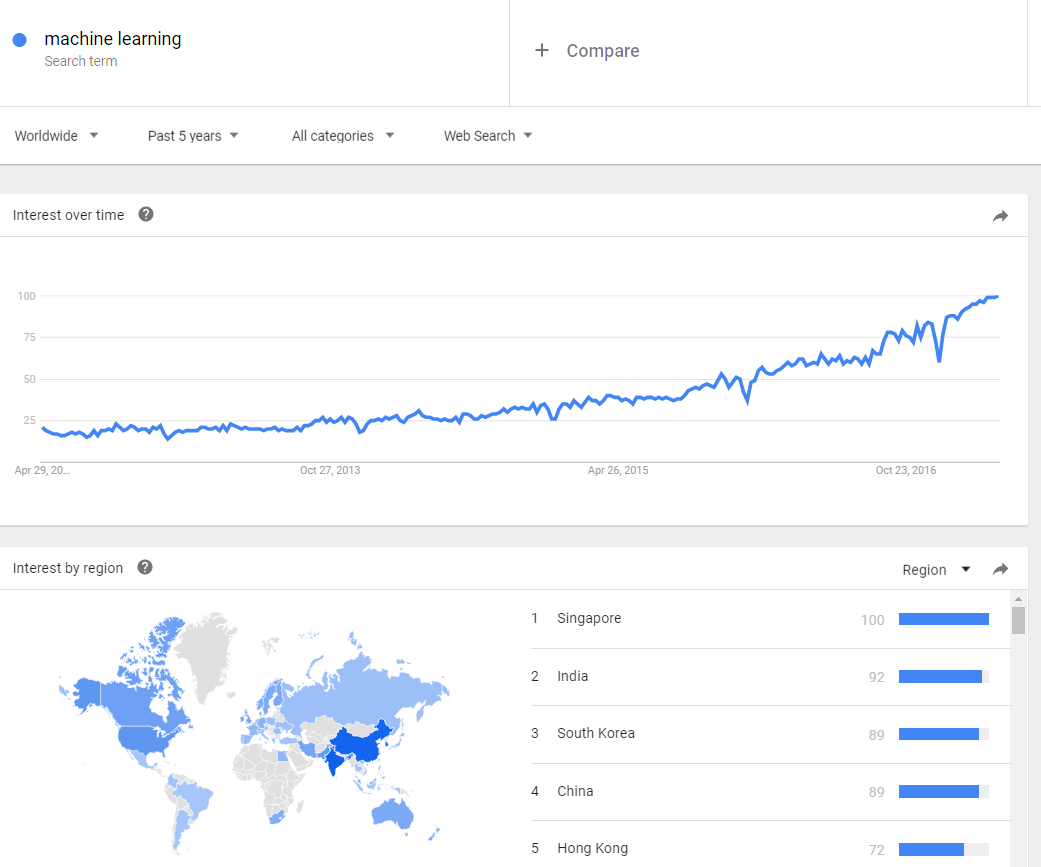
Nuevo informe del Programa “Análisis, investigación y comunicación de datos” de Deusto sobre basuras marinas
Las basuras marinas –constituidas por plásticos sobre todo — son tal problema que este año el Programa de la ONU para el Medio Ambiente (PNUMA) ha lanzado una campaña global para eliminar en 2022 las fuentes de basura en los océanos. La mayor parte de las basuras encontradas en playas y riberas terminan en el mar. Por eso es vital conocer qué tipo de basura y en qué cantidades se encuentran en nuestras playas y ríos, y qué factores influyen su disminución o aumento.
El informe del Programa “Análisis, investigación y comunicación de datos” de Deusto contribuye a responder a algunas de estas en un reciente informe sobre basuras marinas que concluye que:
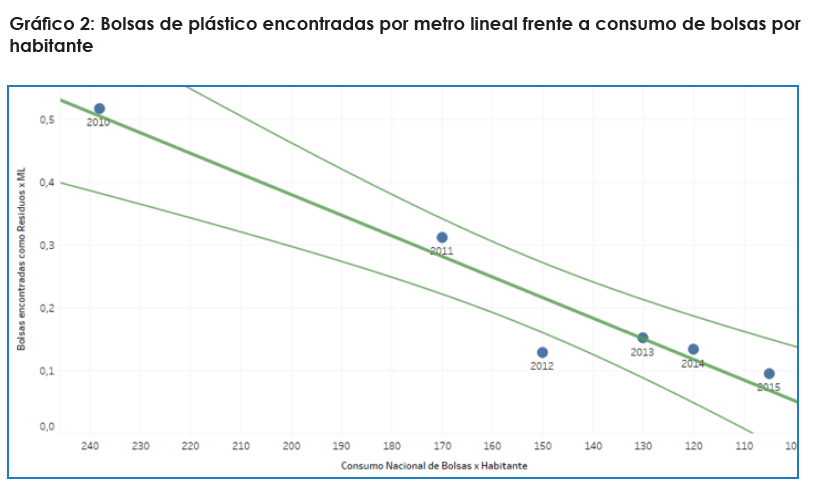
- La caída del consumo de bolsas de plástico experimentada en los últimos años en el estado ha tenido un impacto directo en una reducción de un 80% de este tipo de bolsas en las zonas playeras y ribereñas en las que hubo limpiezas entre 2010 y 2015, incluidos. Vimos una relación estadística entre los datos de las limpiezas y de consumo de bolsas.
- El Parque Regional Puntas de Calnegre-Cabo Cope, en Murcia, es el punto donde más basuras se encontraron por metro lineal de playa de los lugares estudiados (21,77 residuos de todo tipo por metro lineal). En comparación en Euskadi se encontraron 0.53 unidades de residuos por metro lineal.
- El número de residuos relacionados con la agricultura intensiva y tuberías PVC está en aumento. 2015 multiplica por más de ocho la cantidad de residuos de este tipo encontrados el año anterior.
El informe está basado en el análisis de los datos obtenidos sobre cerca de 50.000 kilogramos de basuras recogidas entre 2010 y 2015 por miles de voluntarios/as de la Asociación Ambiente Europeo (AAE) en cerca de 250 limpiezas en todo el estado, como parte del proyecto International Coastal Cleanup de Ocean Conservancy.
En esos años se realizaron las siguientes limpiezas, en orden de más a menos: Andalucía, 58; Murcia, 54; Valencia, 53; Canarias, 28; Islas Baleares, 23; Castilla y La Mancha, 9; País Vasco, 7; Galicia, 4; Cataluña, 3; Madrid, 3; Asturias, 2.
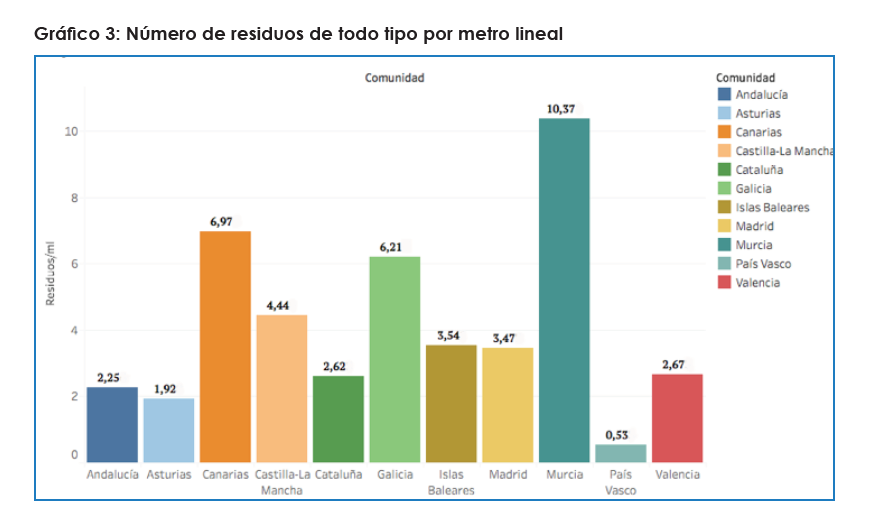
De los casi 50.000 kilogramos de basuras recogidas, solo 680 kilogramos corresponden a playas y riberas vascas. En total significa 0,12 kilos por metro lineal limpiado. Las más sucias entre las que se hicieron limpiezas son, por año, Pasaia, Gipuzkoa (1.099 residuos en 2011), Punta Galea (565, en 2015) y Muskiz (424, en 2012), en BizKaia. Las basuras más comunes en las playas y riberas vascas fueron en orden de mayor a menor envoltorios de comida, bolsas de plástico, cuerdas, botellas de plástico, tapas de botellas y latas, lo que, con excepción de la presencia de cuerdas y ausencia de, replica más o menos lo que se encuentra en otras playas. Los plásticos relacionados con la agricultura son frecuentes en las playas andaluzas, murcianas y canarias.

Hoy el PNUMA calcula que son más de 8 millones de toneladas de plásticos los que terminan en el mar cada año; es decir, lo equivalente a tirar un camión entero de plásticos cada minuto. En la próxima década nuestros océanos tendrán alrededor de un kilo de plástico por cada tres kilogramos de pescado. Especialmente preocupantes son los llamados microplásticos, pequeñas partículas de plástico de hasta 5 mm de diámetro, que pueden ingerir peces y así entran en nuestra cadena alimenticia.
El informe está firmado por Ricardo León y Janire Zubizarreta, participantes en el Programa “Análisis, investigación y comunicación de datos” de Deusto, y su directora, Miren Gutiérrez. Se enfrentaron al reto de estandarizar y limpiar una base de datos que no estaba estructurada adecuadamente para su análisis, así como geolocalizar los datos, buscar correlaciones entre datos externos y datos obtenidos de las limpiezas de playas y riberas, y responder a preguntas de investigación de enorme relevancia.