El pasado noviembre, saltó a la palestra del «mundo de los datos» una noticia que en España ha pasado algo desapercibida (al menos en los medios generalistas). No obstante, no creo que sus implicaciones sean menores. La agencia de espionaje de Canadá, la CSIS, había estado recolectando metadatos (datos generados en el uso de medios digitales como el correo electrónico, los mapas de geolocalización, etc.) durante 10 años.
El tribunal supremo de Canadá, instruyendo la causa, decretó -como no podría ser de otro modo- que esto era ilegal. Por más que tuviera un fin de eventuales espionajes o amenazas por terrorismo, la seguridad y privacidad del ciudadano por delante de todo.
Estos metadatos, para que se hagan ustedes a la idea, incluyen desde números de teléfono, localizaciones, direcciones de email, duraciones de las llamadas o comunicaciones, etc. Es decir, datos asociados a acciones, no el contenido de las mismas en sí (las llamadas y sus contenidos… en cuyo caso estaríamos hablando de algo aún más grave). El CSIS quería esto porque en 2006 puso en marcha un programa que bautizó como «Operational Data Analysis Centre» para producir información inteligente que ayudase a la toma de decisiones estratégicas en favor de la seguridad del país.
Esta noticia, me resultó bastante ilustrativa porque los metadatos (los grandes olvidados, sobre los que he escrito en alguna ocasión a colación de whatsapp y Facebook), pueden revelar mucha información sobre nosotros mismos. Cómo nos comportamos, qué y por qué decidimos qué, cómo tomamos las decisiones, etc. En definitiva, un montón de información personal, que nunca podemos olvidar. Como ha hecho el tribunal supremo de justicia canadiense, por más que se trate de una agencia pública la que ha cometido el delito.
Pues bien, me acordaba de esta noticia al leer que un equipo de investigadores de la empresa de telecomunicaciones noruega Telenor, junto con el MIT Media Lab y la organización sin ánimo de lucro Flowminder, han encontrado un método para, partiendo de metadatos, predecir el estado ocupacional/profesional de una persona (desempleado o a qué se dedica). Podéis leer el artículo aquí.

El paper explica maravillosamente el modelo predictivo que han conformado. La variable dependiente, no era otra que una variable categórica de 18 pòsibles estados (uno por cada profesión, desde estudiante, empleado/ocupado y tipos de ocupación). ¿Las independientes? (es decir, las predictoras); pues los metadatos que decíamos antes: un total de 160 características o variables (casi nada), tomadas desde dispositivos móviles y categorizadas en tres categorías: financieras, de movilidad y sociales. Para qué explicarlo, si en el paper sale una tabla con todas esas características:
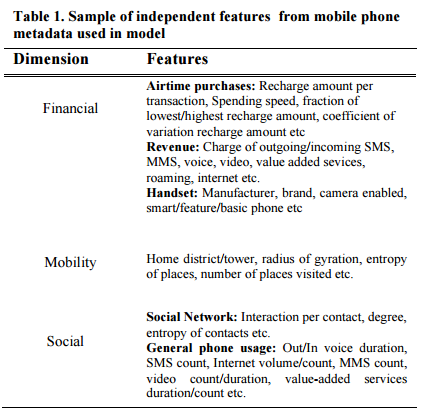
Todos estos datos generamos desde nuestro dispositivo móvil. Que, como decíamos, ayudan a predecir, entre muchas cosas, una cuestión tan importante como nuestro estado de ocupación. Para ello, el equipo investigador ha comparado diferentes modelos predictivos (GBM, Random Forest, SVM, kNN, redes neuronales, etc.). Tras estudiar los rendimientos de cada modelo predictivo, se quedaron con una arquitectura de red neuronal usando un 75/25% de training/testing, siendo la precisión del modelo, de media, un total de un 67,5%. Hay profesiones donde es más fácil acertar y en otras más difícil. Será que algunos nos comportamos de manera más predecible y otros de menos 🙂

¿Qué variables son las más críticas? Es decir, las que «mejor predicen» una profesión. Nada menos que la la torre de telecomunicaciones a las que más se conecta una persona (latitud y longitud), el número de lugares visitados (por frecuencia) y el radio de viaje (cómo se aleja de su hogar, la celda de conexión más cercana y que más frecuenta -salvo que durmamos mucho en hoteles :-)-). ¿Alguien se extraña entonces por qué Google Maps es gratuito? Lo de siempre, introduzcan en el navegador maps.google.com/locationhistory. En la siguiente imagen, representan la relación de estas variables y cómo ayudan a predecir la ocupación:
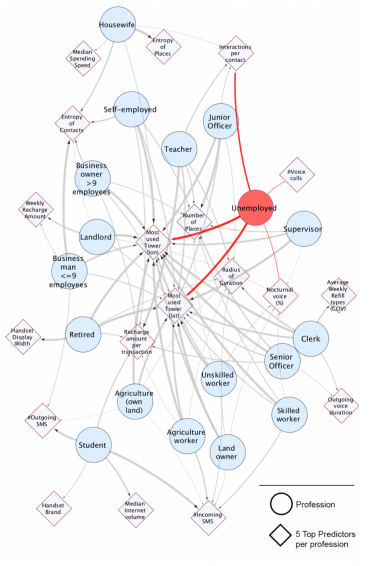

Este modelo de deep learning (aprendizaje cognitivo o profundo), este tipo de software que está revolucionando tantos procesos, dado que se entrenan a sí solos para encontrar patrones en grandes cantidades de datos, está en boca de muchos ahora. Su potencial es tan grande, que permitir que una agencia pública federal los emplee para cosas como las que aquí descritas, me parece preocupante.
Y ahora ustedes se estarán preguntando de dónde habrán estos investigadores obtenido los datos. Telenor 🙂 Es decir, la empresa de telecomunicaciones que, obviamente de manera anonimizada, han procesado hasta 76.000 conexiones de dispositivos móviles a sus torres de comunicaciones. Y de ahí han salido estos metadatos. Un proyecto, solo basado en esos datos, pero que imagínense lo que puede mejorar si lo integramos con otras fuentes de datos. Modelos aún más precisos a nivel de predicción. Un proyecto de Big Data en toda regla.
Como ven, estos proyectos de Big Data, tienen mucho potencial. Todo está por hacer y aprender. En nuestros programas de Big Data, además de ver los diferentes modelos predictivos, también aprendemos a integrar todas esas fuentes de datos, mejorar su calidad en un modelo de datos único y unificado, así como a montar infraestructuras de Big Data que optimicen estos procesamientos.