Mucho se ha escrito la que aparentemente va a ser la profesión más sexy del Siglo XXI. Más allá de titulares tan rimbonbantes (digo yo, que quedan muchas cosas todavía que inventar y hacer en este siglo :-), lo que viene a expresar esa idea es la importancia que va a tener un científico de datos en una era de datos ubicuos, coste de almacenamiento, procesamiento y transporte prácticamente cero y de constante digitalización. La práctica moderna del análisis de datos, lo que popularmente y muchas veces erróneamente se conoce como «Big Data», se asienta sobre lo que es la «Ciencia del Dato» o «Data Science».
En 2012, Davenport y Patil escribían un influyente artículo en la Harvard Business Review en la que exponían que el científico de datos era la profesión más sexy del Siglo XXI. Un profesional que combinando conocimientos de matemáticas, estadística y programación, se encarga de analizar los grandes volúmenes de datos. A diferencia de la estadística tradicional que utilizaba muestras, el científico de datos aplica sus conocimientos estadísticos para resolver problemas de negocio aplicando las nuevas tecnologías, que permiten realizar cálculos que hasta ahora no se podían realizar.
Y va ganando en popularidad en los últimos años debido sobre todo al desarrollo de la parte más tecnológica. Las tecnologías de Big Data empiezan a posibilitar que las empresas las adopten y empiecen a poner en valor el análisis de datos en su día a día. Pero, ahí, es cuando se dan cuenta que necesitan algo más que tecnología. La estadística para la construcción de modelos analíticos, las matemáticas para la formulación de los problemas y su expresión codificada para las máquinas, y, el conocimiento de dominio (saber del área funcional de la empresa que lo quiere adoptar, el sector de actividad económica, etc. etc.), se tornan igualmente fundamentales.
Pero, si esto es tan sexy ¿qué hace el científico de datos? Y sobre todo, ¿qué tiene que ver esto con el Big Data y el Business Intelligence? Para responder a ello, me gusta siempre referenciar en los cursos y conferencias la representación en formato de diagrama de Venn que hizo Drew Conway en 2010:
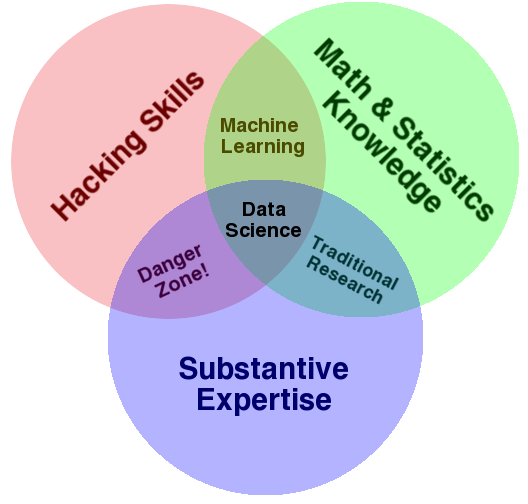
Como se puede apreciar, se trata de una agregación de tres disciplinas que se deben entender bien en este nuevo paradigma que ha traído el Big Data:
- «Hacking skills» o «competencias digitales con pensamiento computacional«: sé que al traducirlo al Español, pierdo mucho del significado de lo que expresa las «Hacking Skills». Pero creo que se entiende bien también lo que quieren decir las «competencias digitales». Estamos en una época en la que constante «algoritmización» de lo que nos rodea, el pensamiento computacional que ya hay países que han metido desde preescolar, haga que las competencias digitales no pasen solo por «saber de Ofimática» o de «sistemas de información». Esto va más de tener ese mirada hacia lo que los ordenadores hacen, cómo procesan datos y cómo los utilizan para obtener conclusiones. Yo a esto lo llamo «Pensamiento computacional», como una (mala) traducción de «Computation thinking», que junto con las competencias digitales (entender lo que hacen las herramientas digitales y ponerlo en práctica), me parecen fundamentales.
- Estadística y matemáticas: en primer lugar, la estadística, que es una herramienta crítica para la resolución de problemas. Nos dota de unos instrumentos de trabajo de enorme valor para los que trabajamos con problemas de la empresa. Y las matemáticas, ay, qué decir de la ciencia formal por antonomasía, la que siguiendo razonamientos lógicos, nos permite estudiar propiedades y relaciones entre las variables que formarán parte de nuestro problema. Si bien las matemáticas se la ha venido a conocer como la ciencia exacta, en la estadística, nos gusta más jugar con intervalos de confianza y la incertidumbre. Pero, por sus propias particularidades, se nutren mutuamente, y hace que para construir modelos analíticos que permitan resolver los problemas que las empresas y organizaciones nos planteen, necesitemos ambas dos.
- Conocimiento del dominio: para poder diseñar y desarrollar la aplicación del análisis masivo de datos a diferentes casos de uso y aplicación, es necesario conocer el contexto. Los problemas se deben plantear acorde a estas características. Como siempre digo, esto del Big Data es más una cuestión de plantar bien los problemas que otra cosa, por lo que saber hacer las preguntas correctas con las personas que bien conocen el dominio de aplicación es fundamental. Por esto me suelo a referir a «que hay tantos proyectos de Big Data como empresas». Cada proyecto es un mundo, por lo que cuando alguien te cuente su proyecto, luego relativízalo a tus necesidades 😉
Estas tres cuestiones (informática y computación, métodos estadísticos y áreas de aplicación/dominio), también fueron citadas por William S. Cleveland en 2001 en su artículo «Data Science: An Action Plan for Expanding the Technical Areas of the Field of Statistics«. Por lo tanto, no es una concepción nueva.
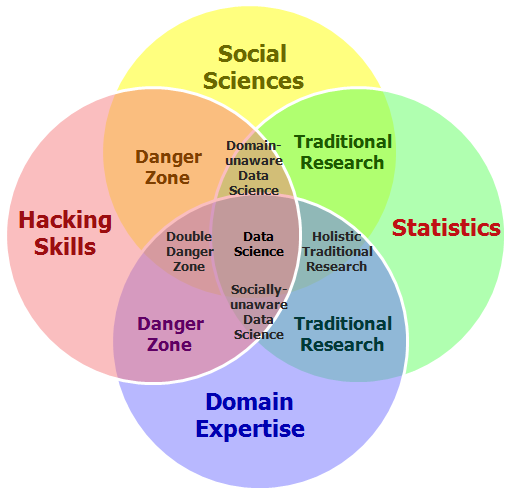
Este Diagrama de Venn ha ido evolucionando mucho. Uno de los que más me gustan es éste, que integra las ciencias sociales. Nuestro Programa Experto en Análisis, Investigación y Comunicación de Datos precisamente busca ese enfoque.

Hola Alex, me gusta leer tus artículos y te animo a que sigas divulgando estos temas en nuestro entorno.
Sólo una apreciación sobre la Estadística. La definición con la que más de acuerdo me siento es que «La Estadística es la ciencia que trata del MODO DE RECOGER LOS DATOS para transformarlos en información útil». Y si uno comparte esta definición entiende porqué hay que ser «científico de datos» cuando quiere obtener CONOCIMIENTO de los DATOS…y porqué este tema es crítico y va a serlo mucho más si la captura y el análisis se automatizan (QUÉ MIEDO!!)
Si uno entiende al cliente y lo que desea conocer, al negocio y el modo en que ocurren los fenómenos, identifica las herramientas analíticas apropiadas y por consiguiente el tipo de datos necesarios, identifica los riesgos a la hora de obtener los datos y la naturaleza del ruido, ….ENTONCES toma las medidas adecuadas para recoger los datos con rigor… decide los algoritmos a aplicar, las herramientas,….y una vez aplicado los análisis interpreta adecuadamente teniendo en cuenta el método de recogida.
Hoy en día ya existe una grave problema de investigaciones basura… pidamos rigor
http://www.andreasaltelli.eu/science-on-the-verge
Saludos
Hola, excelente artículo. Me gustaría aportar sobre lenguajes que también son útiles (no sólo R).También Java y Python, pueden despejar las dudas de estos lenguajes a continuación: http://adictec.com/lenguajes-para-convertirte-en-cientifico-de-datos/
Saludos.
Hola,
Genial el artículo, para todos aquello que tengan curiosidad y ganas de ser científico de datos aquí os dejo un vídeo https://www.youtube.com/watch?v=c4X0pp2kn9I
Un abrazo,
Los buenos «científicos» de datos son unicornios.
Tienen poco de científicos. Son mentes privilegiadas capaces de sacar conclusiones sintéticas frente a grandes volúmenes de datos.
Son personas muy analíticas, pero al mismo tiempo dueños de una gran intuición.
Deberían llamarse «artistas» de datos. Llamarles «científicos» induce a error y hace que cualquier joven con facilidad para las ciencias crea que puede llegar a ser un buen «científico» de datos…
Lamentablemente no es así.
Muy buen articulo.
Para alguien que esta estudiando Lic. en Sistemas y esta interesado en ingresar a este mundo de Data Science, por donde recomendarían comenzar? Que cursos o lenguajes serian los primeros a aprender?
Muchas gracias.
Hola Ofelia,
gracias por tu comentario. Un proyecto de «Big Data», circunscribe varias etapas. Por lo tanto, no hay una única herramienta que podamos recomendarte. Lo mejor será que puedas ver lugares que te informen de toda la cadena de valor del dato, y donde hay varias herramientas que poder investigar siguiendo todo el procesamiento del dato. Te dejo un artículo que habla de ello y donde verás varias herramientas para cada tarea: https://www.import.io/post/all-the-best-big-data-tools-and-how-to-use-them/
Ánimo con todo.
Saludos,
Buen artículo !!
Buscando sobre el tema he encontrado un artículo interesante sobre el científico de datos en la empresa en este enlace: https://www.marketing-analitico.com/analitica-web/que-es-un-cientifico-de-datos/
Saludos !!
I was looking for something of the same kind.
good information over here, Thanks for sharing the info.
ation over here, Thanks for sharing t
Walmart One Login – Guide For Active & Displaced Walmart Associates
my account access
OneVanilla
JCPenney
YouTecho is a blog created by Tech Junkies, for All the Tech Junkie Community where we share all the trending tech updates and review gadgets/softwares
Kepala Bergetar Tonton Melayu Drama dan Malay Telefilem Terkini Episods.
When visiting the official Pinoy television website, tune in to the Pinoy Tv Channel. This group includes citizens from many countries, however the Philippines are overrepresented. Pinoy features a wide variety of shows, each with its own style and focus.
This is a really informative post on data science.
I had no idea that data science could be used in so many different industries.
The examples in this post really helped me understand the concepts.
I appreciate how clearly the author explained the technical aspects.