[:es]Ya puedes solicitar información para tramitar la admisión en el Programa Experto “Análisis, investigación y comunicación de datos”. Abajo tienes las fechas clave para tramitar tu participación.
Este año, además de tener la posibilidad de hacer dos itinerarios –uno especializado en comunicación estratégica y el otro en análisis de datos—, también existe la posibilidad de optar a una de las becas parciales que ofrecerá el Programa. Te mantenemos informado/a.
¡No te lo pierdas!
Período de admisión
15 JUL al 15 SEP
Comunicación de las resoluciones a Secretaría General
20 SEP
Período de matrícula
26 SEP al 6 OCT
Decisión para la impartición del Experto dependiendo del número de matrículas
Los “Papeles de Panamá”, la mayor filtración periodística de toda la historia, además de haber puesto encima de la mesa mucho debate en torno a la ética de muchos ciudadanos, se han relacionado mucho con el mundo del Big Data. Una vez obtenidos los documentos (2.6 terabytes, y 11,5 millones de documentos), hubo que analizarlos para extraer inteligencia de los mismos. En el proceso ha habido desde tecnologías para extraer e integrar datos, a nuevos sistemas procesar y visualizar el conocimiento extraído.
Pero no solo el periodismo de investigación se beneficia de estas nuevas tecnologías de Big Data. Las empresas están empezando a entender también la utilidad de trabajar con los datos. Y eso, teniendo en cuenta que actualmente sólo se usa el 5% de todo el caudal de datos. Ante la multidimensionalidad de esta transformación económica y tecnológica, se están creando nuevos perfiles y puestos de trabajo desconocidos en nuestra sociedad y que tienen que ver con los datos. Se necesita un perfil que conozca del ámbito técnico, del económico, del legal, del humano, etc., y de competencias genéricas como la inquietud, el trabajo en equipo, la creatividad, orientación a la calidad y el cliente, etc. Queda claro así, que esto no es un campo sólo técnico; es mucho más amplio y diverso.
Por ello, queremos en este evento contar la presencia de protagonistas de este cambio. Organizaciones y empresas, que sí tienen esta visión del dato como elemento transformador de su propuesta de valor y su modelo de negocio. Abriremos la jornada con una conferencia de Mar Cabra, la periodista jefe de la unidad Data & Research del Consorcio Internacional de Periodistas de Investigación que ha coordinado la investigación sobre los papeles de Panamá. Posteriormente, hemos organizado una mesa redonda en la que participarán Mario Iñiguez, de Adamantas Analytics (empresa que provee soluciones de tecnologías de bases de datos de grafos), Roberto Tamayo, Gerente Riesgos Tecnologicos y Seguridad de Deloitte y, Miren Gutiérrez, Directora del Programa Experto «Análisis, investigación y comunicación de datos» e Investigadora Asociada del Overseas Development Institute (Londres)
El evento se celebrará el próximo 9 de Junio en el Aula Digital del Campus de San Sebastián, de nuestra Universidad de Deusto. Lo haremos en nuestro Campus de San Sebastián, aprovechando que lanzaremos nuestro Programa de Big Data y Business Intelligence allí el próximo Octubre. El evento tendrá la programación que se indica a continuación, y podéis apuntaros al mismo a través de este formulario. Tendremos un aforo limitado a 80 personas, por lo que rogamos te inscribas en el evento para que no te quedes sin tu plaza.¡No te lo pierdas!
09:45 – 10:00. Recepción de asistentes y entrega documentación.
Empecemos por lo básico, definiendo qué son los algoritmos y por qué hablamos ahora de «cajas negras». Los algoritmos básicamente es lo que hacemos los informáticos cuando nos ponemos a crear una serie de reglas abstractas para transformar datos. Es decir, cogemos una fuente de información o datos, y dado que no está expresado ni representan aquello que queremos obtener, diseñaños y desarrollamos una serie de reglas que permiten encontrar, expresar y representar aquello que estábamos buscando.
Además, desde que hemos introducido el paradigma Big Data, los algoritmos también buscan, patrones, relaciones, etc. Dado que cada vez codificamos y automatizamos un mayor número de nuestras conductas, deseos, emociones, etc. en entornos digitales, producimos una mayor cantidad de datos. Y más interesante resulta para muchas industrias desarrollar algoritmos para encontrar inteligencia que transformar en negocio.
Por ello, hoy en día, tenemos muchos, muchísimos algoritmos. Además, cada vez más sofisticados. Junto con el hardware y las redes, constituyen los ejes clave sobre los que pivota esta transformación digital de muchas industrias. Estamos ya ante las máquinas más sofisticadas del planeta. Lo cual está muy bien: más seguridad, optimización de las rutas para evitar perder tiempo, frenos automáticos, etc. 100 millones de líneas de código incorporan los nuevos vehículos (frente a las 60 millones de líneas que tiene Facebook y las 5 millones de líneas que tiene el colisionador de hadrones, para que se hagan a la idea de la complejidad de la que habalmos). Estamos ante las primeras máquinas que están alcanzando los límites biológicos de la complejidad.
El problema, además de su complejidad, es que fueron concebidos por una serie de personas, que seguían algún objetivo, no siempre claro. La intencionalidad del ser humano es inherente a lo que hacemos. Actuamos en base a incentivos y deseos. Por lo tanto, la pregunta que nos solemos hacer cuando pensamos en las cajas negras de los algoritmos pasan por su reingeniería. Es decir, saber cuáles son las reglas que los gobiernan.
Algoritmos de caja negra (Fuente: https://es.wikipedia.org/wiki/Caja_negra_(sistemas)#/media/File:Blackbox3D.png)
Cuando no sabemos qué reglas son éstas, hablamos de algoritmos de «caja negra». No sabemos cómo funcionan, cuál es el criterio con el que lo hacen, con qué objetivos fueron concebidos, etc. Por ello, el libro que os recomendaba al comienzo, sugiere que comencemos a discutir también sobre el «accountability» o «escrutinio» de los algoritmos. En una era en la que las apuestas contras las divisas de los países, los coches o servicios públicos son autónomos, o personas o sistemas de Big Data que toman decisiones de sanidad son codificadas en algoritmos, no podemos esquivar esta conversación.
En este sentido, el libro de Pasquale, introduce la «Ética de la tecnología» bajo tres perspectivas que debieran ser consideras cuando construimos algoritmos:
Crítica deontológica: es decir, que los resultados a obtener deban satisfacer una serie de reglas, políticas, principios, etc.
Crítica teleológica: valorar las consecuencias de los resultados que obtienen esos algoritmos.
Crítica de valores: diseño que considera de manera explítica e implítica los valores compartidos en una sociedad global, además de a los propios stakeholders que perciben y usan el sistema como se pensaba en un comienzo.
Con estas tres miradas a incorporar cada vez que enfrentamos el diseño y desarrollo de un algoritmos, son varios los elementos a considerar para ser responsable en su concepción y sus posibles consecuencias. Especialmente, para el campo del Big Data:
Disponibilidad: que sea fácil de disponer, no solo ya el propio código, sino también su funcionamiento.
Facilidad de mantenimiento: que no resulte difícil de mantener para una persona ajena al que diseñó y desarrolló el algoritmo.
Inteligibilidad: entendible para más personas que los que formaron el equipo de su creación.
Integridad del algoritmo: que se mantenga íntegro y no solo funcione para un conjunto de datos determinados.
Selección del modelo y atributos: que el modelo sea representativo de la realidad que quiere reflejar. Los atributos a seleccionar para su caracterización, también resultan críticos.
Integridad de los datos: lo que decíamos a nivel de algoritmo, también a nivel de datos. Que se mantengan íntegros y no sean susceptibles de modificaciones fáciles o ser demasiado volátiles.
Propiedad colectiva de los datos: que los datos no sean propiedad del que desarrolló el algoritmo; desacoplando esa propiedad, podríamos hablar de un compromiso social y global.
Sesgo de selección: ¿qué preguntas nos estamos haciendo a la hora de construir el algoritmo? No caer en la trampa de seleccionar solo las partes que más nos interesan o favorecen.
En el congreso Governing Algorithms, se trataron muchos de estos temas. Pero, además hablaron también de otra forma de diseñar y desarrollar algoritmos, con ejemplos como:
Sunlight Foundation: una organización que trabaja en la explotación de datos en el campo de la innovación social, el análisis de las facturas de gobiernos para encontrar relaciones o patrones, etc.
Enroll America: búsqueda de ciudadanos no asegurados de manera activa e inteligente para mejorar su bienestar.
Data Science for Social Good: una iniciativa de la Universidad de Chigado para formar «data scientist» en la construcción de algoritmos para la mejora del bienestar global.
Como toda herramienta, en su uso, dependerá su evaluación. Una evaluación, que como han visto, tampoco es sencilla. ¿Es ético un algoritmo? Depende de todos los factores arriba listado. Lo que sí parece claro es que cuando cogen una forma de «caja negra», suponen un riesgo global importante. Está en nuestras manos que el «accountability» sea efectivo, y no construyamos reglas que no satisfagan esas perspectivas de análisis citadas.
Kenneth Arrow, premio Nobel de Economía en 1972, y experto en predicciones económicas dijo aquello de:
“El buen pronóstico no es el que te dice que lloverá, sino el que te da las probabilidades”.
Esto es algo que suelo comentar a la hora de hablar de predicciones. No tienen más que abrir muchos titulares de periódicos para darse cuenta que la ausencia de la estimación de probabilidades es palpable. Y eso a pesar que nada es seguro hasta que ocurre y que la probabilidad cero no existe. La certeza y la magia debieran quedar excluidas de nuestra manera de ver el mundo.
Por todo ello, quiero hablar hoy de cómo poder manejarnos en este mundo de la incertidumbre, asignando probabilidades a las diferentes alternativas que puede tomar un determinado suceso. De esta manera, podremos ayudar a las empresas, organizaciones e individuos a asignar eficientemente recursos en múltiples situaciones. Y, como solemos decir en el mundo del Big Data, tomar mejores decisiones.
Predecir consta de tres partes:
Modelos dinámicos
Análisis de datos
Juicio humano
En el mundo de las predicciones, las empresas han solido llevar la delantera. Básicamente, porque trabajan en mercados. Los economistas suelen decir que los mercados proporcionan 1) incentivos para buscar información; 2) incentivos a revelar la información; y 3) un mecanismo para agregar información dispersa. Por eso solemos tener todos un amigo empresario al que solemos preguntarle por el desenlace de muchas cuestiones que nos pueden afectar.
Primero, hablemos de probabilidades. Supongamos que estamos con un amigo intentando predecir la cara que saldrá al tirar la moneda al aire. Intuitivamente, todos nosotros podemos pensar que la probabilidad de que salga cara es de 0,5. Y que incluso esto es un concepto «absoluto», en el sentido que todos deberíamos pensar lo mismo. Esto es lo que se denomina una interpretación frecuentista de la probabilidad, y es la que ha sido predominante a lo largo del Siglo XX, con Ronald A. Fisher a la cabeza.
Sin embargo, hay otro enfoque, algo más antiguo. Y es una en la que ese 0,5 se le da un carácter subjetivo, dado que un jugador puede esperar una mayor o menor probabilidad. Este enfoque fue mayoritario en el Siglo XIX, con Pierre-Simon Laplace al frente. Y esta subjetividad en la interpretación de la probabilidad se la debemos al Teorema de Bayes. Dado que en muchas ocasiones, para predecir, tenemos un conocimiento limitado, la probabilidad es la expresión matemática de ese conocimiento. Es decir, que yo «no puedo predecir con un 50% de probabilidades que saldrá cara«, sino que diría «basándome en el conocimiento que tengo, hay un 50% de certeza que saldrá cara«.
El auge de los métodos Bayesianos, especialmente, por la irrupción del Big Data (que trae nuevo conocimiento), está provocando que mucha gente cambie la forma de afrontar estos problemas, dado que Bayes no solo es una fórmula, sino también una manera de afrontar predicciones y situaciones. Consiste en que a nueva información (recibida), nueva probabilidad (estimada). Según vaya obteniendo nueva información, mejoro las probabilidades iniciales que tengo. A más información, más probabilidad puedo estimar. De ahí la relación con el Big Data, claro.
Probabilidades de encontrar los restos del vuelo de Air France (Fuente: https://www.technologyreview.com/i/images/AF447.png?sw=590)
Uno de los campos donde más interés puede tener ahora mismo Bayes es en de la aplicación de la inteligencia colectiva para predecir sucesos. Cuando la predicción de un resultado/suceso se vuelve compleja, el enfoque de la «inteligencia colectiva» sugiere agregar información dispersa y heterogénea. En ese proceso de agregación, quitamos el «ruido», dado que todo paquete de información se compone de una parte veraz (señal) y de ruido (aleatorio) -la Teoría de la Información de Shannon de 1948-.
Así, de esta agregación de predicciones subjetivas de una realidad, nace un nuevo «mercado de predicciones». Algunos autores prefieren llamarlos “mercados de información”, dado que reflejan una mejora de la información disponible gracias a la «sabiduría de las masas». Otros los llaman “mercados de futuros de ideas” o “mercados de decisiones”, reseñando así el valor que tiene.
Estos mercados se basan en la teoría de la “sabiduría de las masas”. Esta, fue descubierta en 1906 por el estadístico Francis Galton (que también bautizó conceptos como la correlación o la regresión a la media). Su tesis fue aparentemente sencilla: la predicción de un grupo de personas expresada como un todo, mejora la precisión de cualquiera de sus partes por separado. En el libro «The Wisdom of Crowds» de James Suroweicki, en 2004, esta teoría fue impulsada de nuevo, gracias a sus postulados sobre cuándo esta puede funcionar y cuándo no. James, expone que existen tres tipos de problemas que pueden ser resueltos por la inteligencia colectiva:
Problemas cognitivos (siempre tienen una solución, o, en su defecto, hay unas respuestas mejores que otras);
Problemas de coordinación (los miembros de un grupo se ven en la necesidad de armonizar su comportamiento con el del resto de la gente);
Problemas de cooperación (personas que buscan satisfacer el propio interés se ven en la necesidad de lidiar con los demás para obtener una solución que sea buena para todos).
A nivel estadístico, lo que ocurre es que si se agregan apropiadamente la visión de muchas personas, el ruido queda compensado con el ruido, y nos quedamos con la señal. Es una teoría realmente útil y eficiente, pero que requiere de la heterogeneidad de las fuentes, la toma de decisiones independientes y un buen proceso de agregación de información. De ahí que este enfoque científico sea utilizado por las empresas con mucho rigor cuando se juegan millones de dólares con sus apuestas. En el el mercado de predicciones, estos requisitos se garantizan habilitando un mercado bursátil a la hora de incentivar a los participantes a aportar solamente la mejor información disponible, puesto que los beneficios o pérdidas irán a parar directamente a ellos.
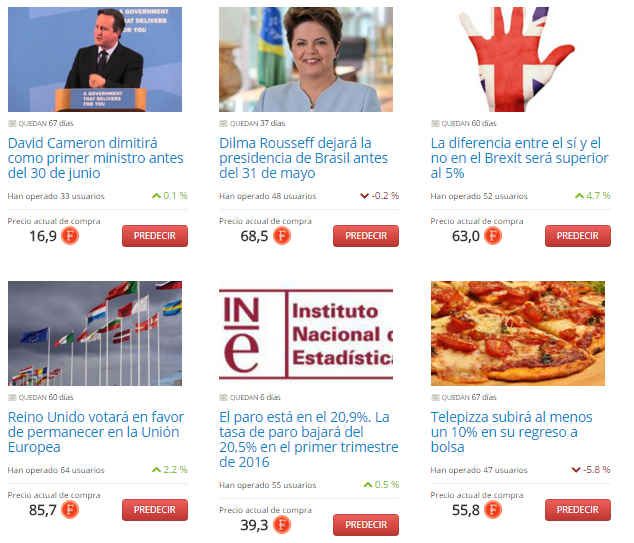
En España, como mercado de predicciones que funciona y marca tendencias, está FuturaMarkets.com como uno de los más conocidos. El precio indica la probabilidad de que un determinado evento ocurra. Los participantes, compran o venden acciones si creen que la probabilidad real es distinta. Y esto es lo que hace fluctuar el mercado, y estas «predicciones de las masas que tienen los incentivos adecuados para acertar» (dado que ganarán dinero) es lo que hace que sean mercados con mucha capacidad informativa. No me deja de sorprender que no se use más, por ejemplo, en telediarios o en medios de comunicación. Ahora mismo podemos ver qué se opina sucesos tan diversos como la presidencia de Brasil, la salida del Reino Unido de la UE, el paro en España o el regreso de Telepizza a España:
Mercado de predicciones en Futura Markets (Fuente: http://www.futuramarkets.com/)
Como vemos, Bayes está de vuelta. Y la utilización de su enfoque para un «mercado de predicciones» abre un mundo muy interesante y de utilidad para los próximos años. Y en todo ello, el Big Data, con sus técnicas de agregación de datos heterogéneos, juega un papel clave.
Bayes y la inteligencia colectiva al servicio de la predicción en la era del Big Data. ¿A qué esperamos para seguir sacando provecho de ella?