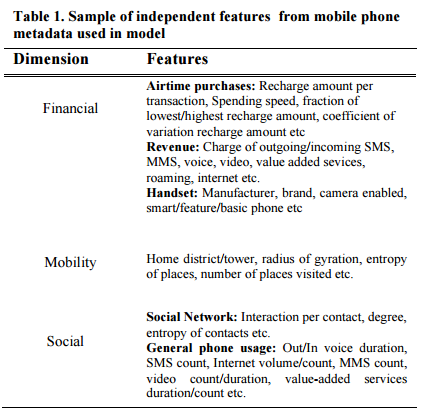
El término big data se escucha hasta en la sopa. Ahora resulta que todo es big data. Pero nada más lejos de la realidad; la mayor parte de las personas que manejan y analizan datos, emplean small data. Pero ¿qué los distingue? He aquí la lista de las diez que hay que saber sobre los big data.
- No todo son big data
La mayor parte de los/as profesionales que usan datos se basan en small data: datos que aparecen en un volumen y formato que los hacen utilizables y analizables. Los big data, en cambio, son tan enormes y complejos que no se pueden gestionar o analizar con métodos de procesamiento de datos tradicionales. El análisis y procesamiento de los big data, sin embargo, puede producir small data. A la vez, los small data pueden hacerse más big cuando se funden, escalan e interrelacionan para crear bases de datos mayores.
- !Los big data son big!
Algunos definen los big data simplemente por su volumen: son tan grandes que solo se pueden extraer, gestionar, almacenar, analizar y visualizar usando infraestructuras y métodos especiales. Vivimos en la era de los big data, que se miden, no en terabytes, sino en petabytes y exabytes (donde peta- denota un factor de 1015 y exa- de 1018).
- Una definición de big data habla de…
una profusión de objetos digitales y contenido online generado por usuarios/as durante sus actividades digitales, interceptación masiva de interacciones y metadatos (es decir, los datos sobre los datos), así como producto de la dataficación de la actividad humana y no humana, que es tan grande, puede ser procesada con tal velocidad, es tan variada, tiene tanto potencial económico, y muestra tal nivel de exactitud y complejidad que puede ser considerada realmente grande, y por tanto solo puede ser analizada por nuevas infraestructuras y métodos.
- No existe el “dato crudo” u objetivo
Como ya dijo en 2013 Lisa Gitelman en su muy citado libro “Raw Data” Is an Oxymoron: afirmar que un dato está “crudo”, es decir, desprovisto de intención, parcialidad o prejuicios, es simplemente erróneo. Los datos no surgen de la nada. La recopilación de datos y metadatos es constante, subrepticia y abarcadora: cada clic y cada «me gusta” son almacenados y analizados en alguna parte. Estos datos son de todo menos «crudos»; no debemos pensar en ellos como un recurso natural, sino como un recurso cultural que necesita ser generado, protegido e interpretado. Los datos son «cocinados» en los procesos de recolección y uso (procesos que, a la vez, son “cocinados”); y no todo puede ser, ni es, «reducido» a los datos o “dataficado”. Por tanto, los conjuntos de datos, por muy big que sean, pueden esconder errores, vacíos y arbitrariedades.
- Los datos no son el “nuevo petróleo”
Ya la comparación no es muy afortunada en los tiempos del cambio climático. Pero aunque el “valor” es una de las uves asociadas a los big data (junto con volumen, velocidad, variedad, veracidad y otras palabras que empiezan con uve), los datos no son valiosos en sí mismos; hay que transformarlos en utilizables, analizables y accionables para poder extraer valor de ellos. “Limpiar datos” desestructurados y desconectados (es decir, no comparables ni relacionables) es posiblemente la tarea más ardua y desagradecida en la gestión de datos. En resumidas cuentas: los datos son la base de la información, pero no son información.
- No se necesitan big data para hacer buenos análisis de datos
Ahora estudiosos y estudiosas, como Jennifer Gabrys, Helen Pritchard y Benjamin Barratt, hablan de datos “suficientemente buenos” (good enough data). Se refieren, por ejemplo, a datos generados por personas no expertas (crowdsourced data). Estos datos pueden ser la base de potentes proyectos como algunas de las aplicaciones de la plataforma Ushahidi que han servido para organizar ayuda humanitaria y asistir a víctimas en casos de conflicto armado y desastre. En estos casos, los datos proporcionados por la gente sobre una crisis se amasan, verifican y visualizan en mapas interactivos que están revolucionando la asistencia humanitaria.
- Todo el mundo miente…
Los big data pueden servir para hacer estudios enormemente iluminadores. Seth Stephens-Davidowitz acaba de publicar Everybody Lies. Este libro –subtitulado algo así como: “lo que internet puede decirnos acerca de quiénes somos realmente”— es una muestra de que cómo la gente miente en las encuestas y posturea en las redes sociales, mientras que se “desnuda” cuando hace búsquedas en internet. Basado en el análisis masivo de las búsquedas en Google, otras bases de datos y sitios web, Stephens-Davidowitz descubre que la gente es mucho más racista, machista e innoble de lo que piensa o admite. Y es que los chistes racistas aumentan alrededor del 30% en el Día de Martin Luther King en los Estados Unidos, y hacer promesas «es una señal segura de que alguien no hará algo».
- Y no todo el mundo tiene acceso a los big data
¿Quiénes amasan big data? Sobre todo los gobiernos (desde datos macroeconómicos o demográficos hasta datos procedentes de la interceptación de comunicaciones y la vigilancia) y las grandes corporaciones. Las revelaciones de Snowden en 2013 mostraron, por ejemplo, que los servicios de inteligencia del gobierno estadounidense, con la colaboración empresas privadas y otros gobiernos, habían establecido una tupida capa de vigilancia e interceptación datos sobre las comunicaciones de millones de personas en todo el mundo. Cathy O’Neil, en su libro Weapons of Math Destruction, muestra cómo los programas basados en big data aumentan la eficiencia de “la publicidad predatoria” y socavan la democracia. Otros estudiosos, como Sandra Braman, Zeynep Tufekciy y Seeta Peña Gangadharan, hablan de cómo los gobiernos, con la connivencia de algunas empresas, hacer perfiles, discriminan a grupos vulnerables y potencian la vigilancia indiscriminada, omnipresente y preventiva.
Por otro lado, el movimiento open data hace campaña para que los datos públicos sean abiertos, accesibles y usables. Y muchos gobiernos, grandes y pequeños como por ejemplo Irekia, se han apuntado a abrir los cofres de sus datos, y cada vez hay más presión para que este movimiento se extienda.
- Los datos, big o small, no son para todo el mundo
En un alarde de entusiasmo, Simon Rogers comparó en 2012 el análisis de datos con el punk: “cualquiera puede hacerlo”. Bueno…, pues no es así exactamente. No solamente los big data no están disponibles para cualquier punk, sino que, como Daniel Innerarity señala, las herramientas para convertirlos en analizables y útiles no están al alcance de cualquiera tampoco.
- Sin embargo, los datos tampoco son inaccesibles
Pero las barreras para acceder tanto a datos como a las herramientas para usarlos han ido cayendo en los últimos años. Forensic Architecture, con Amnistía Internacional, ha creado un modelo interactivo de la prisión más notoria de Siria utilizando los recuerdos de los sonidos de la cárcel narrados por supervivientes que habían sido retenidos en la oscuridad. El proyecto, llamado Saydnaya: Dentro de una prisión de tortura siria, tiene como objetivo mostrar las condiciones dentro de la prisión. Cuando los datos no están disponibles, hay organizaciones que los generan. WeRobotics pone en circulación “drones comunitarios” para captar datos sobre las condiciones de los glaciares en Nepal, por ejemplo, con el objeto de analizarlos y lanzar alarmas. InfoAmazonia, entre otras cosas, ha publicado un calendario que superpone el tiempo contado por los pueblos indígenas del Río Tiquié y el tiempo medido en el calendario gregoriano, en un diálogo que nunca tuvieron antes.
Más cerca, en nuestro entorno, estudiantes del Programa universitario de postgrado “Análisis, investigación y comunicación de datos” de la Universidad de Deusto publicaron este año un informe sobre basuras marinas a nivel estatal, en colaboración con la Asociación Ambiente Europeo, que tuvo repercusión en medios y generó un debate sobre los plásticos en el mar. La empresa Bunt Planet utiliza infraestructuras de datos para trazar redes eficientes e inteligentes. Y el centro de investigación DeustoTech aplica robótica y big data para diseñar la movilidad del futuro.
Cuesta adquirir las habilidades, pero programas como el nuestro están al alcance de quien quiere echarle ganas, tiene curiosidad y está abierto/a aprender.
Miren Gutiérrez
Directora del Programa universitario de postgrado “Análisis, investigación y comunicación de datos” de la Universidad de Deusto
*Este post es la versión completa de un artículo publicado en Noticias de Gipuzkoa.