El proceso de Extracción (E), Transformación (T) y Carga (L, de Load en Inglés) -ETL- consume entre el 60% y el 80% del tiempo de un proyecto de Business Intelligence. Suelo empezar con este dato siempre a hablar de las herramientas ETL por la importancia que tienen dentro de cualquier proyecto de manejo de datos. Tal es así, que podemos afirmar que proceso clave en la vida de todo proyecto y que por lo tanto debemos conocer. Y éste es el objetivo de este artículo.
La cadena de valor de un proyecto de Business Intelligence la podemos representar de la siguiente manera:

Hecha la representación gráfica, es entendible ya el valor que aporta una herramienta ETL. Como vemos, es la recoge todos los datos de las diferentes fuentes de datos (un ERP, CRM, hojas de cálculo sueltas, una base de datos SQL, un archivo JSON de una BBDD NoSQL orientada a documentos, etc.), y ejecuta las siguientes acciones (principales, y entre otras):
- Validar los datos
- Limpiar los datos
- Transformar los datos
- Agregar los datos
- Cargar los datos
Esto, tradiocionalmente se ha venido realizando con código a medida. Lo que se puede entender, ha traído muchos problemas desde la óptica del mantenimiento de dicho código y la colaboración dentro de un equipo de trabajo. Lo que vamos a ver en este artículo es la importancia de estas acciones y qué significan. Por resumirlo mucho, un proceso de datos cualquiera comienza en el origen de datos, continúa con la intervención de una herramienta ETL, y concluye en el destino de los datos que posteriormente va a ser explotada, representada en pantalla, etc.
¿Y por qué la importancia de una herramienta ETL? Básicamente, ejecutamos las acciones de validar, limpiar, transformar, etc. datos para minimizar los fallos que en etapas posteriores del proceso de datos pudieran darse (existencia de campos o valores nulos, tablas de referencia inexistentes, caídas del suministro eléctrico, etc.).
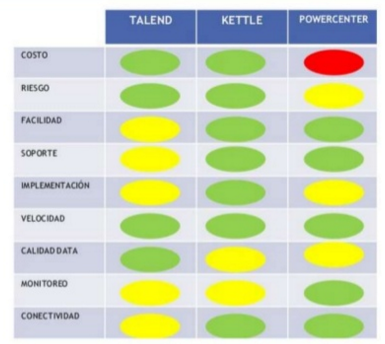
Este parte del proceso consume una parte significativa de todo el proceso (como decíamos al comienzo), por ello requiere recursos, estrategia, habilidades especializadas y tecnologías. Y aquí es donde necesitamos una herramienta ETL que nos ayude en todo ello. ¿Y qué herramientas ETL tenemos a nuestra disposición? Pues desde los fabricantes habituales (SAS, Informatica, SAP, Talend, Information Builders, IBM, Oracle, Microsoft, etc.), hasta herramientas con un coste menor (e incluso abiertas) como Pentaho Kettle, Talend y RapidMiner. En nuestro Programa de Big Data y Business Intelligence, utilizamos mucho tanto SAS como Pentaho Kettle (especialmente esta última), por lo que ayuda a los estudiantes a integrar, depurar la calidad, etc. de los datos que disponen. A continuación os dejamos una comparación entre herramientas:
¿Y qué hacemos con el proceso y las herramientas ETL en nuestro programa? Varias acciones, para hacer conscientes al estudiante sobre lo que puede aportar estas herramientas a sus proyectos. A continuación destacamos 5 subprocesos, que son los que se ejecutarían dentro de la herramienta:
- Extracción: recuperación de los datos físicamente de las distintas fuentes de información. Probamos a extrar desde una base de datos de un ERP, CRM, etc., hasta una hoja de cálculo, una BBDD documental como un JSOn, etc. En este momento disponemos de los datos en bruto. ¿Problemas que nos podemos encontrar al acceder a los datos para extraerlos? Básicamente se refieren a que provienen de distintas fuentes (la V de Variedad), BBDD, plataformas tecnológicas, protocolos de comunicaciones, juegos de caracteres y tipos de datos.
- Limpieza: recuperación de los datos en bruto, para, posteriormente: comprobar su calidad, eliminar los duplicados y, cuando es posible, corrige los valores erróneos y completar los valores vacíos. Es decir se transforman los datos -siempre que sea posible- para reducir los errores de carga. En este momento disponemos de datos limpios y de alta calidad. ¿Problemas?ausencia de valores, campos que tienen distintas utilidades, valores crípticos, vulneración de las reglas de negocio, identificadores que no son únicos, etc. La limpieza de datos, en consecuencia, se divide en distintas etapas, que debemos trabajar para dejar los datos bien trabajados y limpios.
- Depurar los valores (parsing)
- Corregir (correcting)
- Estandarizar (standardizing)
- Relacionar (matching)
- Consolidar (consolidating)
- Transformación: este proceso recupera los datos limpios y de alta calidad y los estructura y resume en los distintos modelos de análisis. El resultado de este proceso es la obtención de datos limpios, consistentes y útiles. La transformación de los datos se hace partiendo de los datos una vez “limpios” (la etapa 2 de este proceso)(. Transformamos los datos de acuerdo con las reglas de negocio y los estándares que han sido establecidos por el equipo de trabajo. La transformación incluye: cambios de formato, sustitución de códigos, valores derivados y agregados, etc.
- Integración: Este proceso valida que los datos que cargamos en el datawarehouse o la BBDD de destino (antes de pasar a su procesamiento) son consistentes con las definiciones y formatos del datawarehouse; los integra en los distintos modelos de las distintas áreas de negocio que hemos definido en el mismo.
- Actualización: Este proceso es el que nos permite añadir los nuevos datos al datawarehouse o base de datos de destino.
Para concluir este artículo, os dejamos la presentación de una de las sesiones de nuestro Programa de Big Data y Business Intelligence. En esta sesión, hablamos de los competidores y productos de mercado ETL.

