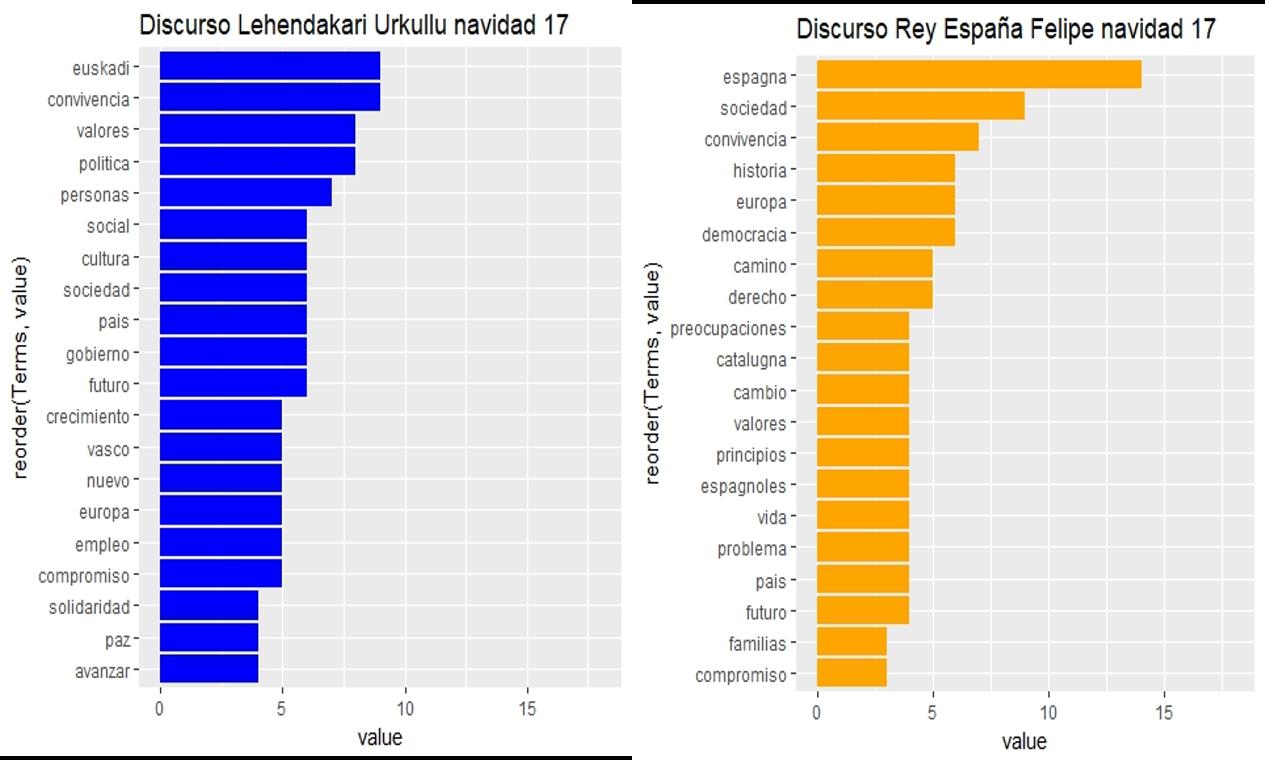
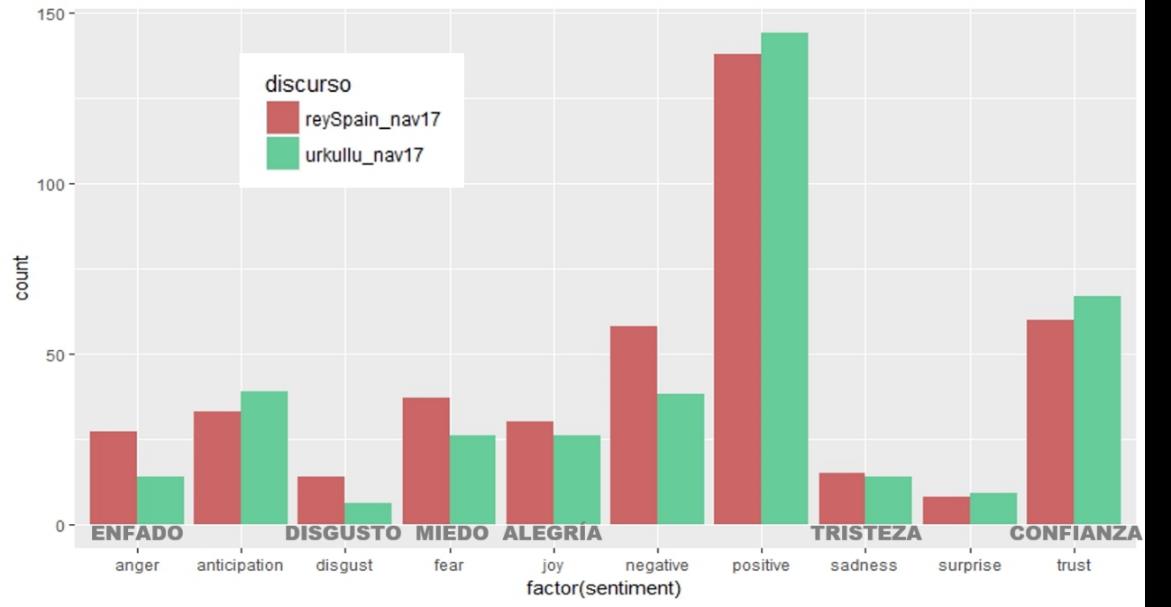
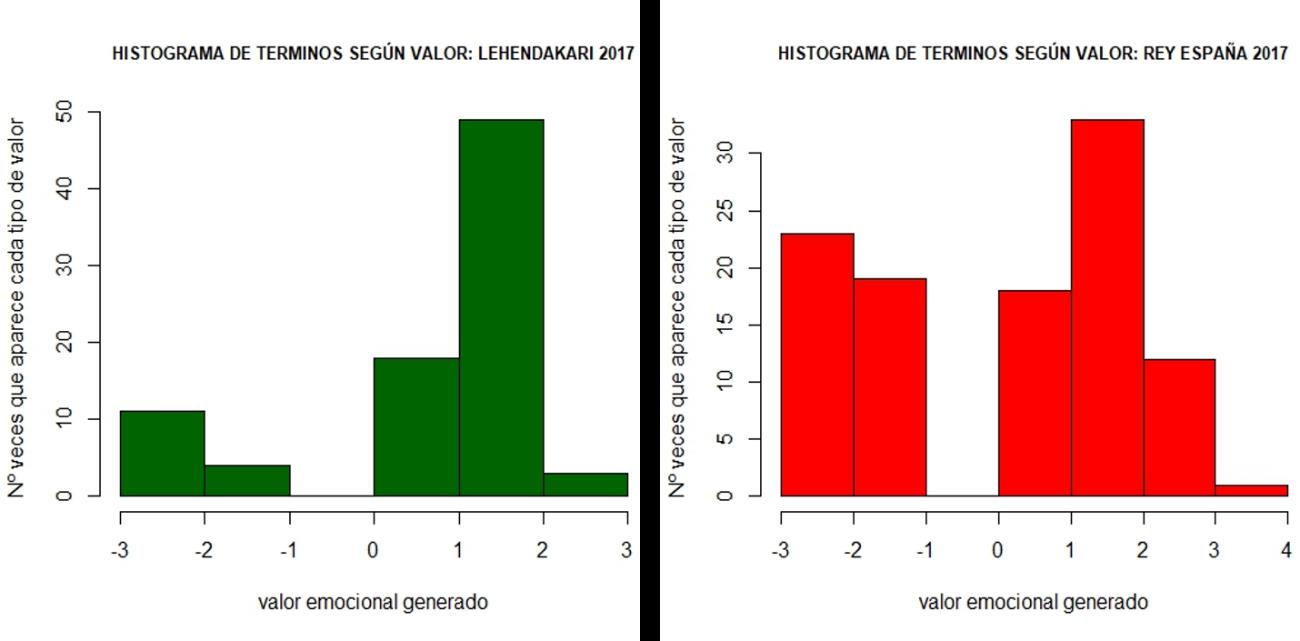
Myriam Abuin Lahidalga*
El Mundial de fútbol acaba de comenzar y con él la recopilación de grandes cantidades de datos sobre pases, faltas, estrategias y rendimiento de cada jugador. Desde 2015 las distintas selecciones han comenzado a utilizar la tecnología incorporando sensores en las camisetas de entrenamiento para recabar datos que, convenientemente interpretados, sirven para encontrar la alineación ganadora o la mejora táctica del equipo.
Pero el uso de los big data no es nuevo en el deporte. Diseñadores y escuderías de Fórmula 1 llevan aplicándola desde la década de los 80. Se trataba de los primeros pasos de la telemetría aplicada al deporte. Los sensores distribuidos a lo largo de todo el monoplaza permiten testar en tiempo real las condiciones del vehículo y pilotaje, y calcular en tiempo real cómo conseguir ventaja frente a los rivales sin detenerse en boxes. Una operación que requiere no sólo un piloto experto, sino una tecnología capaz de gestionar esa ingente cantidad de datos. Pero ¿cómo funciona?

Los circuitos son espacios abiertos, diseñados en parte para minimizar los riesgos cuando se conduce a 300 kilómetros por hora y en parte para liberar de obstáculos las transmisiones de microondas (de radio) necesarias para poner en contacto el equipo con la pista. Sin embargo, algunos de ellos poseen trazados urbanos, como Mónaco o Monza, con túneles, edificios y barreras urbanas que dificultan la propagación de datos. La solución fue dotar a las pistas de un sistema parecido al de la telefonía móvil, garantizando la cobertura con un mínimo retraso de un milisegundo en la recepción. De esta manera los ingenieros de carrera pueden detectar cualquier anomalía, informar al piloto y tomar una decisión inmediata.
Hoy en día, cada monoplaza cuenta con unos doscientos sensores que envían información precisa sobre cuántas veces se acelera o se pisa el freno, cómo está el nivel de combustible o cuál es el desgaste de los neumáticos. Son datos cruciales para planificar una parada técnica que reste los menos segundos posibles a la posición del piloto en la carrera. Todo ello se recoge en un receptor/emisor, aparato que realiza ambas funciones y que además encripta la información recibida, enviándola luego a dos pequeñas antenas situadas en la parte delantera y trasera del monoplaza. A su vez, éstas remiten a un servidor.

Cada circuito cuenta con una zona reservada para cada escudería. No se trata sólo de las salas a pie de pista donde trabajan los mecánicos del equipo, sino de un amplio aparcamiento de camiones en el que se alinean varios remolques con antenas exteriores. Allí está el corazón del sistema: la sala de telemetría. Un potente servidor desencripta los datos recibidos y los prepara para que los ingenieros de cada escudería puedan gestionarlos en forma de gráficos monitorizados en varias pantallas. De este modo pueden contactar con el muro de boxes, donde están los directores de carrera y los mecánicos, en un envío mutuo de información que mejore sus opciones en tiempo real.
Pero la interpretación de esos datos no sólo sirve para mejorar la conducción o variar la estrategia en función de las circunstancias de la carrera, sino también es útil a los ingenieros de diseño, probadores de coches y a los propios pilotos. Estos últimos tienen así una visión precisa de sus errores y posibilidades de mejorar su conducción. Pero ¿cómo convertir todos esos datos en un equipo ganador?

Cada temporada las escuderías pasan muchos meses diseñando los nuevos coches. Aerodinámica, modelos matemáticos, ensayos de los prototipos en el túnel de viento… Pero la teoría no ofrece una exacta simulación de la realidad. Se necesita que el coche ruede por una pista, y tener un circuito de pruebas no está al alcance de todos los equipos. Por ello, los datos recogidos en cada gran premio son estudiados, seleccionados cuidadosamente y volcados en un ordenador que simulará el comportamiento de las piezas y comprobará la validez del nuevo diseño. Es evidente que la información en sí misma no es suficiente, pero sí puede ayudar a corregir hábitos de conducción y observar desde fuera de la pista cómo se comportará el coche en determinadas circunstancias. Por tanto, aquel equipo que sepa interpretar mejor los datos de las simulaciones tendrá muchas más posibilidades de éxito.
Además, los pilotos no tienen por qué probar físicamente el nuevo monoplaza, sino que pueden hacerlo en un simulador parecido al usado en los videojuegos de conducción. Habitualmente consiste en un sillón y una pantalla de ordenador, pero Mercedes y Ferrari construyeron una esfera montada sobre soportes hidráulicos en la que se pueden testar todas las condiciones y todos los circuitos. Otras, como Red Bull, contratan a jugadores de videojuegos para ponerse a los mandos del simulador y dejar a sus pilotos sólo las instrucciones precisas para cada carrera.
Apoyar cada decisión sobre los datos para predecir el comportamiento de los rivales o las condiciones de la carrera no es suficiente, aunque innegablemente importante. Francisco Gago, director de tecnologías digitales de la plataforma de gestión de datos Minsait de Indra, cree que los datos no ofrecen soluciones irrefutables. Y durante los últimos años se ha comprobado que es como dice. En 2010, por ejemplo, durante el Campeonato de Abu Dabi, Ferrari se tomó demasiado en serio los datos recogidos y señaló a Webber como su principal rival, haciendo caso omiso de Vettel, pero fue Vettel quien finalmente ganó la carrera. Esto se debe a que las principales variables presentes en el análisis son escasas, dado que incluyen los neumáticos, el nivel de combustible y las paradas en boxes. En el Campeonato de China de 2016, un error en el pronóstico con respecto a la temperatura de la pista hizo que Ferrari seleccionara neumáticos blandos, lo que le costó la carrera cuando se enfrentaron a los neumáticos medio duros montados por Mercedes.
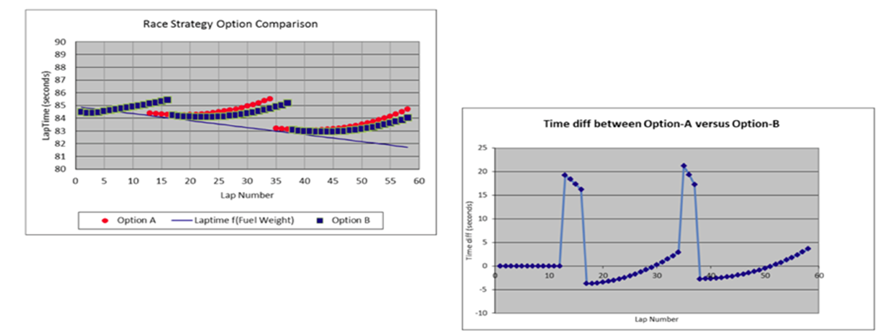
Una de las causas de estas fallas es, en primer lugar, aceptar los resultados de los algoritmos sin cuestionamiento, sin contrastarlos con las voces autorizadas en Fórmula 1. Otra razón es que cualquier imprecisión en el software de procesamiento de datos o en la cadena de transmisión, por pequeña que sea, puede tener un efecto negativo en la estrategia. La tercera y última razón es porque las variables no se contrastan y amplían con otra información. El análisis predictivo basado en big data funciona con información pasada y presente, algo que da un porcentaje de probabilidad, pero no de certeza. Dar a los algoritmos la misma fuerza que los abogados otorgan a las leyes impide que la propia experiencia y criterio del piloto (más las variables que no se tienen en cuenta) brille a la luz del pronóstico dado por los datos.
* Myriam Abuin Lahidalga es alumna del grado de Derecho y Relaciones Internacionales de Deusto. Este post está basado en su trabajo para Media in International Relations.