabal, alumni de Deusto Derecho y alumna de la II Edición del Programa en Tecnologías de Big Data en nuestra sede de Madrid)
Anteriormente en este blog, habíamos resaltado la postura proteccionista de la Unión Europea en la RGPD y la desconexión entre la protección de datos y la privacidad.
El carácter de derecho fundamental de la protección de datos personales, pone en jaque la convivencia con otros derechos como por ejemplo, la competencia económica dentro del seno de la Unión Europea.
Este hecho se refleja en el posicionamiento de la Unión en cuanto a las condiciones que la ley establece en la formación del consentimiento del interesado: toda manifestación de voluntad libre, específica, informada e inequívoca por la que el interesado acepta, ya sea mediante una declaración o una clara acción afirmativa, el tratamiento de datos personales que le conciernen”. Digamos que la variedad principal es la eliminación del consentimiento tácito.
Sin embargo, y como veremos a continuación, esta novedad no parece que cumpla con el objetivo del Reglamento en devolver al ciudadano el control de sus datos.
En primer lugar, hasta el día de hoy, prácticamente nadie se lee las políticas de privacidad. Al fin y al cabo, las misma están redactadas en un lenguaje jurídico nada aterrizado al ciudadano y el coste de invertir tiempo en entenderlos sigue siendo con la RGPD, alto. Por otra parte, el entender un texto de privacidad no implica comprender el alcance de la vida de los datos personales en la red ni que el ciudadano, descubra el poder de su privacidad a través de un click.
En segundo lugar, la ley no resuelve el consentimiento en los casos de asimetrías de poder frente a los servicios de las gigantes tecnológicas como Google o Facebook, ni en aquéllos casos que se consiente la cesión de datos en aras de recibir un servicio que sin otro modo no se logra. Muy en contrario, el Reglamento restringe la competencia al eliminar la privacidad como motor entre ofertantes en el mercado, puede causar un incremento en el precio e incluso restringir el acceso a datos de consumidores en el mercado. Siendo las principales perdedoras las start ups que aún no disponen de los mismos.
En tercer lugar, tampoco tenemos alternativas a los Estados actuales proclives a utilizar la seguridad nacional y el interés público como justificación de utilización de datos para su propio beneficio. Incluso, en casos como en brechas de seguridad por parte de las empresas, el Estado obtiene acceso legalizado a los datos.
En definitiva, el Reglamento de manera contra-producente restringe la competencia y crea barreras de entrada a las start-ups que podrían desestabilizar a las gigantes bajo políticas de privacidad (o otros métodos) más atractivas. No será la ley en última instancia quién otorgue la solución, sino que será la tecnología a través de sus métodos innovadores quien se adapte.

Lenguaje R: herramienta potente y gratuita para la inteligencia de negocio – Ejemplo de análisis de texto
(Artículo escrito por nuestra alumna Olatz Arrieta, de la 3ª promoción del Programa de Big Data y Business Intelligence en Bilbao)
Después de un año de duro trabajo, termino el Programa de Big Data y Business Intelligence impartido por la facultad de ingeniería de la Universidad de Deusto. A lo largo de este tiempo, hemos aprendido muchísimo de las múltiples facetas de este concepto tan amplio que es el “Big Data”, pero, sin duda, uno de los mejores y más prácticos decubrimientos ha sido el entorno–lenguaje “R”.
R es un lenguaje superversatil, gratuito y con un soporte “open” impresionante en internet (por supuesto en inglés), que te permite encontrar siempre solución, una paquete desarrollado y scripts de ejemplo, para cualquier necesidad que te encuentres en un proyecto. Yo, en este tiempo en el que me he podido empezar a asomar a este universo de posibilidades, lo he utilizado en prácticas de casos reales para distintos usos:
- Hacer calidad y manipulación de datos, eliminando las limitaciones de volumen que tenemos con herramientas habituales como Excel, y utilizando funciones que, en un solo paso, realizan operaciones que de otra manera supondrían numerosas pasos y tablas intermedias.
- Aplicar modelos de predicción (regresión, clasificación) y descripción (clustering, asociación, correlación,..) a importantes volúmenes de datos para extraer conclusiones relevantes y no inmediatas.
- Pasar información de un soporte-formato a otro de manera sencilla para poder importar o exportar desde o hacia distintas fuentes.
- Hacer tratamientos de texto: palabras key, nubes de palabras o análisis de sentimiento de cualquier texto, incluso de páginas web o RRSS (facebook, twitter,..)
Esta última aplicación de análisis de texto, ha sido el objeto de mi último proyecto de trabajo en el máster, cuyo objetivo era practicar con algunas de las herramientas que R tiene para estos cometidos.
Decidí analizar los textos de los discursos de navidad del Lehendakari y del Rey de España en diciembre 2007 y diciembre 2017. Quéría observar qué diferencias y evolución ha habido entre los dos perfiles en estos 10 años. Tras la correspondiente limpieza y adecuación de los textos, por ejemplo sustituyendo ñ por gn, eliminando tildes, poniendo en minúsculas todo, igualando conceptos similares como democracia – democrático/a para poder observar mejor su peso, etc. muestro un ejemplo de algunos de los resultados obtenidos
Las palabras que no faltan en ninguno de los discursos, estando presentes en todos, más de 2 veces, son las siguientes:
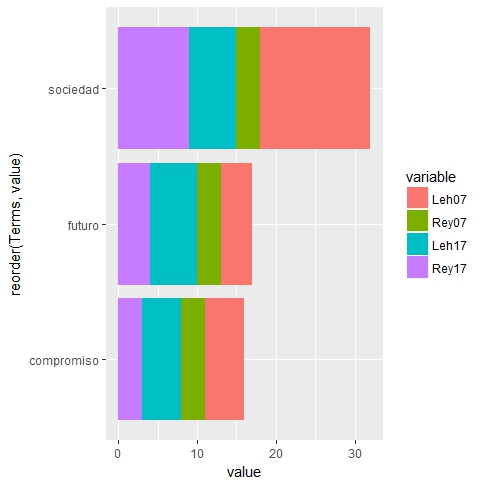
Las 20 palabras más repetidas en cada discurso, y su frecuencia de aparición a lo largo del mismo, son las siguientes:
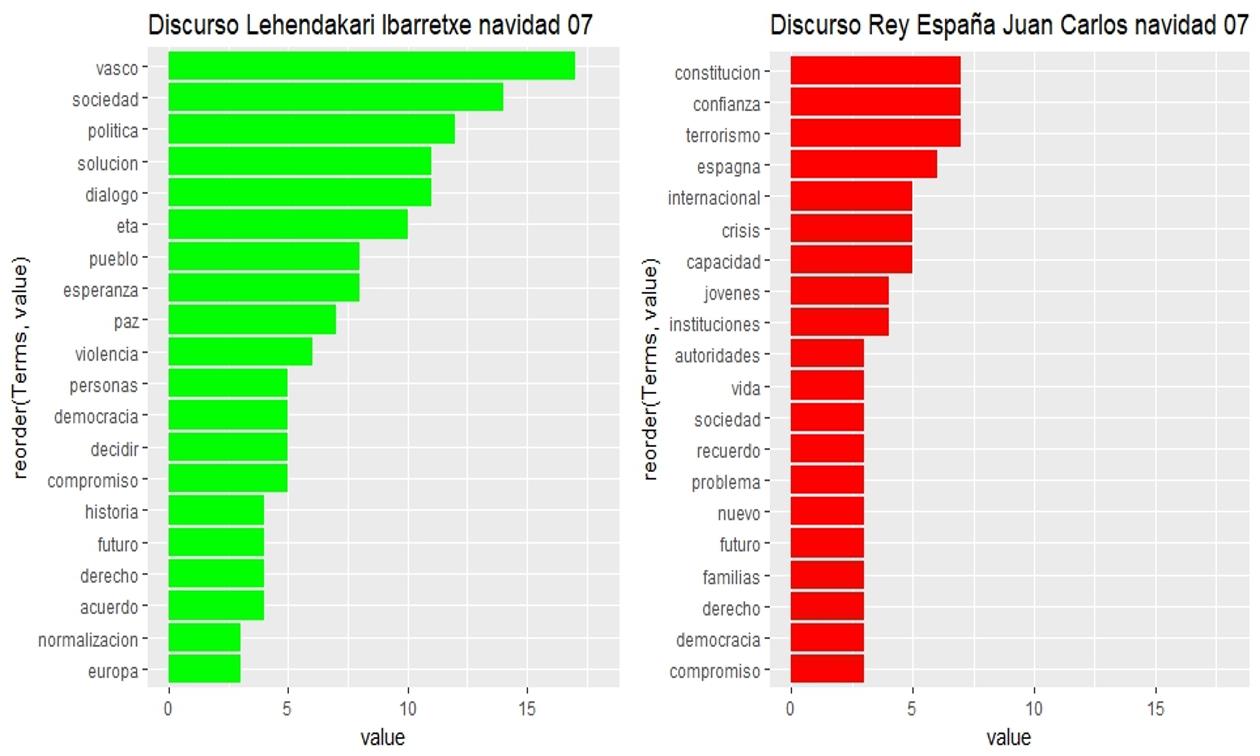
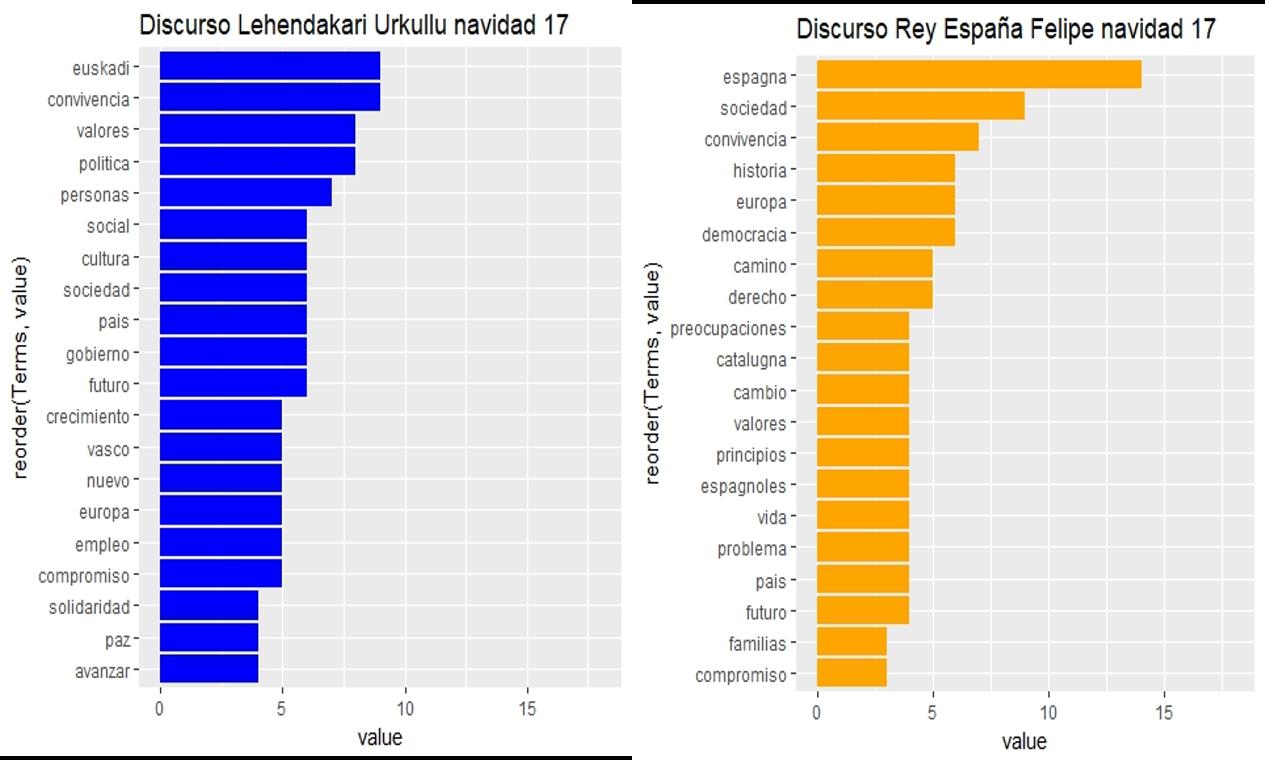
Sin ánimo de ser exhaustiva ni realizar valoraciones, destaco algunas observaciones sencillas que se pueden extraer como ejemplo:
- El Lehendakari Ibarretxe en 2007 ha sido sin duda el más reiterativo en los conceptos clave de su discurso ya que presenta claramente una frecuencia más alta en mayor número de palabras que los demás.
- En 2007 el Lehendakari repetía la palabra ETA mientras que el Rey usaba “terrorismo” y la temática “terrorismo” ha perdido peso en 2017
- En 2017 ambos dirigentes presentan en sus primeros puestos de reiteración, sus ámbitos territoriales (Euskadi, España) y aspectos ligados a la convivencia, sociedad o personas.
- En 2017 “Cataluña” no es mencionada de manera relevante por el Lehendakari y sí por el Rey que destaca también otras palabras ligadas a este asunto.
- La palabra “constitución”, principal argumento del discurso del Rey en 2007, desaparece de los discursos en 2017, siendo sustituida por conceptos más “soft”como democracia, derecho, principios,…
- La “política” es claramente una preocupación de los 2 Lehendakaris, mientras que no es destacada por los Reyes de España.
- La palabra “paz” la repiten ambos Lehendakaris y no los reyes, y la palabra “vida” a la inversa, está muy presente en los discursos de los reyes pero no de los Lehendakaris.
Esté hincapié en determinados conceptos se muestra más graficamente si elaboramos las NUBES DE PALABRAS, resultantes de seleccionar los términos que cada gobernante ha utilizado en más de 6 ocasiones a lo largo de sus discursos. Los tamaños y colores de letra representan pesos de frecuencias relativas dentro de cada discurso:

Se observa un distinto estilo de comunicación entre los dirigentes españoles y vascos. Los lehendakaris presentan un estilo en el que abundan los términos muy reiterados, mientras que en el caso de los reyes, éstos concentran la insistencia en menos términos.
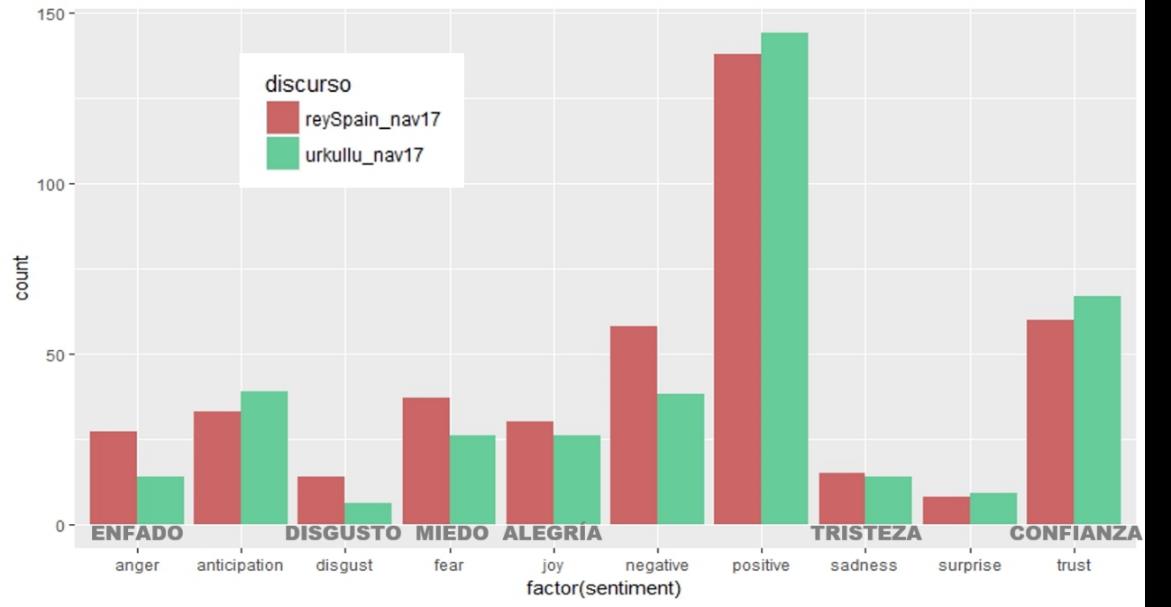
Por último, he querido hacer una pequeña prueba del funcionamiento de las herramientas de análisis de sentimiento. R dispone de diversos paquetes para ello, yo he usado Tidyverse y Tidytext, que presentan 3 lexicons que realizan una valoración “emocional” de los sentimientos que teóricamente generan las palabras utilizadas. Los lexicones son en inglés, por lo que he traducido directamente con google (R dispone también de paquetes específicos de traducción que utilizar APIs por ejemplo de microsoft, pero no he tenido tiempo de probarlos) los discursos del 2017 y, sin realizar ninguna revisión de la calidad de la traducción (seguramente habría que refinar muchas expresiones y términos), le he pasado los diccionarios lexicon de BING y NRC a cada discurso, para observar qué tipo de emociones provoca cada uno.
He aquí el resultado resumido del peso de cada sentimiento en los discursos de 2017:
Por último, utilizando el lexicon de AFINN que valora numéricamente las palabras entre -5 y +5 según la negatividad o positividad de sentimientos generados, el resultado final es el siguiente, expresado en los correspondientes histogramas de frecuencia de presencia de cada tipo de valor emocional:
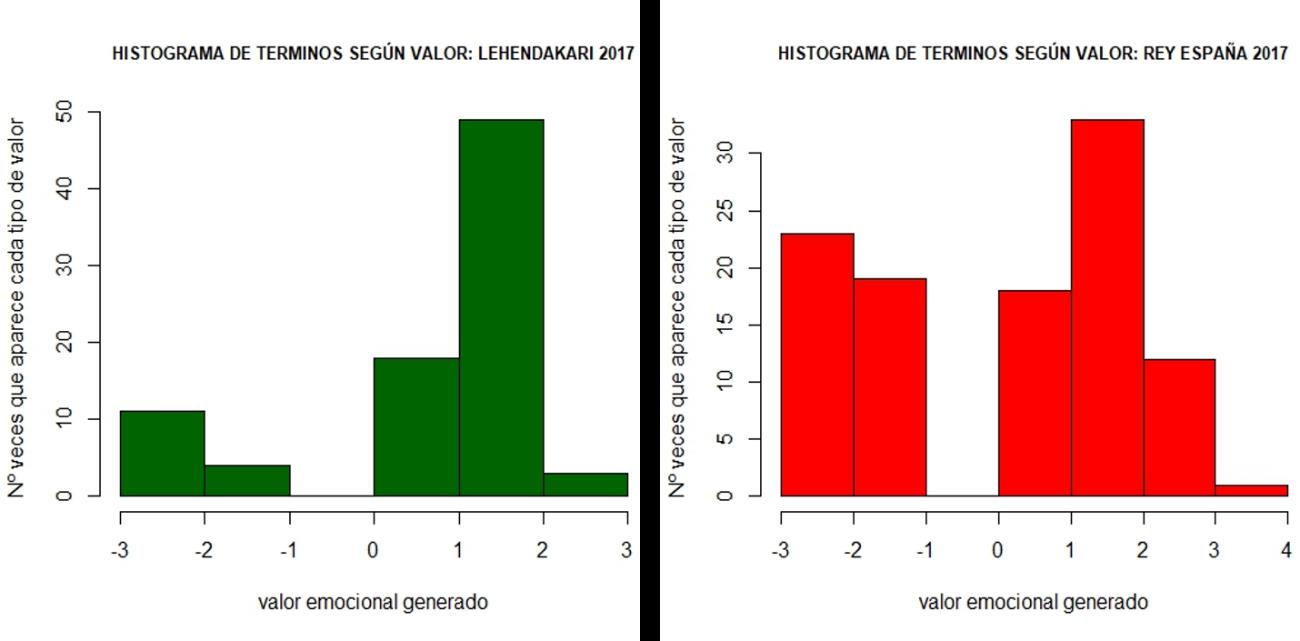
Se observa que el discurso del lehendakari se encuentra sesgado hacia la positividad mientras que el del Rey de España presenta más valores extremos, lo que resulta en un valor “emocional” medio de +1,06 sobre 5 en el caso del lehendakari y de un 0,49 sobre 5 en el caso de el Rey, resultados que corroboran el obtenido en la clasificación de términos anterior.
En resumen, que R es una herramienta que, una vez realizado el esfuerzo inicial imprescindible para adquirir la competencia mínima, presenta un enorme potencial de aplicación a casi cualquier necesidad o problema de análisis de datos que a una empresa se le pueda presentar, siendo un aliado muy interesante y recomendable para el desarrollo del business intelligence.
Las fronteras regulatorias del Big Data: crece el poder de la Unión Europea
(Artículo escrito por Elen Irazabal, alumni de Deusto Derecho y alumna de la II Edición del Programa en Tecnologías de Big Data en nuestra sede de Madrid)
La principal novedad que introduce la Unión Europea en lo concerniente al mundo del Big Data es la singular instauración del derecho fundamental de la protección de datos, separada del derecho fundamental a la privacidad, junto con el mandato legislativo que la Unión Europea se autoproclama en la materia:
El artículo 16 del Tratado del Funcionamiento de la Unión Europea establece que “El Parlamento Europeo y el Consejo establecerán, con arreglo al procedimiento legislativo ordinario, las normas sobre protección de las personas físicas respecto del tratamiento de datos de carácter personal por las instituciones, órganos y organismos de la Unión, así como por los Estados miembros en el ejercicio de las actividades comprendidas en el ámbito de aplicación del Derecho de la Unión y sobre la libre circulación de estos datos. El respeto de dichas normas estará sometido al control de autoridades independientes”.[1] Es decir, la Unión Europea se otorga la potestad de dictar normas que regulen la protección de datos de carácter personal sobre la libre circulación de estos datos y establece mecanismos de control de cumplimiento normativo.
Asimismo, la protección de datos de carácter personal viene declarada derecho fundamental en la Carta de Derechos Fundamentales, donde se faculta a sus titulares del “derecho a acceder a los datos recogidos que le conciernan y a su rectificación”.[2]
Así pues, las novedades que introduce el nuevo Reglamento General de Protección de Datos (RGPD) se centran en el mandato legislativo que regula una mayor protección a las personas físicas sobre sus datos, sobre la libre circulación de datos en el mercado único de la Unión.
Básicamente, la Unión Europea despliega su poder político sobre estas tres vertientes: se posiciona como garante de la protección de derechos de las personas físicas respecto a sus datos de carácter personal. Establece condiciones de funcionamiento del mercado interior de la unión. Y por último, se postula como voz única en las relaciones exteriores.
Veamos a continuación las novedades que introduce el Reglamento con respecto a la Directiva 95/46 que le precede en la materia y que nos proporcionan una visión de la estrategia política de las instituciones europeas desde las tres facetas antes mencionadas:
En primer lugar, una de las novedades principales del Reglamento con respecto a la Directiva 95/46 es la unificación y armonización de los criterios legislativos de la Unión, en aras de facilitar la libre circulación y que otorga a la Unión Europea el monopolio legislativo en la materia. La relevancia del Reglamento, reviste en efecto, en su carácter de aplicación directa y obligatoria sobre los actores involucrados en todos los Estados Miembros.
El monopolio legislativo se puede deducir de la facultad que declara la Carta de Derechos Fundamentales antes mencionada. De esta manera, el Reglamento otorga mayores derechos a los usuarios: derecho a la limitación del tratamiento, derecho a la portabilidad, un aumento de la transparencia y del ejercicio del derecho a la información, mayor derecho de indemnización y de interposición de denuncias y el famoso derecho al olvido. Derecho que, la Sentencia del Tribunal de Justicia de la UE del 13 de mayo de 2014 reconoció por primera vez.
Al establecer una batería de derechos al usuario, la legislación correlativamente impone renovadas obligaciones a las empresas. Tanto la adopción de medidas que aseguren el cumplimiento normativo (responsabilidad proactiva) como la adopción de modelos que acrediten la prevención de riesgos (protección de datos por defecto y desde el diseño). Las obligaciones de las empresas pueden consistir, y según los casos, desde el nombramiento de un delegado de protección de datos como en la notificación de brechas de seguridad a la autoridad de control, entre otros.
En segundo lugar, la aplicación se amplía en su aplicación territorial: No sólo se aplica a responsables de tratamiento de datos establecidos en la UE, sino que se expande a responsables y encargados no establecidos en la UE siempre que realicen tratamientos derivados de una oferta de bienes o servicios destinados a ciudadanos de la Unión o cuando las actividades de tratamiento estén relacionadas con el control de su tratamiento dentro de la UE.
Por el contrario, y a aunque la RGPD incluye modificaciones en el régimen de transferencias internacionales, perdura el poder de la Comisión Europea: sólo podrán realizarse transferencias de datos personales a terceros países que la Comisión considere que garantizar un nivel adecuado de protección (a falta de decisión sólo se podrán transmitir datos personales mediante garantías adecuadas o situaciones específicas). Por lo tanto, el criterio de la protección también se aplica en la toma de decisión de la Comisión Europea para decidir la adecuación del país receptor.
La Regulación no sólo regula el funcionamiento de los agentes económicos en el mercado único, sino que interviene estableciendo las fronteras regulatorias empresariales con terceros países que a su vez, colisionan con la jurisdicción y legislación de esos países. En consecuencia, el mundo del dato va a empujar la competencia legislativa de distintos países, que muy probablemente derivará en la cooperación de la Unión Europea, de la mano de la Comisión, a acuerdos internacionales que armonicen prácticas. Ejemplo de ello es el escudo de privacidad o la privacy shield entre EU y EEUU.
Concluyamos…
“Siete de las diez empresas con mayor valor bursátil del mundo se fundamentan en datos”[3], nuestro director Alex Rayón, dejaba este titular en su reciente entrevista a Masmovilidadi .El flujo global de los datos masivos y el procesamiento de los mismos, empujan a la globalización digital basada en el dato. La Unión, no ajena a este fenómeno global del Big Data, otorgó el carácter de derecho fundamental de la protección de datos de carácter personal. Con el objetivo de otorgar mayor control de los datos a las personas, la Unión Europea se posiciona como protector de las mismas, distanciándose de los principios y derechos que limitan la intervención en la vida de las personas por el poder político. El Derecho Fundamental no sólo no limita la injerencia política, sino que la expande al regular la conducta del mercado interior y constriñe el poder de decisión empresarial a costa del aumento del poder político. Por otro lado, la Unión establece por los usuarios el tipo de derechos a ejercer por ellos y guía centralizadamente su comportamiento en el mercado digital. Así, qué duda cabe, la Unión Europea refuerza su posición en la esfera comercial internacional.

[1] Art.16 https://www.boe.es/doue/2010/083/Z00047-00199.pdf
[2] Art.8 http://www.europarl.europa.eu/charter/pdf/text_es.pdf
[3] http://masmovilidad.com/2017/11/14/alex-rayon-entrevista-bigdata/
Deusto participará en la Cajamar UniversityHack 2018
Cajamar UniversityHack, la competición de analítica de datos más grande de España, celebra su edición de 2018 con Deusto entre los 20 centros seleccionados para participar! Deusto BigData sigue creciendo!

¿Qué es? Cajamar UniversityHack 2018 es un evento dirigido específicamente a los alumnos de los mejores centros formativos en Data Science de España. Para poder participar, deberás haber sido estudiante de alguno de nuestros Programas de Big Data (www.bigdata.deusto.es) en el curso 2016/17 y en la 2017/18.
Las inscripciones se abrirán a mediados de enero. La competición tendrá lugar del 31 de enero al 12 de abril de 2018. Máximo podrán participar 3 personas por cada equipo de Deusto (y resto de centros, claro). Como sospecho os querréis apuntar unos cuantos equipos, he preparado este formulario para que podamos luego entre todos determinar cuántos sois, y qué criterio justo aplicar en caso de que seais más de 10. En primer lugar, vamos a abrir el proceso de registro, y luego vemos si es necesario aplicar algún criterio justo. Os anticipamos, y pedimos, que en la medida de lo posible, os presentéis en parejas o tríos, para facilitar el mayor número de participantes. El formulario, como digo, lo podéis encontrar aquí. Tenéis hasta el 20 de enero para apuntaros, para que tengamos luego desde el 20 al 29 para poder registraros a todos y todas.
Tenéis tiempo aún, por lo que dedicar un rato a formar los equipos, hablar con posibles tutores, definir el enfoque del proyecto, etc.
Para participar, se podrán afrontar dos retos:
- Wefferent Card Analytics: crear una aplicación y/o visualización autoconsumible usando datos anonimizados de transacciones con tarjeta en la ciudad de Murcia, con una selección de datos reales agregados del Grupo Cajamar entre los años 2015 y 2017. Puedes realizar un cuadro de mando, un ejercicio analítico exploratorio, una infografía, una web, un análisis gráfico avanzado, etc.
- Salesforce Predictive Modelling: el poder adquisitivo de un cliente es uno de los ejes principales en el consumo de productos financieros siendo una variable crítica y de difícil cálculo. Uno de los retos a los que se enfrentan las empresas es predecir esta variable de cara a establecer segmentaciones estratégicas más eficientes que les ayuden en la toma de decisiones a la hora de ofrecer el producto más adecuado en cada momento a cada persona, según las necesidades de cada cliente. En este desafío dispondrás de 90 características anónimas que te permitirán estimar y predecir la renta de cada cliente.
¿Cuáles son los premios? Más allá del desarrollo de habilidades científicas y participar en un reto a nivel de todo el país, ya buenos premios. Además, el equipo ganador tendrá la oportunidad de presentar su trabajo en el Machine Learning Spain. Todos los detalles, los podéis encontrar aquí.

Además, solo por participar, tendrás estos beneficios:
- Cada participante recibirá el exclusivo welcome pack de nuestros patrocinadores.
- Un mes de suscripción con acceso ilimitado a todos los cursos especializados (Python, R, SQL, Git, Shell y mucho más) de la plataforma de formación online DataCamp.
- Un libro electrónico a elegir sobre una selección de publicaciones de la prestigiosa O’Reilly Media.
El calendario de fases e hitos, lo podéis consultar aquí. Hitos que se pueden resumir en los siguientes:
- Periodo de inscripción: del 15 al 29 de enero de 2018
- Confirmación de equipos participantes: 30 de enero 2018
- Fase 1 (en Deusto)
- Primera Fase del Concurso: del 31 de enero al 21 de febrero de 2018
- Fallo del jurado local: 1 de marzo de 2018
- Fase 2 (para todo España)
- Segunda Fase del Concurso: del 1 de marzo al 14 de marzo de 2018
- Selección de mejores trabajos: 27 de marzo de 2018
- Presentación de mejores trabajos y fallo del jurado nacional: 12 de abril de 2018
Anímate, y que Deusto BigData sea ganador de estos premios del Cajamar UniversityHack 2018! Os agradecería si pudieráis compartirlo con todos nuestros estudiantes de los cursos 2016/17 y 2017/18 para que nadie se quede fuera de esta magnífica oportunidad.
Lanzamiento de proyecto H2020 EDI: European Data Incubator en Deusto
Nuestra actividad alrededor del mundo del Big Data sigue creciendo. La Universidad de Deusto, a través de DeustoTech (el equipo MORElab (envisioning future internet)), coordinará el proyecto europeo European Data Incubator (EDI) por valor de 7,7 millones de euros para potenciar la creación de 140 nuevas empresas que exploten las tecnologías de Big Data y dar así solución a los retos de grandes proveedores de datos en Europa.

Este proyecto ha recibido financiación del programa de investigación e innovación Horizonte 2020 de la Unión Europea en virtud del acuerdo de subvención n° 779790.
Esta iniciativa busca, como decíamos anteriormente, atender a la creciente necesidad de contar con emprendedores de datos que saquen valor de los mismos a través de la ciencia de datos. No se trata solo de dominar un conjunto de tecnologías y herramientas, como hemos señalado en este blog con anterioridad, sino de aprender cómo poder aplicarlos para resolver problemas de negocio. Es difícil hoy en día encontrar ese perfil que no solo tenga una visión técnica, sino que también tenga esa visión de negocio para aplicarlo a diferentes realidades de empresa.
Por todo ello, el equipo de DeustoTech Morelab, cuenta con el apoyo de nuestro Deusto Entrepreneurship Center, que tratará de impulsar y trasladar a los participantes las skills necesarias para explotar el gran volumen de datos que han aparecido en nuestra sociedad derivado de su digitalización. Es decir, que podamos contar con más perfiles de científicas y científicos de datos, esos perfiles de los que tanto se habla, y no sabemos muchas veces cómo de claro está que se entienda lo que es.

Si os interesa conocer qué oportunidades os ofrecemos con esta iniciativa de desarrollo de perfiles de Big Data para el emprendimiento y la puesta en valor de los datos, os invitamos a participar el próximo 10 de enero en el evento donde daremos a conocer todos los detalles. El catalizador europeo de la innovación y promoción de start-ups en Big Data llega a Deusto! Apúntate aquí a nuestro European Data Incubator.

