Nuestra actividad alrededor del mundo del Big Data sigue creciendo. La Universidad de Deusto, a través de DeustoTech (el equipo MORElab (envisioning future internet)), coordinará el proyecto europeo European Data Incubator (EDI) por valor de 7,7 millones de euros para potenciar la creación de 140 nuevas empresas que exploten las tecnologías de Big Data y dar así solución a los retos de grandes proveedores de datos en Europa.
European Data Incubator
Este proyecto ha recibido financiación del programa de investigación e innovación Horizonte 2020 de la Unión Europea en virtud del acuerdo de subvención n° 779790.
Esta iniciativa busca, como decíamos anteriormente, atender a la creciente necesidad de contar con emprendedores de datos que saquen valor de los mismos a través de la ciencia de datos. No se trata solo de dominar un conjunto de tecnologías y herramientas, como hemos señalado en este blog con anterioridad, sino de aprender cómo poder aplicarlos para resolver problemas de negocio. Es difícil hoy en día encontrar ese perfil que no solo tenga una visión técnica, sino que también tenga esa visión de negocio para aplicarlo a diferentes realidades de empresa.
Por todo ello, el equipo de DeustoTech Morelab, cuenta con el apoyo de nuestro Deusto Entrepreneurship Center, que tratará de impulsar y trasladar a los participantes las skills necesarias para explotar el gran volumen de datos que han aparecido en nuestra sociedad derivado de su digitalización. Es decir, que podamos contar con más perfiles de científicas y científicos de datos, esos perfiles de los que tanto se habla, y no sabemos muchas veces cómo de claro está que se entienda lo que es.
El perfil del científico o científica de datos (Fuente: https://upxacademy.com/wp-content/uploads/sites/8/2016/11/Data-Scientist.png)
Si os interesa conocer qué oportunidades os ofrecemos con esta iniciativa de desarrollo de perfiles de Big Data para el emprendimiento y la puesta en valor de los datos, os invitamos a participar el próximo 10 de enero en el evento donde daremos a conocer todos los detalles. El catalizador europeo de la innovación y promoción de start-ups en Big Data llega a Deusto! Apúntate aquí a nuestro European Data Incubator.
European Data Incubator (http://mailchi.mp/60944d96e91a/edi-839529?e=a8568517ec)
The question lies at the heart of our campaign, which argues that government’s role should be to collect and administer high-quality raw data, but make it freely available to everyone to create innovative services». “Free our Data campaign”. Reino Unido. Junio de 2006.
¿La Seguridad Social será solvente para nuestros nietos? ¿Cuál es el impacto de las nuevas inversiones en salud, educación y carreteras? ¿Cuál será la proyección de las políticas en la Industria 4.0 de la C.A. de Euskadi? Estas son, algunas de las preguntas que se pueden resolver con Big Data.
El Big Data es una combinación de la información masiva de datos y los recursos tecnológicos. Al igual que las empresas, las administraciones públicas (AAPP) pueden conocer mucho más a los ciudadanos, lo que leen, lo que perciben, etc.
La combinación e implantación de políticas de Gobierno Abierto, “Big Data” y “Open Data” pueden brindar importantes y sustanciosos beneficios a los ciudadanos. Estudios como demosEuropa (2014) concluyen que los países que apuestan por la transparencia de sus administraciones públicas mediante normas de buen gobierno cuentan con instituciones más fuertes, que favorecen la cohesión social.
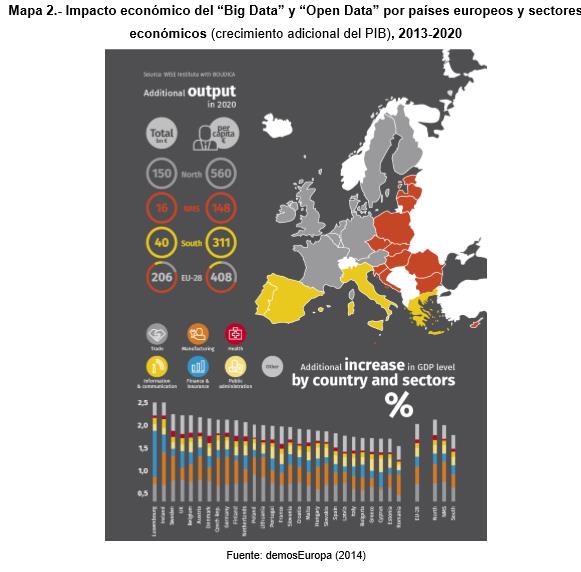
Según un estudio realizado en la Unión Europea la implementación de las políticas de Gobierno Abierto “Big Data” y “Open Data” tendrán un efecto considerable. El impacto dependerá, lógicamente, del grado de extensión y desarrollo de nuevas tecnologías en cada economía y sector productivo, así como del grado de dependencia y utilidad de dicha información en cada uno de ellos. De hecho, aunque se prevé un impacto positivo en todos los sectores económicos, las ramas de actividad sobre las que se espera un mayor impacto serán la industria manufacturera y el comercio, seguidas de las actividades inmobiliarias, el sistema sanitario y la administración pública (ver siguiente mapa).
Impacto económico Big Data y Open Data en la UE
En cuanto al impacto geográfico, conviene llamar la atención sobre el caso particular de España, ya que será uno de los países en los que menos repercusión económica tenga el “Big Data” y “Open Data”. Ello se debe al todavía limitado desarrollo de este tipo de tecnologías que permitan aflorar adecuadamente los beneficios que pueden llegar a reportar a la economía, así como de una mayor representatividad de las PYMES en el tejido empresarial español. Ahora bien, el hecho de que el impacto estimado del “Big Data” y “Open Data” sea mayor en los países del norte europeo, donde se han desarrollado mucho más estas tecnologías, pone de manifiesto que éstas ofrecen rendimientos crecientes que conviene aprovechar, independientemente del posicionamiento de cada uno de los países.
Impacto económico del Big Data y Open Data para países europeos y sectores económicos 2013-2020
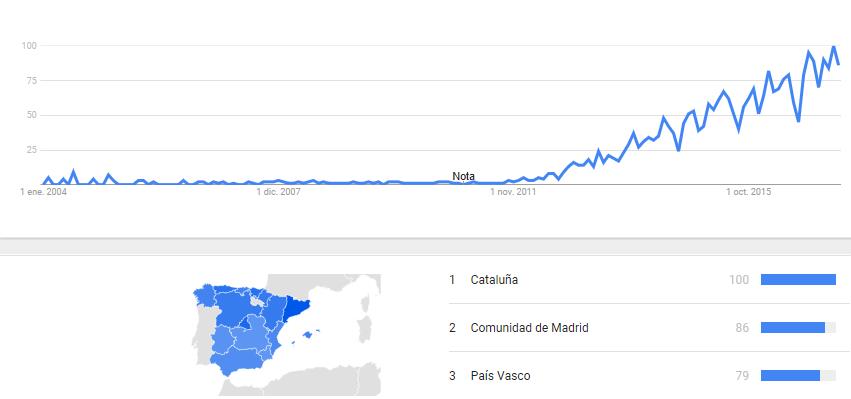
Aunque podemos percibir que la C.A. de Euskadi puede tener un comportamiento similar a las regiones del norte y centro de Europa visualizando el siguiente gráfico, dónde se refleja el interés de los ciudadanos por el Big Data.
Fuente: Google. Los números reflejan el interés de búsqueda en relación con el mayor valor de un gráfico en una región y en un periodo determinados. Un valor de 100 indica la popularidad máxima de un término, mientras que 50 y 0 indican una popularidad que es la mitad o inferior al 1%, respectivamente, en relación al mayor valor.
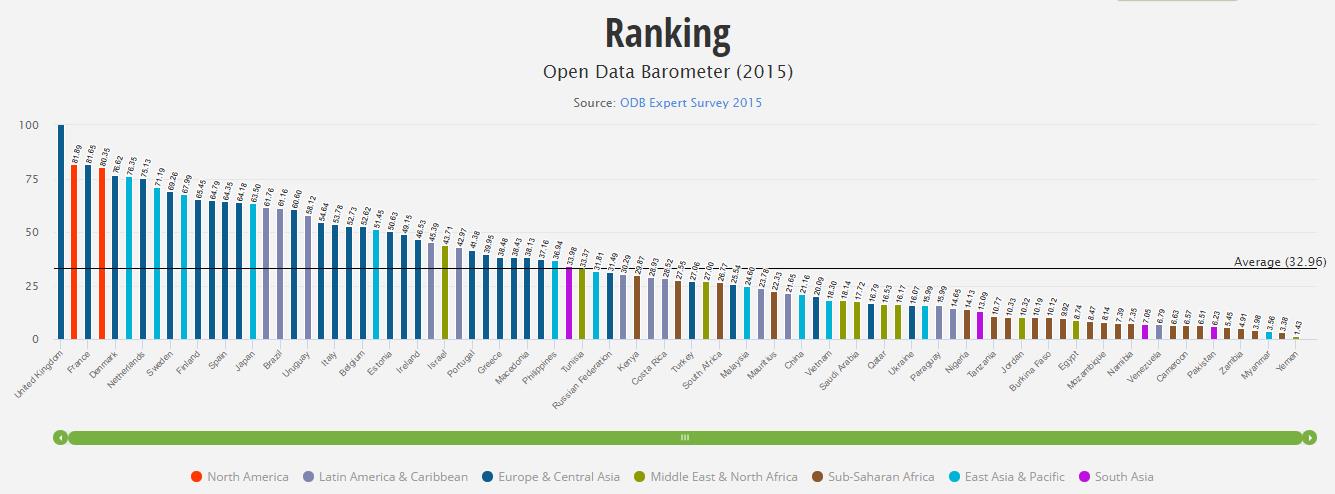
Un elevado número de países han planteado iniciativas de “Open Data”, con el objetivo de incentivar la actividad económica, favorecer la innovación y promover la rendición de cuentas por parte de las AA.PP. Estas iniciativas en absoluto se limitan a los países más avanzados, sino que se están aplicando en múltiples territorios como herramienta de desarrollo económico, como es el caso de India. No obstante, la formulación de buenas prácticas requiere una selección de los principales referentes a escala internacional. Para ello, es posible analizar estudios recientes como, por ejemplo, el Barómetro elaborado por la World Wide Web Foundation.
Open Data Barometer
Reino Unido es el país más avanzado en materia de “Open Government Data” (OGD), tanto en lo que se refiere a la adaptación de sus instituciones, ciudadanos y tejido empresarial, como en la implementación de iniciativas públicas y en el impacto conseguido por las mismas.
El Reino Unido es reconocido ejemplo como uno de los principales referentes a escala internacional en materia de Gobierno Abierto. Sus actividades en torno a la liberación de datos comenzaron en 2006, a instancias de diversas campañas impulsadas por la sociedad civil y los medios de comunicación (como “Free our Data”), y ha logrado mantener un claro apoyo a estas estrategias tanto por parte de los últimos Primeros Ministros como de los principales partidos políticos británicos.
Entre los objetivos de la estrategia de apertura de datos de Reino Unido destaca la importancia atribuida a la innovación y a la dinamización económica que estas iniciativas pueden favorecer. En este sentido, se ha creado un organismo no gubernamental, el Open Data Institute (de financiación público-privada), cuya misión específica es apoyar la creación de valor económico a partir de los datos puestos a disposición de ciudadanos y empresas. Asimismo, las distintas áreas de la Administración han recibido el mandato de diseñar estrategias propias de apertura de datos, incluyendo acciones específicas que incentiven el uso de sus datos y la realización de informes públicos periódicos sobre sus avances en este ámbito.
Por otra parte, el Reino Unido ha puesto en marcha soluciones que tratan de contribuir a resolver los problemas que surgen al publicar grandes volúmenes de datos correspondientes a áreas de actividad o responsabilidad muy diversa. En este sentido, cabe subrayar:
La creación de los Sector Transparency Boards en diversos departamentos de la Administración. Estos grupos de trabajo cuentan con la participación de representantes de la sociedad civil y de las empresas, y tienen como objetivo canalizar las solicitudes de datos y orientar al Gobierno sobre las prioridades a seguir para liberar nuevos conjuntos de datos.
El desarrollo de programas de formación, competiciones y eventos diseñados para incentivar el uso de datos públicos por parte de la sociedad civil.
La asignación de financiación pública a programas dirigidos a incrementar el aprovechamiento de los datos liberados por parte del tejido empresarial.
Asimismo, se observan esfuerzos dirigidos a incrementar la calidad, estandarización y facilidad de explotación de los datos distribuidos (como los derivados del servicio cartográfico, el registro catastral, el registro mercantil).
A estas alturas creo que todas las personas que estamos en el mundo profesional moderno hemos oído hablar de Big Data, Internet de las cosas, Industria 4.0, Inteligencia Artificial, Machine learning, etc.
Mi reflexión nace de ahí, del hecho innegable de que en estos últimos…¿cuánto? ¿5, 10, 15, 20 años? la presencia de internet y lo digital en nuestras vidas ha crecido de manera exponencial, como un tsunami que de manera silenciosa ha barrido lo anterior y ha hecho que sin darnos cuenta, hoy no podamos imaginar la vida sin móvil, sin GPS, sin whatsapp, sin ordenador, sin internet, sin correo electrónico, sin google, sin wikipedia, sin youtube, sin Redes Sociales,…Basta mirar a nuestro alrededor para ver un escenario inimaginable hace pocos años.
Hasta aquí nada nuevo, reflexiones muy habituales. Pero yo quería centrarme en un aspecto muy concreto de esta revolución en la que estamos inmersos, yo quería poner encima de la pantalla ( 😉 ) el valor económico de los datos y los nuevos modelos de negocio que esto está trayendo y va a traer consigo, con nuevos servicios, agentes y roles, actualmente inexistentes, que deberán de ser claramente regulados, tanto a través de las leyes, como sobre todo, en las compraventas y contratos entre privados. Y para ello, es importante que vayamos pensando en ello.
La gran pregunta
¿De quién es la propiedad de un dato? ¿Quién tiene la capacidad de explotar y sacar rentabilidad de los datos, tanto directamente como vendiéndolos a terceros?
Es una pregunta compleja con implicaciones legales que cómo he dicho habrá que desarrollar, pero la realidad es que, hoy por hoy, el dato lo explota quien sabe cómo hacerlo y quién tiene la capacidad tecnológica y económica para hacerlo: léase los gigantes de internet, los grandes fabricantes tecnológicos, las operadoras de telecomunicaciones, la banca y aseguradoras, grandes distribuidores, fabricantes de automóviles, etc., entre otros. Aparte está el sector público que se supone que va a actuar en este proceso, de manera neutral, velando por la privacidad de los datos y compartiendo todo lo publicable a través del open-data para la libre explotación por parte del sector privado.
Volvamos al valor del dato. Hace unos meses veía en youtube una entrevista a un Socio de Accenture que contaba, hablando sobre el bigdata, que en una comida que había tenido días antes con un Consejero de una Aseguradora, este Socio le había transmitido su sorpresa por la reciente compra de un hospital por parte de la aseguradora, ya que solo veía pérdidas y activos obsoletos…..…..a lo que el Consejero le contestó: “Ya lo sabemos, pero su valor es un intangible…estamos pagando por la información de sus pacientes”. Dichos datos iban a poder tener un doble (al menos) valor para la aseguradora, el primero, la explotación directa de los datos a través de algoritmos de machine learning que le permitirían el ajuste de los perfiles de riesgo de sus clientes y otro para comercializarlos y vendérselos, por ejemplo, a una farmacéutica.
Esto es un pequeño ejemplo de lo que ya está pasando, y no sólo en EEUU donde parece que estos temas van muy por delante, sino en nuestro entorno más cercano, donde las grandes empresas del tipo que he comentado, están comprando y vendiendo datos de clientes y usuarios.
Podríamos hablar también del caso clarísimo de las operadoras de móvil o de la banca que disponen del detalle de toda la vida de sus clientes, dónde van, con quién hablan, en qué y dónde gastan,..
Esto no es una crítica ni una denuncia porque realmente no están haciendo nada ilegal ni falto de ética, sino simplemente invertir mucho y ganar todo el dinero que pueden. Seguro que están respetando los datos personales, que sí están regulados por la LOPD, pero sí es verdad que todo esto está ocurriendo gracias a la falta de cultura digital y de conciencia del valor del dato de los usuarios-ciudadanos, que no dudamos en aceptar/firmar, sin mirar, los acuerdos de uso que nos ponen delante, con tal de poder utilizar esos servicios digitales que se han convertido en “imprescindibles” para nosotros.
Yendo al caso concreto del sector del automóvil. Hace poco leía la biografía de Elon Musk, fundador de TESLA, entre otras empresas, que es uno de los fabricantes de coches eléctricos más innovadores y digitalizados. En el libro contaba como dotan a sus coches de un complejo sistema de sensorización conectado a su central, con el que monitorizan el desempeño de cada elemento del coche así como el uso del mismo, ofreciendo a sus clientes un servicio de anticipación de necesidades y prevención de incidencias, totalmente transparente para los clientes, que pueden llegar a encontrarse, por ejemplo, como se les presenta a las 9 de la mañana en casa un técnico de TESLA para entregarles un coche de sustitución porque van arreglar el sistema de aire acondicionado que estaba empezando a desajustarse, cuando el usuario no había siquiera notado nada, o que al arrancar el coche por la mañana se les muestra en la pantalla del coche, ofertas de un supermercado al que suelen ir o de una hamburguesería que está camino al trabajo….todo esto está ocurriendo ya.
se les presenta a las 9 de la mañana en casa un técnico de TESLA para entregarles un coche de sustitución porque van arreglar el sistema de aire acondicionado que estaba empezando a desajustarse, cuando el usuario no había siquiera notado nada
Hablando de industria 4.0…., ¿podría un fabricante de maquinaria industrial ofrecer a sus clientes su producto ya sensorizado, de manera que pueda monitorizar y explotar centralizadamente los datos de funcionamiento de todas las máquinas instaladas en distintos clientes con el consiguiente incremento de la información sobre su uso que eso supone, y ofrecer directamente, o a través de una tercera empresa a la que venda esa información, servicios de mantenimiento preventivo personalizado u optimización de consumos energéticos a sus clientes? ….Todo esto y mucho más se puede hacer y se hará (si no se está haciendo ya..).
Y vuelvo al asunto que planteaba, ¿de quién es la información registrada sobre los hábitos de vida/fabricación de esos clientes?¿del fabricante que ha instalado los sensores y elementos de comunicación en el coche/máquina que permiten el registro, digitalización, transporte y explotación de los datos, o…. del cliente que es quién genera realmente el contenido?¿Podría un cliente negarse a facilitar esos datos, parece que sí, pero mejor aún, ¿podría un cliente quedarse con una parte de los beneficios que, por ejemplo, TESLA pueda estar obteniendo de la venta de sus datos a los comercios de la zona para que hagan sus ofertas o el fabricante de maquinaria pueda estar obteniendo de la venta de datos a terceros para que ofrezcan servicios de mantenimiento u optimización?
¿Podrán existir intermediarios de datos que nos gestionen y rentabilicen la información que generamos, de manera similar a como hacen los gestores de banca con nuestro dinero?
Se avecina un terreno de juego nuevo, con nuevas reglas por construir y con un enorme potencial de negocio para quienes sean capaces de entender antes sus posibilidades y desarrollar nuevos modelos de explotación y servicio, y tanto las personas como las empresas debemos, al menos, empezar a ser conscientes de nuestro valor y papel en todo esto.
Valor económico de los datos (Fuente: http://www.centrodeinnovacionbbva.com/sites/default/files/cibbva-el-valor-de-los-datos-para-el-consumidor.jpg)
Big Data y Dilbert (Fuente: http://www.bigdata-madesimple.com/wp-content/uploads/sites/8/2015/01/bigdata-knows-everything.jpg)
NINO y GIGO (Nothing in, Nothing Out, Gargabe in, Garbage Out). Estos dos paradigmas son mucho más ilustrativos de lo que parecen. Aquí es donde yo suelo hablar del concepto «dato relevante«. El primero de ellos, básicamente refleja una realidad en la que por mucho que tengamos un gran modelo o herramienta, si los datos de entrada, no son buenos, no podremos hacer nada. Y lo mismo, si los datos de entrada no son de buena calidad.
Es por ello que creo en ocasiones es bueno hablar de las expectativas que el Big Data ha venido a generar, y lo que luego efectivamente se ha convertido en realidad. Se han generado estos año muchas expectativas con Google y Facebook y lo que supuestamente saben de nosotros. Saben más que el resto, sin duda. Pero, suavicemos el discurso. No saben todo.
¿Por qué? Pues porque el concepto de «dato relevante» no siempre es alcanzado. Fijense en la siguiente representación gráfica:
Datos relevantes para proyectos de Big Data (Fuente: https://media.licdn.com/mpr/mpr/shrinknp_800_800/AAEAAQAAAAAAAAIEAAAAJGRhNWYzODhmLTdhZjItNDYxMS04MTY2LWZmMjFmNjgyYjg5ZQ.png)
Como se puede apreciar los datos más relevantes están alejados de lo que hoy todavía las empresas disponen. Incluso en las grandes empresas tecnológicas de Internet. La horquilla tradicional de datos relevantes/datos totales se mueve entre el 10% y el 15%. Las empresas disponen de muchos datos demográficos (si se fijan, sobre los que pivotan la gran mayoría de noticias), pero apenas saben nada sobre nuestras actitudes o necesidades, por ejemplo. Se aproximan con modelos sencillos. De ahí, que muchas de las expectativas que se han venido generando con el «Big Data», luego las tratas de aterrizar, y se vuelven complicadas.
No es lo mismo los datos demográficos, que los sociológicos, de comportamiento, de actitud o de necesidades. El valor incrementa con el orden en la frase anterior. Pero normalmente construimos discursos alrededor de datos demográficos. Que tienen valor, vaya, pero no el que tienen los de actitud o necesidades.
En este punto hay que hablar de lo que se denomina «First-Party Data» y «Third-Party Data». Las fuentes «First-Party» son aquellas que son propias de las empresas. Entre ellas, destacan:
Ahora mismo la explotación de estos datos está siendo limitada por la sencilla razón de no disponer de un único punto central que integra y permite la explotación de datos centralizada. Aquí es donde cobra sentido el concepto de «data lake«, por cierto.
Por otro lado, los «Third-Party Data», son aquellos datos que compramos a «mayoristas» o «proveedores» de datos. Datos relacionados con el consumo, estilo de vida, demografía, comportamiento en tiempo real, etc. Permiten completar la «foto» a una empresa. Ya hablamos en cierto modo de los problemas que entrañaba para la privacidad de un sujeto estas transacciones de datos. En este caso, las limitaciones de las empresas parecen venir desde la óptica de la calidad de datos: frescura, precisión, etc., problemas ligados a la calidad de datos de lo que ya hemos hablado en el pasado.
Las empresas, ante la limitación que suelen tener de explotar sus «First-Party Data«, deberían comenzar a mirar hacia los «Third-Party Data» si quieren enriquecer muchos sus modelos y hacer más más precisos sus modelos. La capacidad de generar valor a partir del análisis de datos necesita de integrar nuevas fuentes de datos. Porque los datos que son más importantes no quedan recogidos en las operaciones diarias de una empresa.
Y es que el paradigma del «Big Data» es un medio, no un fin. Es un instrumento del que podemos valernos para obtener conclusiones. Pero el valor de los mismos, dependerá en gran medida de la materia prima con la que trabajemos. Y por ello, muchos de los fines están todavía por inventar. De ahí que suela decir que no hay dos proyectos de Big Data iguales; depende mucho de cómo las empresas vayan avanzando desde sus datos demográficos a los datos de actitud. De sus datos propios («First-Party Data«) a integrar también datos de terceros («Third-Party Data«).
Creo que muchas de las expectativas no alcanzadas aún hoy se deben a que seguimos viendo este campo del análisis de datos como el «Data Mining original«. Aquel en el que el objetivo era explotar grandes conjuntos de datos. Que no digo que esto no siga siendo válido; pero si queremos alcanzar las grandes expectativas generadas, debemos mirar «más allá». Y entender el valor que tienen los datos que nos pueden aportar los datos de terceros o los «Open Data«, me resulta bastante crítico. Y así, poder alcanzar mejor las expectativas para hacerlas reales.
“La comunicación corporativa ya tiene claro que la mejor manera de llegar a sus receptores es con la caracterización y eso sólo se consigue a través del Big Data” (Nagore de los Ríos)
Nagore de los Ríos participará en nuestro Programa en Big Data y Business Intelligence y Programa Experto en Análisis, Investigación y Comunicación de Datos que impulsa la Universidad de Deusto. Fundadora de Irekia, portal de Gobierno Abierto del Gobierno Vasco, y consultora Senior del Banco Mundial en iniciativas de Comunicación y Open Data, acercará su experiencia en el ámbito del Big Data y otras cuestiones vinculadas con la comunicación y el Business Inteligence. Para Nagore de los Ríos, la complejidad del ámbito comunicativo en la actualidad, cuando se incorpora el Big Data, hace necesario el uso de metodologías, como Outreach Tool, para diseñar estrategias y planes de comunicación. Participará en el módulo M3.1 de nuestro Programa de Big Data, en colaboración con Mª Luz Guenaga y Alex Rayón, en las sesiones de Open Data y visualización de datos.
Periodista de formación, consultora en Comunicación, experta en Open Data, ¿cuál es tu aportación al Programa en Big Data y Business Intelligence?
Tanto el Open Data como la comunicación están muy ligados a los Datos. El Open Data porque en sí mismos son fuentes de datos que cualquiera puede extraer y con ello enriquecer su propio Big Data, cruzando sus datos con los Open Data, lo que supone aplicar el Business Intelligence de una forma mucho más enriquecida y además de manera gratuita. Es la materia prima más barata y accesible que alcanza gran valor cuando se cruza con otros datos bajo las preguntas adecuadas.
Y cuando hablamos de comunicación, en primer lugar, los datos son la primera y mejor fuente de información, la más fiable, la que nos aporta el mejor conocimiento, por lo que es clave realizar buenas preguntas a los datos para que nos ofrezcan las respuestas que deseamos conocer. En segundo lugar porque para comunicar es muy importante asegurarnos de que no generamos ruido, de que el destinatario está receptivo a nuestro mensaje y es el destinatario acertado. De este modo, el Big Data se utiliza en dos momentos claves de la comunicación, el primero de ellos a la hora de hipersegmentar a los destinatarios, saber lo que desean o necesitan escuchar y en segundo lugar a la hora de vincular los mensajes y segmentarlos de la misma manera. Muchas veces queremos comunicar demasiadas cosas a todas las personas y eso no es eficaz. Si a la Comunicación le aplicamos las técnicas de Business Intelligence y utilizamos bien el Big Data podemos obtener la respuesta exacta de quien es el que necesita recibir un determinado mensaje, y qué mensaje es el más adecuado.
Y por último el Big Data está muy ligado al Marketing y a la Comunicación sobre todo a la hora de conocer los resultados, establecer los indicadores, extraer información valiosa de las redes sociales y de lo que las personas y marcas están hablando así como observar los impactos que al emitir los mensajes somos capaces de producir o no en nuestros públicos objetivos.
Cuando hablamos de comunicar, contamos con dos ámbitos, el del periodismo tradicional y la comunicación corporativa o institucional. ¿Qué beneficios obtiene cada uno de ellos?
Ambos mundos están despertando y entendiendo que los datos son la mejor fuente de información posible. En el ámbito del periodismo se están dando cuenta de que los datos no mienten y no tienen intenciones o están condicionados, los periodistas empiezan a ver una ventaja no solo en la objetividad de sus informaciones sino también en el acceso a las fuentes y en la rapidez para encontrar las respuestas y poder con ello contar las historias que los datos guardan.
En el ámbito de la comunicación corporativa también se están dando cuenta de que para llegar a sus receptores o clientes de forma más directa la hipersegmentación es básica y sólo se consigue a través del Big Data. Gracias al Big Data además pueden localizar a nuevos receptores que son público objetivo de las marcas o empresas, más allá de los habituales medios de investigación sobre audiencias, que se centraban en los últimos años en receptores que desde las redes sociales estaban dispuestos a escuchar los mensajes de la marca o los seguidores o fans que se conseguían por otras vías del marketing.
¿De qué modo puede ayudar el Big Data a la comunicación de empresas e instituciones?
Con la aparición de las redes sociales, las organizaciones encontraron una forma más directa de llegar a su audiencia sin pasar por intermediarios, pero se encontraron con el problema de captar tráfico y atraerlas hasta sus perfiles o webs para poder hacer llegar sus mensajes. Gracias a la publicidad en internet que facilita la segmentación pudieron acotar a ese público pero seguían esperando a que fuesen los consumidores quienes, buscando productos similares o a través de palabras claves, acabasen en sus publicaciones o anuncios. Ahora con el Big Data hemos alcanzado ya el tercer nivel, y son las marcas las que por distintas vías recopilan información de los consumidores, y utilizan el mejor canal para llegar a ellos.
Otra ventaja que encuentran ahora todas las organizaciones públicas o privadas es que pueden cocrear mejor sus servicios con los destinatarios y usuarios finales. Ya no se basan en intuiciones o en evidencias o en encuestas o preguntas de satisfacción donde los usuarios decían que es lo que ellos mismos creían que necesitaban o querían (y digo creían porque muchas veces pensamos que nos vamos a comportar de una cierta manera o vamos a tener unas necesidades concretas y luego la realidad es totalmente diferente). Los servicios y productos se pueden cocrear ahora de forma más fehaciente, prediciendo el futuro y ofreciendo soluciones a lo que verdaderamente se va a consumir o necesitar
Pero para ello hace falta actuar con cierto método, por el volumen de información que se maneja.
Si hablamos de comunicación en concreto, y queremos aplicar una estrategia y un plan de comunicación toda esa información que el Big Data y el Business Inteligence nos ha aportado lo debemos canalizar y nos sirve de base para realizar una estrategia. Contar con una estrategia definida permite señalar objetivos y llegar a alcanzarlos, no perder la perspectiva, ser eficaz en el desarrollo de la ocupación correspondiente, no malgastar tiempo ni recursos, sobre todo en un mundo tan complejo como el presente. Y una vez determinada la estrategia es necesario un plan de acciones, porque el plan permite conocer de antemano qué se pretende conseguir y cómo se piensa lograrlo.
Y para diseñar esa estrategia y el plan con el que se va a ejecutar, es necesaria una metodología. En este sentido, os recomiendo una metodología abierta y gratuita que se llama Outreachtool.com, que está empezando a dar sus primeros pasos ahora.
¿Nos puedes explicar qué es Outreach Tool, y que supone para la Comunicación corporativa e institucional en el ámbito del Big Data?
Se trata de una herramienta para generar estrategias y planes de comunicación efectivos de manera abierta, sencilla, intuitiva y ágil. Está publicada bajo la licencia Creative Commons y se conforma por una metodología y una tabla dinámica, que se pueden descargar gratuitamente. Se desarrolla en tres fases y se resuelve en un calendario de acciones para desarrollar la estrategia que se genera con la metodología.
A grandes rasgos (porque la metodología es más completa) La primera fase gira en torno a la empresa, institución, marca personal para la que se prepara la estrategia. La segunda fase analiza el conjunto de receptores a los que se dirige el plan, con una profunda hipersegmentación de destinatarios. Porque no les interesa lo mismo a unos destinatarios que a otros, ni se quiere conseguir lo mismo de todos ellos. Esto marcará también lo que se va a comunicar, que se analiza en la tercera fase, cuando se concreta el qué, el cómo, el con qué y el cuándo comunicar.
Nuestro empeño con Outreach Tool ha sido obtener un mecanismo fácil de comprender y aplicar que, no obstante, no se desvirtúe al simplificar en demasía el complejo entramado de claves que afectan a la comunicación. Buscamos que no se escape ningún detalle, que no caiga en la improvisación ninguna parte esencial de una buena estrategia de comunicación, pero que, al tiempo, no te resulte un trabajo farragoso ni tedioso.
¿Y cómo interviene el Big Data en Outreach Tool?
Para realizar cualquier estrategia es imprescindible poseer información que nos indique que caminos tomar. Se puede trabajar con intuiciones, como hasta ahora se desarrollaban los planes de comunicación. También con la recogida “manual” de información con entrevistas, estudios, análisis, encuestas… Pero si esa información es obtenida a través del Big Data tendrá un grado de acierto mayor. Y, por supuesto, con la combinación de las tres vías, el resultado será todavía mejor.
Las entidades financieras han sido las pioneras tradicionalmente en utilizar el Data Mining y Machine Learning (ML). Y lo han aplicado principalmente en el núcleo de su negocio, la financiación. Cuando un cliente quiere solicitar un préstamo, el banco le solicita una determinada información (edad, estado civil, nivel de ingresos, domicilio, etc). En realidad el banco lo que ha hecho internamente ha sido analizar los datos históricos de los préstamos que tiene concedidos e intentar determinar la probabidad de que un cliente con determinadas características pueda impagar ese préstamo (a través de modelos de Machine Learning). Es lo que se denomina un scoring, y es el primer requisito que requiere una entidad financiera para conceder un préstamo a un cliente, que pase ese modelo de scoring (es decir, que no tenga una gran probabilidad de impago según ese modelo estimado).
Pero hay otras muchas otras áreas dentro de un banco donde se utiliza el ML. Ya comentamos en otro artículo cómo los departamentos de Marketing hacen un proceso similar para intentar predecir qué clientes podrían contratar en un futuro cercano un nuevo producto. Son los denominados modelos de propensión y la lógica es parecida al caso anterior. Analizar los datos históricos de contrataciones de productos para buscar clientes “similares” a los que anteriormente ya contrataron esos productos. Los clientes más parecidos a los que en el pasado contrataron un producto son a priori los que más probabilidad tienen de contratarlos en el futuro. A esos serán a los siguientes a los que les ofrecerán las ofertas comerciales.
Pero esto del ML tiene muchas más aplicaciones en una entidad financiera. Por ejemplo intentar detectar automáticamente operaciones (bien sean de tarjetas de crédito o transferencias) fraudulentas para evitar disgustos a sus clientes. O intentar predecir el uso en fin de semana de los cajeros automáticos de las oficinas para asegurarse de que no se quedan sin efectivo cuando los clientes vayan a retirarlo. O incluso a nivel organizativo re-estructurar la localización de sus oficinas físicas para atender mejor a sus clientes a través del análisis de los datos de las visitas de los mismos a las oficinas. Y todo esto por no hablar de los motores de recomendación de inversión, que analizan rentabilidades históricas de los activos financieros para ofrecer recomendaciones de inversión personalizadas a los clientes según el apetito de riesgo que estos tengan.
Todos estos ejemplos son tan sólo una muestra de las aplicaciones que el mundo del Data Mining y Machine Learning tienen en una entidad financiera, pero como os podéis imaginar, hay muchos más. La tendencia actual es enriquecer estos modelos con otro tipo de datos (redes sociales, Open Data, datos no estructurados…) para mejorar su capacidad predictiva. Aquí es donde entra en juego el Big Data.