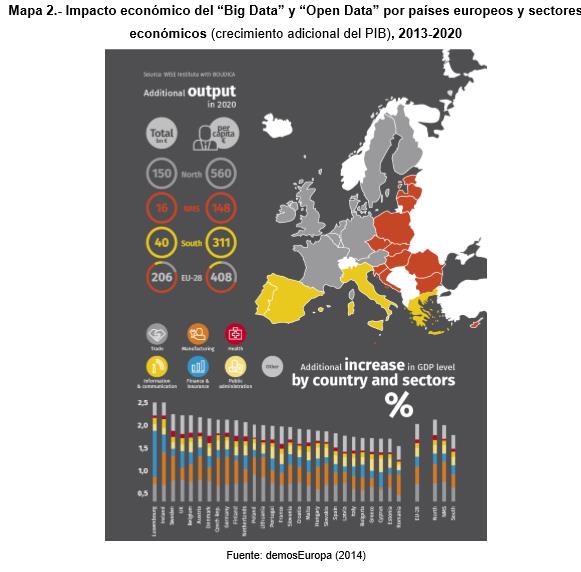
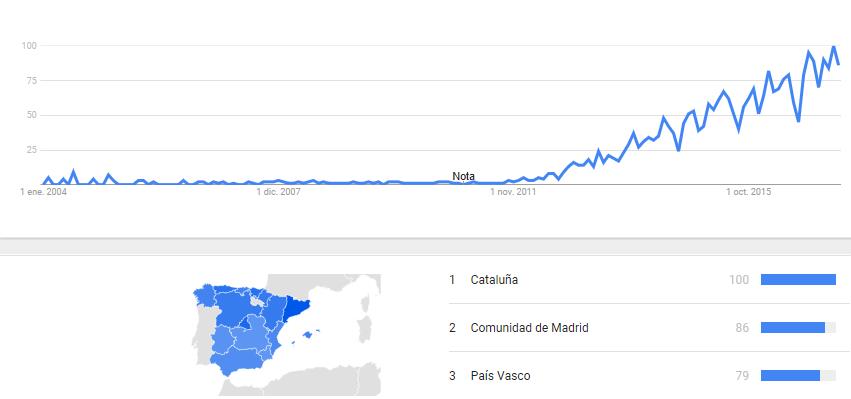
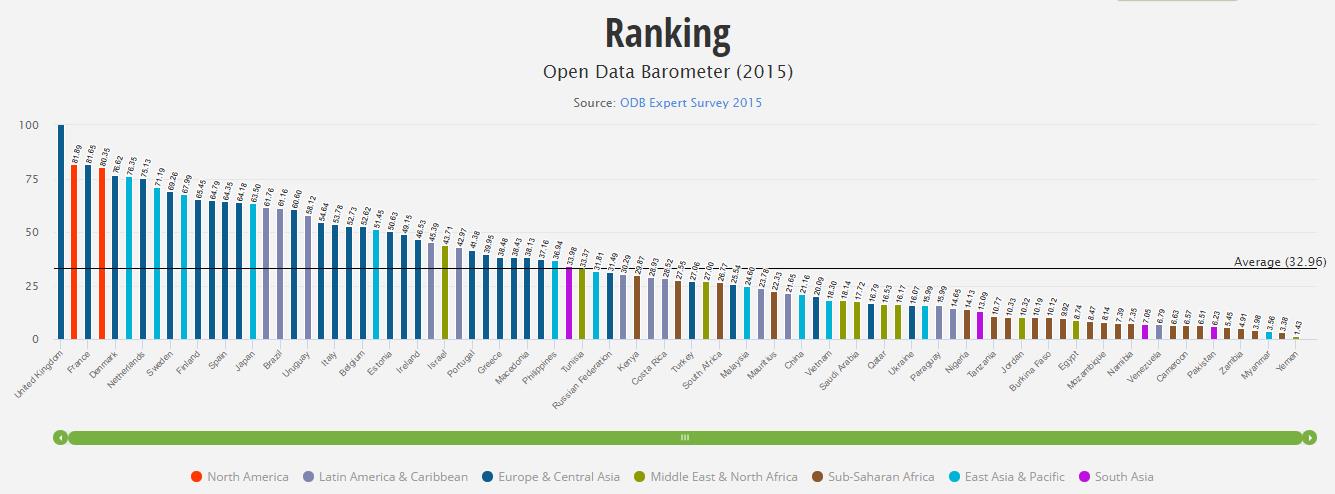
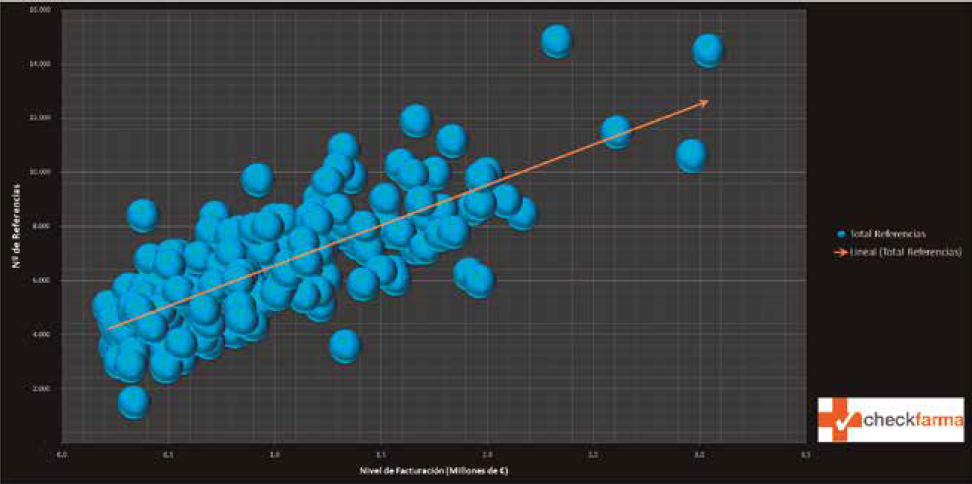
(Artículo escrito por Izaskun Larrea, alumna de la promoción de 2017 en el Programa en Big Data y Business Intelligence en Bilbao)
Si desea averiguar cómo el Big Data está ayudando a conseguir un mundo mejor, no hay mejor ejemplo que los usos que se encuentran en la atención sanitaria.
La última década ha sido testigo de enormes avances en la cantidad de datos que habitualmente generamos y recopilamos, así como nuestra capacidad de utilizar la tecnología para analizarla y entenderla. La intersección de estas tendencias es lo que llamamos «Big Data» y está ayudando a las empresas de todas las industrias a ser más eficientes y productivas.
La asistencia sanitaria no es diferente. Además da mejorar los beneficios y reducir los gastos generales, Big Data en la atención sanitaria se utiliza para predecir epidemias, curar enfermedades, mejorar la calidad de vida y evitar muertes evitables. Con la población mundial en aumento y con la población cada día más longeva, los modelos de tratamiento están cambiando rápidamente, y muchas de las decisiones están siendo impulsadas por los datos. Actualmente, la necesidad es saber cada día más sobre los pacientes, desde que nacen – recogiendo señales de advertencia de una enfermedad grave en una etapa suficientemente temprana para que el tratamiento sea más eficiente que si no hemos precedido los antecedentes del individuo.
Así que para crear un proyecto Big Data en la atención sanitaria, vamos a empezar por el principio – antes de que se detecte la enfermedad.

Es mejor prevenir que curar
Los teléfonos inteligentes fueron sólo el comienzo. Con las aplicaciones que les permiten ser utilizados como podómetros para medir cuánto caminas en un día, a los contadores de calorías para ayudarte a planificar tu dieta, millones de nosotros estamos utilizando la tecnología móvil para conseguir un estilo de vida saludable. Más recientemente, ha surgido un flujo constante de dispositivos portátiles dedicados como Fitbit, Jawbone y Samsung Gear Fit que permiten realizar un seguimiento de su progreso y cargar sus datos para ser recolectados junto con los demás datos.
En un futuro muy cercano, podremos utilizar estos datos con su médico quien lo utilizará como parte de su caja de herramientas de diagnóstico. Incluso aunque no esté enfermo, el acceso a las bases de datos de Big data, conseguir la información sobre el estado de la salud los pacientes de Osakidetza permitirá que los problemas sean afrontados antes de que ocurran, y se tomen decisiones terapéuticas o educativas, permitiendo que Osakidetza consiga información privilegiada.
Estos proyectos de Big Data, a menudo son creados por asociaciones entre profesionales médicos y de Big Data, con la prioridad de mirar hacia el futuro e identificar problemas antes de que sucedan. Un ejemplo recientemente creado es el proyecto Pittsburgh Health Data Alliance, que pretende tomar datos de diversas fuentes (tales como registros médicos y datos genéticos e incluso uso de medios sociales) para dibujar un cuadro completo del paciente. Con el fin de ofrecer un paquete de atención médica adaptada.
Los datos de los pacientes no serán tratados aisladamente. Se comparará y analizará junto a otros, destacando amenazas y problemas específicos a través de patrones que surgen durante el análisis. Esto permite que con este sofisticado modelo predictivo que se crea, un médico será capaz de evaluar el resultado probable de cualquier tratamiento que él o ella está considerando, respaldado por los datos de otros pacientes con las mismas condiciones, factores genéticos y estilo de vida.
Programas como este son el intento de la industria para hacer frente a uno de los mayores obstáculos en la búsqueda de la salud basada en Big Data: la industria médica recolecta una gran cantidad de datos, pero a menudo se encuentra en archivos y controlados por diferentes direcciones médicas, hospitales, clínicas, y los departamentos administrativos.
Otra asociación es entre Apple y IBM. Las dos compañías están colaborando en una gran plataforma de salud de datos que permitirá a los usuarios de iPhone y Apple Watch compartir datos con el Servicio de Salud Watson Health de IBM. El objetivo es descubrir nuevos conocimientos médicos a partir de cruzar en tiempo real la actividad y los datos biométricos de millones de pacientes potenciales.
En conclusión, existe un gran potencial para desarrollar una atención sanitaria más selectiva, de amplio alcance y eficiencia mediante la explotación del Big Data. Sin embargo, también se ha demostrado que el campo de la salud tiene algunas características muy específicas y desafíos que requieren de un esfuerzo dirigido y de la investigación para alcanzar todo su potencial.