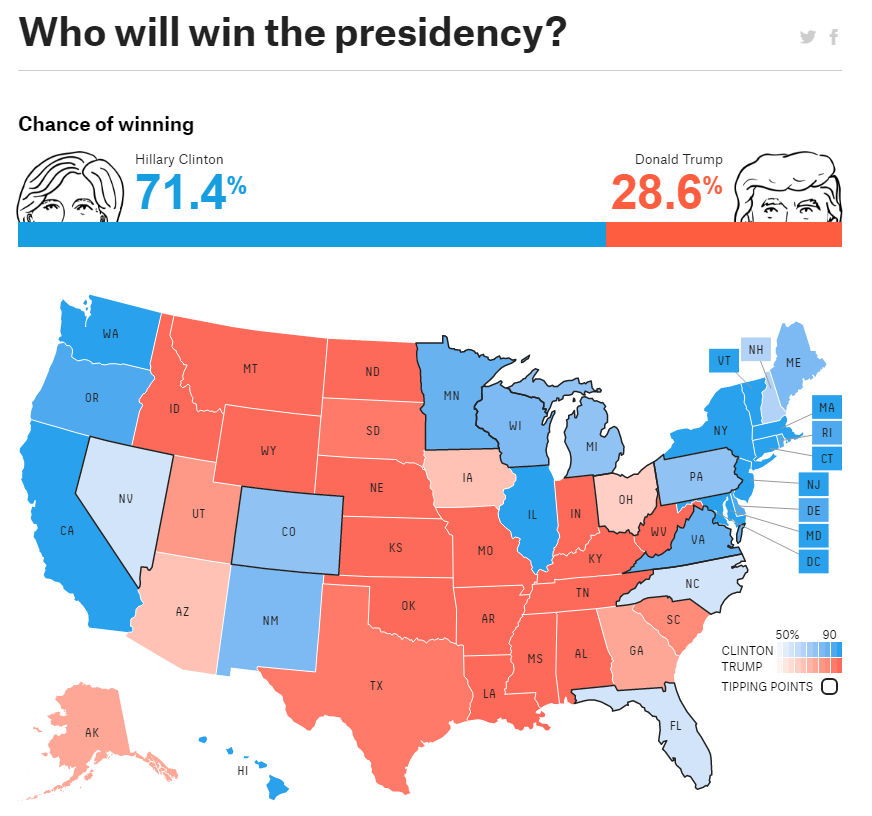
Quizás ya hayan leído alguna noticia al respecto. Suelen ser noticias bastante «trágicas» o «extremas». Que, como siempre, difícilmente llegará a darse. Aunque sí marcan tendencia, y sobre todo generan conversación. Me refiero a noticias que hablan de software, de algoritmos, que escriben por sí solos noticias, artículos de deporte o incluso sentencias o textos de defensa de acusados. IBM Watson, incluso ha creado ya un trailer:
Este tipo de piezas de software, están dando un paso más allá, y están empezando a entrar en el mundo del entretenimiento. En cierto modo, ese trailer creado por IBM Watson no deja de ser una primera aproximación a cómo tratar de crear contenido que nos pueda entretener a los humanos. Pero, creado, de manera automática. Es decir, sin dedicar tiempo de creatividad y entendimiento del cerebro humano para ello. Esto sí que es nuevo. Hasta la fecha habíamos tratado de aproximarnos a ello, pero no conseguido.
Y dado que el mercado del entretenimiento es muy jugoso, ya hay mucha gente haciendo cosas. En este artículo, podéis ver como Max Deutsch, utilizando un modelo de LSTM Recurrent Neural Network (algoritmo de aprendizaje cognitivo), y empleando como datos de entrada los textos de los primeros cuatro libros de Harry Potter, fue capaz de producir un nuevo capítulo. El capítulo lo pueden encontrar en el enlace que ponía antes. Hizo lo mismo para producir un capítulo de la serie Silicon Valley de HBO o para guiones para Expediente X. Twitter, para mucho del texto automático que genera (sí, mucho del que leeis), emplea cadenas de Markov. Es decir, empleando los textos que se mueven en dicha red, analiza qué palabras son más probables de aparecer de seguido a otras en el material fuente. El escritor/autor, poco tiene que decir. Las cadenas de Markov hacen todo por él o ella.
Prueben ustedes mismos. Navegando un poco por la red, he encontrado en GitHub este algoritmo creado por Jamie Brew, escrito en Python, y que permite entrenar modelos a partir de textos que le demos. Si quisiéramos crear cuentos para nuestros hijos, podéis introducir en la carpeta de textos aquellos con los que queráis que el software aprenda sus estructuras, para que sea capaz, a partir de ellas, de construir nuevas historias.
Este algoritmo me ha llamado la atención porque utiliza un enfoque híbrido algoritmo + humano. Por eso mismo decía al comienzo del artículo que suele ser difícil quedarse en un extremo o en otro. Brew visualiza estos algoritmos como un soporte a la creación humana. Que es, por cierto, como creo que más valor cogen estos algoritmos. En lugar de generar directamente las palabras, sugiere una lista de palabras, para que el creador elija la que más le gusta. Este modelo, en cierto modo no deja de ser diferente a cómo funcionamos los que escribimos o creamos en la vida real. Que nos quedamos pensando cuál es la mejor opción a seguir mientras vamos escribiendo. Es decir, es un proceso gradual que se nutre de pasos anteriores. Como las cadenas de Markov, que por eso son tan buen apoyo.
Este modelo de aproximación híbrido me gusta porque no hace un «commodity» la creatividad humana. Algo nos tiene que quedar a nosotros 🙂 Y, de hecho, ese «momento Eureka» que solemos tener al crear, es difícil de automatizar en un software. En un algoritmo. Por eso mismo, un modelo en el que en lugar de externalizar la creatividad, tenemos un algoritmo que nos ayuda en la parte más mecánica (darnos un conjunto de «mejores» alternativas a elegir para ir creando las diferentes piezas del puzzle final). Siempre habrá un humano por detrás, una mano artística.
De esta manera, no vemos el mundo de la inteligencia artificial, de los modelos como algo que compite contra nosotros. Que es lo que llevo diciendo mucho tiempo. Básicamente, porque esos discursos catastróficos o triunfalistas, ya digo serán luego difíciles de ser implementados. El software es una herramienta que empleamos para hacer mejor nuestro trabajo. Para crearlo, necesitamos saber muchas cosas (tecnología, estadística, enfoque a aplicación -negocio-). Pero la creatividad, de momento, no hemos conseguido externalizarla. Y si queremos hacer cosas de calidad, es probable que ese monopolio artístico siga siendo del ser humano.