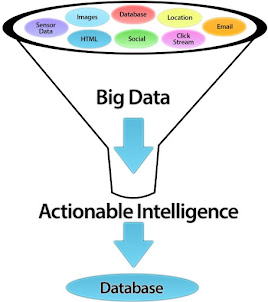
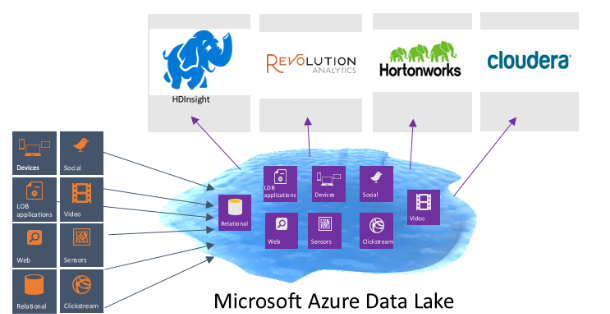
Cuando hablamos de las etapas que componían un proyecto de Big Data, y sus diferentes paradigmas para afrontarlo, una cuestión que cité fue la siguiente:
Si antes decíamos que un proyecto “Big Data” consta de cuatro etapas –(1) Ingestión; (2) Procesamiento; (3) Almacenamiento y (4) Servicio-, con este enfoque, nada más ser “ingestados”, son transferidos a su procesamiento. Esto, además, se hace de manera continua. En lugar de tener que procesar “grandes cantidades”, son, en todo momento, procesadas “pequeñas cantidades”.
Hadoop, que marcó un hito para procesar datos en batch, dejaba paso a Spark, como plataforma de referencia para el análisis de grandes cantidades de datos en tiempo real. Y para que Spark traiga las ventajas que solemos citar (100 vez más rápido en memoria y hasta 10 veces más en disco que Hadoop y su paradigma MapReduce), necesitamos sistemas ágiles de «alimentación de datos». Es decir, de ingesta de datos.
Es el proceso por el cual los datos que se obtienen en tiempo real van siendo capturados temporalmente para un posterior procesamiento. Ese momento «posterior» es prácticamente instantáneo a efectos de escala temporal. Esto se está produciendo mucho, por ejemplo, en el mundo de los sensores y el IoT (Internet of Things). No podemos lanzar alarmas en tiempo real si no contamos con una arquitectura como esta. Muchos sectores son ya los que están migrando a estas arquitecturas de ingesta de datos en un mundo en tiempo real.
Y es que el «tiempo real», el streaming, comienza ya desde la etapa de ingestión de datos. Tenemos que conectarnos a fuentes de datos en tiempo real, como decíamos, para permitir su procesamiento instantéano. En la era del Business Intelligence, e incluso en la era del «Big Data batch», los ETL eran los que permitían hacer estas cosas. Hemos hablado ya de su importancia. Sin embargo, son herramientas que en tiempo real, no ofrecen el rendimiento esperado, por lo que necesitamos alternativas.

Estas son el tipo de cosas que permiten hacer Spark y Storm, cuyo paradigma en tiempo real ya comentamos en su día. Aparecen, junto a ellos, una serie de tecnologías y herramientas que permiten implementar y dar sentido a todo este funcionamiento:
- Flume: herramienta para la ingesta de datos en entornos de tiempo real. Tiene tres componentes principales: Source (fuente de datos), Channel (el canal por el que se tratarán los datos) y Sink (persistencia de los datos). Para entornos de exigencias en términos de velocidad de respuesta, es una muy buena alternativa a herramientas ETL tradicionales.
- Kafka: sistema de almacenamiento distribuido y replicado. Muy rápido y ágil en lecturas y escrituras. Funciona como un servicio de mensajería y fue creado por Linkedin para responder a sus necesidades (por eso insisto tanto en que nunca estaríamos hablando de “Big Data” sin las herramientas que Internet y sus grandes plataformas ha traído). Unifica procesamiento OFF y ON, por lo que suma las ventajas de ambos sistemas (batch y real time). Es un sistema distribuido de colas, el más conocido actualmente, pero existen otros como RabbitMQ, y soluciones en la cloud como AWS Kinesis.
- Sistemas de procesamiento de logs, donde podemos encontrar tecnologías como LogStash, Chukwa y Fluentd.
Con estas principales tecnologías en el menú, LogStash y Flume, se han convertido en las dos principales soluciones Open Source para lo que podríamos bautizar como «ETL en tiempo real». Es decir, para la necesidad de recoger datos en tiempo real. La ingesta de datos como etapa de un proyecto de Big Data.
Y, de este modo, nacen «packs tecnológicos» alternativos al ETL como es EFK, acrónimo de Elastic Search + Flume + Kibana. Se trata de una plataforma para procesar datos en tiempo real, tanto estructurados como no estructurados. Todo ello, con tecnologías Open Source, lo que podría venir a animar a muchas empresas que lean esta noticia, y entiendan el valor que tiene esto para sus seguras necesidades (cada vez más) en tiempo real.
- Elastic Search: motor de búsqueda, orientado a documentos, basado en Apache Lucene.
- Flume: ejcución de procesos de extracción, transformación y carga de datos de manera eficiente.
- Kibana: dashboards en tiempo real, procesando y aprovechando los datos en tiempo real indexados vía Elastich Search.
Con todo esto, quedarían esquemas tecnológicamente muy enriquecidos y útiles para necesidades de negocio como el que se presenta a continuación:
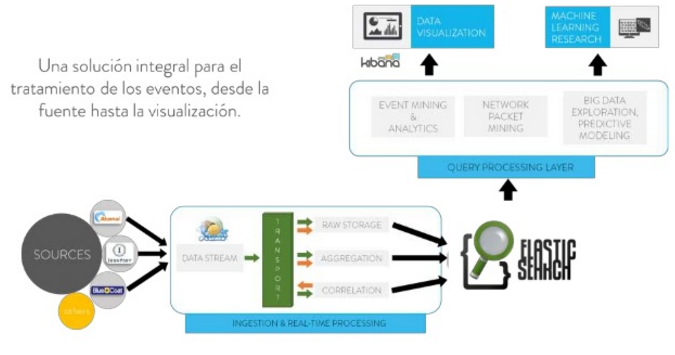
Como podéis apreciar, en estos ecosistemas, los ETL ya no cumplen la función que han venido desempeñando históricamente. Su rendimiento en tiempo real es realmente bajo. Por lo que tenemos que dar un paso más allá. E introducir nuevas tecnologías de ingestión de datos. Kakfa, Flume, Elastic Search, etc., son esas tecnologías. Si tu empresa está empezando a tener problemas con el datamart tradicional, o si la base de datos ya no da mucho más de sí, quizás en este ecosistema tecnológico tengamos la solución.
Nosotros, en nuestro Programa de Big Data, todo esto lo vemos durante 25 horas, montando una arquitectura en tiempo real que dé respuesta a las necesidades de empresas que cada vez necesitan más esto. Las tecnologías de ingesta de datos al servicio de las necesidades de negocios en tiempo real.