(Artículo escrito por nuestra alumna Olatz Arrieta, de la 3ª promoción del Programa de Big Data y Business Intelligence en Bilbao)
Después de un año de duro trabajo, termino el Programa de Big Data y Business Intelligence impartido por la facultad de ingeniería de la Universidad de Deusto. A lo largo de este tiempo, hemos aprendido muchísimo de las múltiples facetas de este concepto tan amplio que es el “Big Data”, pero, sin duda, uno de los mejores y más prácticos decubrimientos ha sido el entorno–lenguaje “R”.
R es un lenguaje superversatil, gratuito y con un soporte “open” impresionante en internet (por supuesto en inglés), que te permite encontrar siempre solución, una paquete desarrollado y scripts de ejemplo, para cualquier necesidad que te encuentres en un proyecto. Yo, en este tiempo en el que me he podido empezar a asomar a este universo de posibilidades, lo he utilizado en prácticas de casos reales para distintos usos:
- Hacer calidad y manipulación de datos, eliminando las limitaciones de volumen que tenemos con herramientas habituales como Excel, y utilizando funciones que, en un solo paso, realizan operaciones que de otra manera supondrían numerosas pasos y tablas intermedias.
- Aplicar modelos de predicción (regresión, clasificación) y descripción (clustering, asociación, correlación,..) a importantes volúmenes de datos para extraer conclusiones relevantes y no inmediatas.
- Pasar información de un soporte-formato a otro de manera sencilla para poder importar o exportar desde o hacia distintas fuentes.
- Hacer tratamientos de texto: palabras key, nubes de palabras o análisis de sentimiento de cualquier texto, incluso de páginas web o RRSS (facebook, twitter,..)
Esta última aplicación de análisis de texto, ha sido el objeto de mi último proyecto de trabajo en el máster, cuyo objetivo era practicar con algunas de las herramientas que R tiene para estos cometidos.
Decidí analizar los textos de los discursos de navidad del Lehendakari y del Rey de España en diciembre 2007 y diciembre 2017. Quéría observar qué diferencias y evolución ha habido entre los dos perfiles en estos 10 años. Tras la correspondiente limpieza y adecuación de los textos, por ejemplo sustituyendo ñ por gn, eliminando tildes, poniendo en minúsculas todo, igualando conceptos similares como democracia – democrático/a para poder observar mejor su peso, etc. muestro un ejemplo de algunos de los resultados obtenidos
Las palabras que no faltan en ninguno de los discursos, estando presentes en todos, más de 2 veces, son las siguientes:
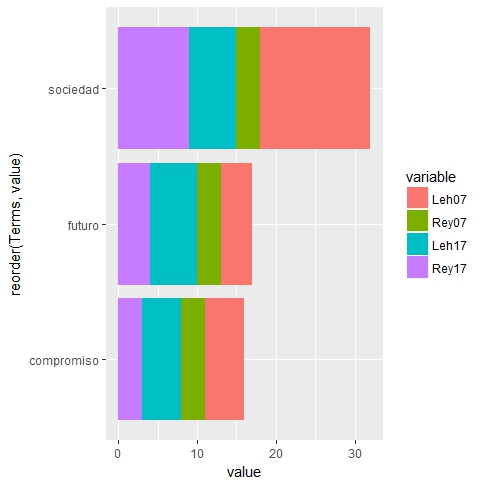
Las 20 palabras más repetidas en cada discurso, y su frecuencia de aparición a lo largo del mismo, son las siguientes:
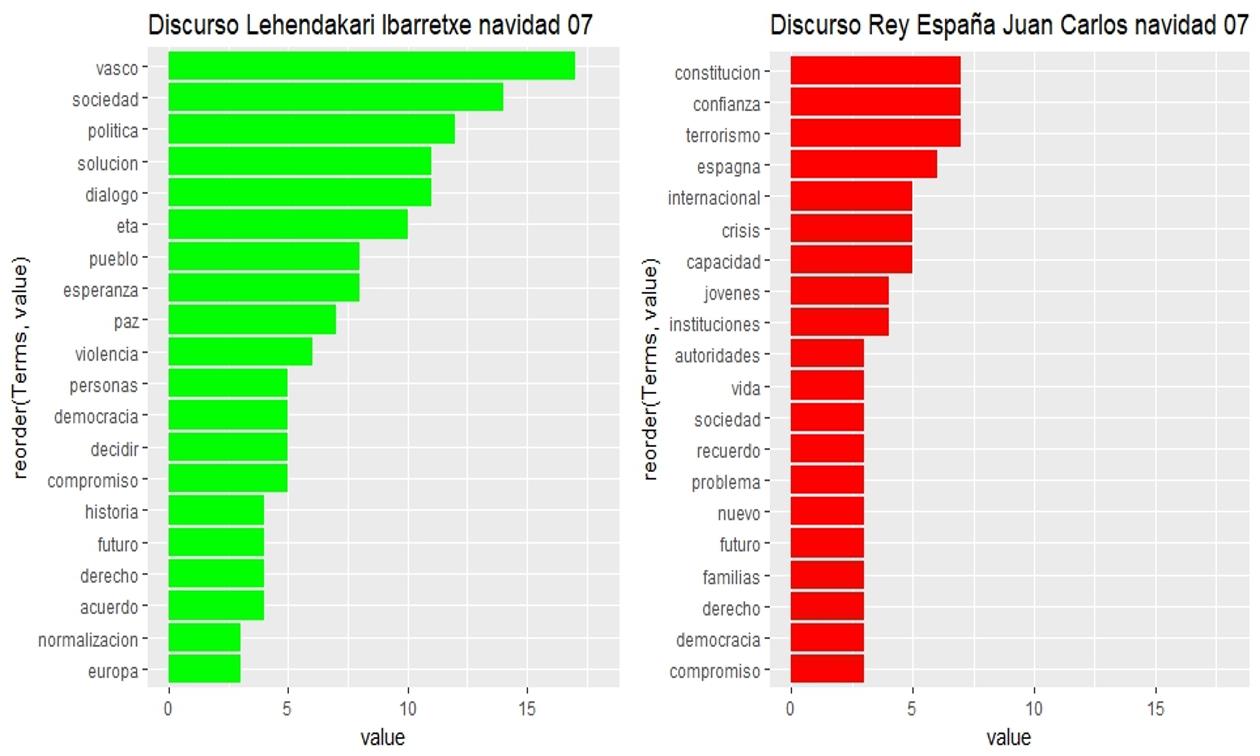
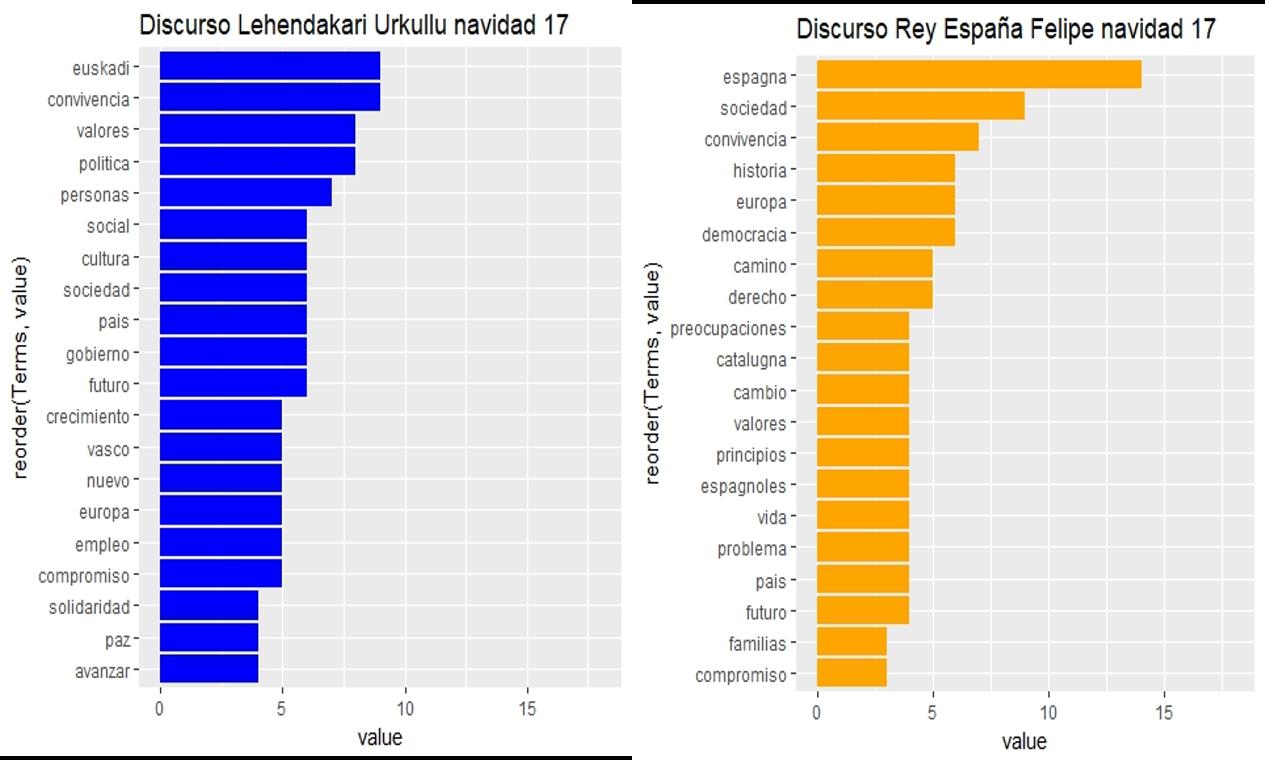
Sin ánimo de ser exhaustiva ni realizar valoraciones, destaco algunas observaciones sencillas que se pueden extraer como ejemplo:
- El Lehendakari Ibarretxe en 2007 ha sido sin duda el más reiterativo en los conceptos clave de su discurso ya que presenta claramente una frecuencia más alta en mayor número de palabras que los demás.
- En 2007 el Lehendakari repetía la palabra ETA mientras que el Rey usaba “terrorismo” y la temática “terrorismo” ha perdido peso en 2017
- En 2017 ambos dirigentes presentan en sus primeros puestos de reiteración, sus ámbitos territoriales (Euskadi, España) y aspectos ligados a la convivencia, sociedad o personas.
- En 2017 “Cataluña” no es mencionada de manera relevante por el Lehendakari y sí por el Rey que destaca también otras palabras ligadas a este asunto.
- La palabra “constitución”, principal argumento del discurso del Rey en 2007, desaparece de los discursos en 2017, siendo sustituida por conceptos más “soft”como democracia, derecho, principios,…
- La “política” es claramente una preocupación de los 2 Lehendakaris, mientras que no es destacada por los Reyes de España.
- La palabra “paz” la repiten ambos Lehendakaris y no los reyes, y la palabra “vida” a la inversa, está muy presente en los discursos de los reyes pero no de los Lehendakaris.
Esté hincapié en determinados conceptos se muestra más graficamente si elaboramos las NUBES DE PALABRAS, resultantes de seleccionar los términos que cada gobernante ha utilizado en más de 6 ocasiones a lo largo de sus discursos. Los tamaños y colores de letra representan pesos de frecuencias relativas dentro de cada discurso:

Se observa un distinto estilo de comunicación entre los dirigentes españoles y vascos. Los lehendakaris presentan un estilo en el que abundan los términos muy reiterados, mientras que en el caso de los reyes, éstos concentran la insistencia en menos términos.
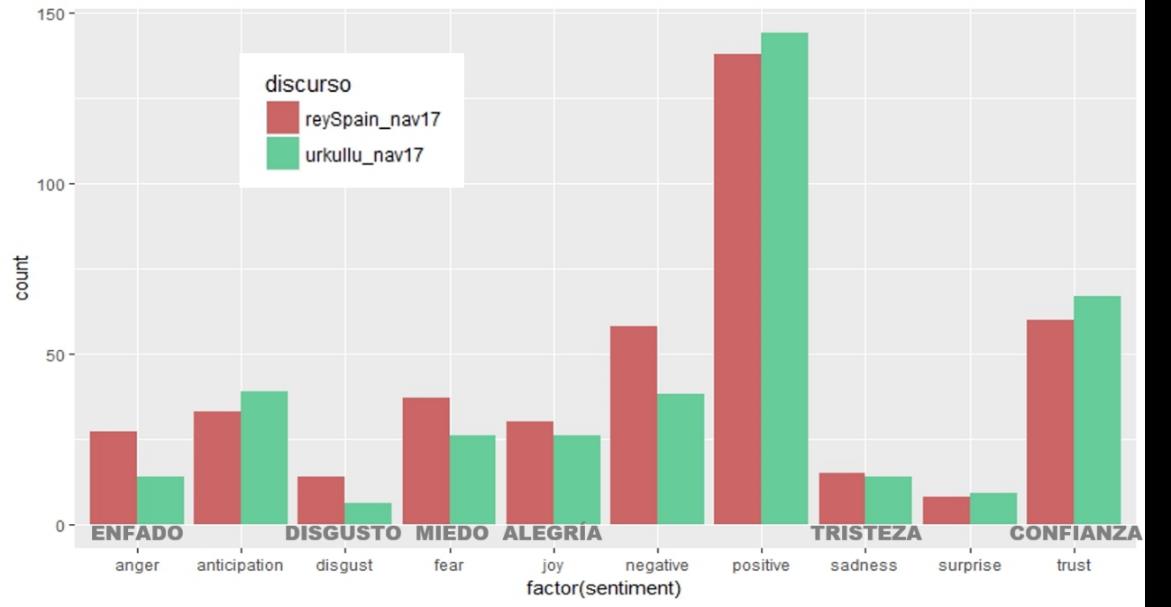
Por último, he querido hacer una pequeña prueba del funcionamiento de las herramientas de análisis de sentimiento. R dispone de diversos paquetes para ello, yo he usado Tidyverse y Tidytext, que presentan 3 lexicons que realizan una valoración “emocional” de los sentimientos que teóricamente generan las palabras utilizadas. Los lexicones son en inglés, por lo que he traducido directamente con google (R dispone también de paquetes específicos de traducción que utilizar APIs por ejemplo de microsoft, pero no he tenido tiempo de probarlos) los discursos del 2017 y, sin realizar ninguna revisión de la calidad de la traducción (seguramente habría que refinar muchas expresiones y términos), le he pasado los diccionarios lexicon de BING y NRC a cada discurso, para observar qué tipo de emociones provoca cada uno.
He aquí el resultado resumido del peso de cada sentimiento en los discursos de 2017:
Por último, utilizando el lexicon de AFINN que valora numéricamente las palabras entre -5 y +5 según la negatividad o positividad de sentimientos generados, el resultado final es el siguiente, expresado en los correspondientes histogramas de frecuencia de presencia de cada tipo de valor emocional:
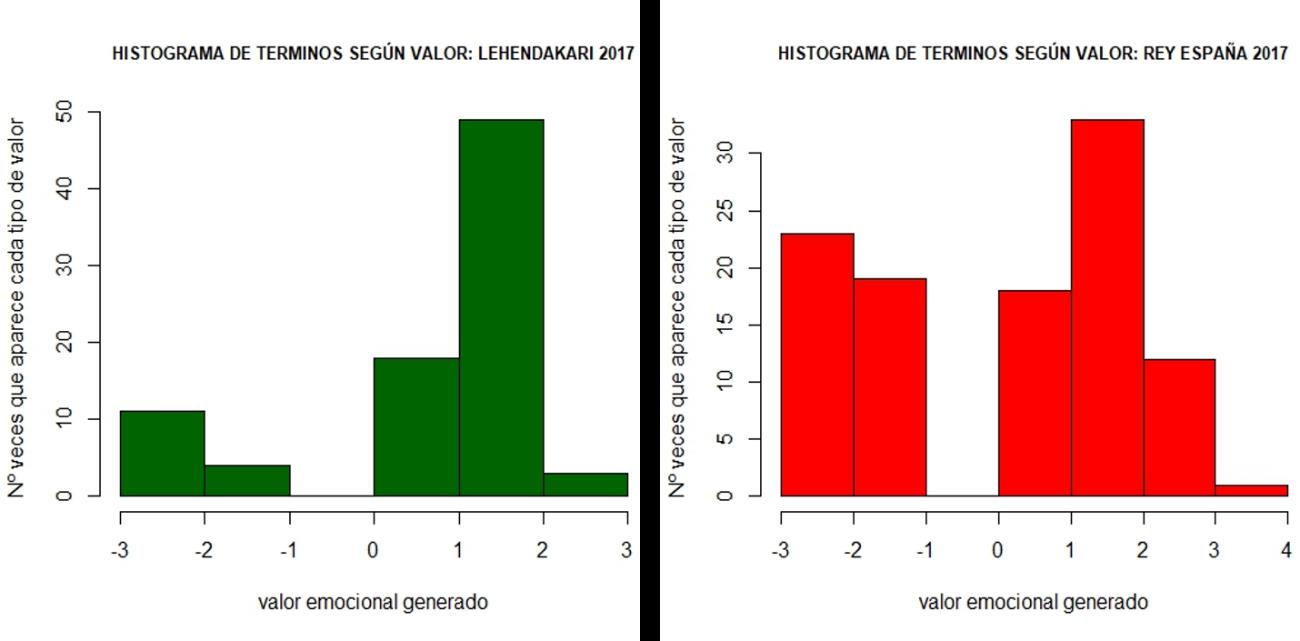
Se observa que el discurso del lehendakari se encuentra sesgado hacia la positividad mientras que el del Rey de España presenta más valores extremos, lo que resulta en un valor “emocional” medio de +1,06 sobre 5 en el caso del lehendakari y de un 0,49 sobre 5 en el caso de el Rey, resultados que corroboran el obtenido en la clasificación de términos anterior.
En resumen, que R es una herramienta que, una vez realizado el esfuerzo inicial imprescindible para adquirir la competencia mínima, presenta un enorme potencial de aplicación a casi cualquier necesidad o problema de análisis de datos que a una empresa se le pueda presentar, siendo un aliado muy interesante y recomendable para el desarrollo del business intelligence.