En la sociedad de la información actual las empresas manejan cantidades ingentes de datos, tanto propios como ajenos. Cada vez es más habitual ver reportes obtenidos a partir de diversas técnicas analíticas, y cuadros de mando generados por medio de sistemas de reporting para alta dirección.
A partir de estos informes se toman decisiones que en muchas ocasiones pueden ser cruciales para el devenir de la empresa. Entonces, es de suponer, que estos informes están hechos tomando como base una información de altísima calidad. Pero, ¿realmente lo están?
La calidad de la información oData Quality en inglés, está cobrando mayor relevancia en los procesos de las organizaciones. Buena parte de culpa la tienen los reguladores, que están empezando a exigir políticas y procedimientos que aseguren unos niveles óptimos de calidad de los datos: Master Data Management (MDM).
No disponer de una política de calidad de datos implica que todos los equipos que vayan a trabajar la información tengan que invertir tiempo en limpiar los datos antes de poder explotarlos para otros propósitos. Además, se corre el riesgo de que en ese proceso de limpieza se generen discrepancias de información si no se adoptan los mismos criterios a la hora de realizar las adaptaciones oportunas.
Las cifras hablan por sí solas, y los expertos coinciden en que 2016 será un año de gran crecimiento en la industria del Data Quality.
78% de las empresas tienen problemas en los envíos de email
83% de las empresas están luchando contra silos de datos
81% de los retailers no pueden apalancarse en los programas de fidelidad debido a información inexacta
87% de las institucionesfinancieras tienen dificultades para obtener inteligencia confiable
63% de las compañías todavía no tienen un enfoque coherente de la Calidad de Datos
En definitiva, para que las organizaciones puedan obtener valor de sus datos, deben primero poner orden en la gestión, tratamiento y conservación de la información. Los datos son y deben ser la materia prima que guíe la toma de decisiones de nuestra empresa, y para ello deben presentar en el formato esperado, en el momento preciso, para las personas que lo necesitan y con la máxima calidad.
Recientemente, mi compañero Iñaki Pariente, nos ilustraba sobre la importancia de la componente jurídica en todo proyecto de Big Data. Estos días, en el Parlamento Europeo, se está produciendo mucha actividad en torno a todo ello. Concretamente, están trabajando una Propuesta de Reglamento General de Protección de Datos, del Parlamento Europeo y del Consejo.
El núcleo de lo que se está tratanto es la protección de las personas físicas en lo que respecta al tratamiento de datos personales y la libre circulación de estos datos. En adelante, a efectos de simplificación, me referiré a ello como Reglamento General de Protección de Datos (RGPD).
La legislación vigente en la Unión Europea en materia de protección de datos es la Directiva 95/46/CE. Esta fue adoptada en 1995 con un doble objetivo: defender el derecho fundamental sobre la protección de datos y garantizar la libre circulación de estos datos entre los Estados miembros (en una época en que la libre circulación de capitales, personas y bienes era algo del día a día). Se complementó posteriormente mediante la Decisión Marco 2008/977/JAI, como instrumento general a escala de la Unión Europea para la protección de datos personales tratados en contextos de cooperación policial y judicial.
Y ahora pasamos a 2015. La rapidez con que la evolución digital está cambiando muchos de los planos de nuestra sociedad y nuestra economía, ha supuestos nuevos retos en lo que a la protección de datos personales se refiere. Ahora, el volumen de datos es mucho mayor, permitiendo que tanto empresas privadas como entidades públicas pueden aprovecharlos. Además, las personas físicas, generan y difunden un volumen de datos nunca visto hasta la fecha.
A la par, los legisladores se dan cuenta que para poder desarrollar una sociedad realmente digital y un Mercado Único Digital (también debatido e impulsado hace unos meses en la Comisión Europea), es fundamental generar confianza en entornos online. Si la confianza no existe, las personas no nos veremos tan implicados en comprar online o a relacionarnos con la administración a través de Internet. La protección de datos personales desempeña, por tanto, una función esencial en la Agenda Digital para Europa y más concretamente en la Estrategia Europa 2020 para el crecimiento y la competitividad.
Esta nuevo reglamento de protección de datos, afectará a muchas personas e instituciones. Si tienes una empresa o aspiras a trabajar en una radicada en Europa o que haga negocios en Europa, tienes más de 250 trabajadores o tu núcleo de negocio se centra en el procesamiento de datos (que cada vez son más las empresas en ello), tu empresa tendrá, bajo propuesta de dicho Reglamento que contratar un Data Protection Officer (DPO en adelante).
Eso de «centrarse en el procesamiento de datos«, que resulta ciertamente ambiguo, por lo que he podido leer se refiere a «tratamientos de datos masivos, que afecten a centenares de miles o millones de usuarios y que se mantengan periódicamente actualizados como la elaboración de perfiles de clientes o en el mundo de marketing«. Por lo tanto, creo que no son pocas las empresas que quedarán afectadas por ello.
¿Y qué es esto del DPO y en qué medida me afectaría? Este perfil tendrá que encargarse de tareas mucho más extensas que las atribuidas al responsable de seguridad, figura regulada en el Reglamento que desarrolla la Ley Orgánica de Protección de Datos de España (que data de 1999). Este último, actualmente se encarga de «coordinar y controlar las medidas de seguridad«. Pero, el DPO tendrá una función no solo de seguridad, sino con una mirada hacia dentro de la organización y hacia fuera:
Dentro de la empresa: informar y asesorar a todos los trabajadores de la organización en lo que a sus obligaciones con respecto a la normativa de protección de datos se refiere. Además, deberá elaborar los protocolos de asignación de responsabilidades y educación en esta materia, y velar por su cumplimiento. Por lo tanto, amplía sus funciones en esta materia.
Fuera de la empresa: será el encargado de responder a las solicitudes de información de la autoridad de control -la Agencia Española de Protección de Datos (AEPD) o equivalentes en Comunidades Autónomas- y cooperar con ellao para cualquier solicitud.
Este proceso de «blindaje» será tan exigente que hará que las empresas tengan que publicar los datos de contacto de sus Data Protection Officer, así como comunicárselo a la autoridad de control. Esto hará un ejercicio de transparencia y accountability que emana la importancia que adquiere. Es más, el proyecto de reglamento determina que no podrá ser despedido o sancionado mientras ejerza y ejecute sus tareas (artículo 36.3), ni tampoco encontrar injerencias o instrucciones en el ejercicio de sus tareas. Dada la naturaleza del desempeño de sus funciones, está obligado a guardar secreto y confidencialidad. Y, aunque puede, dentro del organigrama de trabajo, tener asignadas otras funciones o tareas, éstas no pueden dar lugar a un conflicto de intereses.
¿Y qué pasa si no cumplo este reglamento? Las multas por no cumplir reglamentos Europeos son importantes; hasta un 2% de los Ingresos de la organización o 100 millones por cada infracción. Esto invita a la cooperación y complicidad por parte de las instituciones.
Como ven, la reglamentación para la protección de datos personales vuelve a endurecerse y hacer que Europa, siga fiel a su estilo de garantzar los derechos fundamentales de sus ciudadanos. Entenderán así, que la protección de datos quedó excluida de las negociaciones sobre el crucial tratado de Asociación Transatlántica de Comercio e Inversión que negocian la Unión Europea y Estados Unidos. Otro tema que traerá largas reflexiones. Y ahí veremos el papel del Data Protection Officer como eje clave en las organizaciones.
El Data Protection Officer (Fuente: http://www.computing.co.uk/ctg/feature/2306122/rise-of-the-data-protection-officer)
[:es]Llega la cita electoral más disputada e incierta de las ultimas décadas. ¿Qué dicen las redes sociales? ¿Qué papel han tenido en el posicionamiento de la gente? Mariluz Congosto es posiblemente una de las expertas con mas conocimiento sobre el tema. Acaba de publicar un informe sobre cómo se han vivido en Twitter los debates de los diferentes candidatos, y viene al campus de la Universidad de Deusto en Donostia el día 22, a las 18:00, para hablarnos de eso y mucho más.
Licenciada en Informática por la Universidad Politécnica de Madrid y Máster en Telemática por la Universidad Carlos III, actualmente está finalizando el doctorado en la Universidad Carlos III sobre la propagación de mensajes y caracterización de usuarios/as en Twitter. Mariluz es también una personalidad en redes sociales, como no podía ser de otra manera.
No te pierdas su charla, en la que también habrá la posibilidad de preguntarte sobre los entresijos de sus investigaciones sobre redes sociales.
Cuando hablamos de procesamiento de datos, automáticamente a muchos de nosotros nos vienen muchos números a la cabeza, muchas técnicas estadísticas, conclusiones cuantitativas, etc. Esto es así, pero es que hay mundo más allá de los números. Dos de las explotaciones de datos que más popularidad están ganando en los últimos tiempos, especialmente derivado de que se estima (más arriba, más abajo) que aproximadamente el 80% de los datos son desestructurados, son el análisis de textos y el análisis de redes sociales.
El análisis de textos o Text Mining hace referencia al análisis de textos o contenidos escritos sin ningún tipo de estructura. Se calcula que el 80% de la información de una empresa está almacenada en forma de documentos. Sin duda, este campo de estudio es muy amplio, por lo que técnicas como la categorización de texto, el procesamiento de lenguaje natural, la extracción y recuperación de la información o el aprendizaje automática, entre otras, apoyan el text mining (o minería de texto).
El segundo campo en el que veremos gran recorrido (ya lo estamos viendo) es el análisis de redes sociales o estructuras de grafos. Ya hablamos de ello en un artículo anterior. No es solo análisis de las redes sociales entendidas como análisis de contenido de Social Media. Es un estudio numérico, algebraico, de una representación de conocimiento en formato de grafo. Un campo que mezcla la sociología y las matemáticas (el álgebra de grafos) en el que hay actores o entidades que interactúan, pudiendo representar estas acciones a partir de un grafo.
Un grafo o representación de la interacción entre entidades o actores a través del álgebra de grafos (Fuente: http://www.adictosaltrabajo.com/tutoriales/web-htmlcomo-grafo/)
El interés por estudiar los patrones y estructura que esconden esta representación de nodos y aristas ha crecido en los últimos años a medida que ha aumentado la relación entre agentes. Es decir, a medida que han crecido las redes sociales (¿cómo se relacionan mis clientes en facebook?), ha crecido la influencia de una persona en otra para comprar (los millenials confían más en la reputación de sus amigos que en la publicidad de las marcas), las redes de proveedores y clientes han aumentado sustancialmente (por la globalización de la economía y la interconexión internacional), etc., crece el interés por estudiar qué patrones pueden descubrirse para incrementar la inteligencia del negocio.
¿Y por qué esto de interés ahora? En la medida en que un problema dado (acordaros, primer paso de un proyecto Big Data), puede ser modelado mediante un grafo y resuelto mediante algoritmos específicos de la teoría de grafos, la información que podemos obtener es muy relevante. Esto es algo que los topógrafos (cómo enlazar las estaciones del metro de Nueva York de la manera más eficiente para todas las variables a optimizar -distancia, coste, satisfacción usuario, etc.-) o los antropólogos (cómo se han relacionado las especies y los efectos producidos unos en otros) llevan muchos años ya explotando. Ahora, da el salto al mundo del consumo, la sanidad, la educación, etc.
¿Qué nos puede aportar un grafo, una red social, y su análisis a nuestros interes? Las redes sociales pueden definirse como un conjunto bien delimitado de actores como pueden ser individuos, grupos, organizaciones, comunidades, sociedades globales, entre otros. Están vinculados unos a otros a través de una relación o un conjunto de relaciones sociales. El análisis de estos vínculos puede ser empleado para interpretar comportamientos sociales de los implicados. Esto es lo que ha venido a denominarse el Análisis de Redes Sociales o ARS (Social Network Analysis, o SNA).
Dentro del ARS, uno de los conceptos clave es la Sociometría. Su fundador, Jacob Levy Moreno, la describió como:
“La sociometría tiene por objeto el estudio matemático de las propiedades psicológicas de las poblaciones; con este fin utiliza una técnica experimental fundada sobre los métodos cuantitativos y expone los resultados obtenidos por la aplicación de estos métodos. Persigue así una encuesta metódica sobre la evolución y la organización de los grupos y sobre la posición de los individuos en los grupos”.
Usando una herramienta interactiva como Gephi, se puede visualizar, explorar y analizar toda clase de redes y sistemas complejos, grafos jerárquicos y dinámicos. Es decir, hacer sociometría. Una herramienta de este tipo nos permitirá obtener diferentes métricas, que podemos clasificar en tres niveles:
Nivel global de un grafo
Coeficiente de agrupamiento: nivel de agrupamiento de los nodos, para saber cómo de cohesionados o integrados están los agentes/actores.
Camino característico: mide el grado de separación de los nodos, para determinar lo contrario al punto anterior: cómo de separados o alejados están, y poder buscar así medidas para juntar más la relación entre agentes/actores.
Densidad: un grafo puede ser denso (cuando tiene muchas aristas) o disperso (muy pocas aristas). En este sentido, se puede interpretar como que hay mucha o poca conexión.
Diámetro: es el máximo de las distancias entre cualesquiera par de nodos. De esta manera, sabemos cómo de «alejados» o «próximos» están en agregado a la hora de comparar varios grafos.
Grado medio: número de vecinos (conexiones a otros nodos) medio que tiene un grado. Indicará cuál es la media de conexiones que tiene un nodo, de manera que se puede saber su popularidad..
Centralidad: permite realizar un análisis para indicar aquellos nodos que poseen una mayor cantidad de relaciones y por ende, los influyentes dentro del grupo. De esta manera, sabemos su «popularidad», lo que nos puede dar mucha información para saber la importancia de un nodo dentro del total.
Nivel comunidad (grupos de nodos dentro de un grafo)
Comunidades: instrumento para conocerse a sí mismo, para conocer a los otros, al grupo concreto que vive su momento, y en general a los grupos que viven procesos similares. De esta manera, podemos agrupar a los nodos por patrones de similtud.
Puentes entre comunidades: ¿cómo se conectan estas comunidades? ¿cómo de comunicables son esas comunidades? Para trazar planes de actuación o de marketing.
Centros locales vs. periferia: para saber, dentro de las comunidades, los nodos que son más centrales o críticos, frente a los que no lo son.
Nivel nodo (propiedades de un influenciador dado)
Centralidad: es una métrica de poder. El valor 0.522 para la centralidad de un nodo indica que si para cada par de influenciadores buscamos el camino más corto en el grafo, el 52.2% de estos caminos pasa por ese influenciador. Mide su popularidad, y el algoritmo de Google, por ejemplo, funcionó durante mucho tiempo así, siendo cada nodo, una página web o recurso en Internet.
Métricas de un nodo en una red (Fuente: http://historiapolitica.com/redhistoria/imagenes/ndos/larrosa4.jpg)
Modularidad: la modularidad es una medida de la estructura de las redes o grafos. Fue diseñado para medir la fuerza de la división de una red en módulos (también llamados grupos, agrupamientos o comunidades). Las redes con alta modularidad tienen conexiones sólidas entre los nodos dentro de los módulos, pero escasas conexiones entre nodos en diferentes módulos.
Intermediación: se puede enfocar como la capacidad que inviste el nodo en ocupar una posición intermediaria en las comunicaciones entre el resto de los influenciadores. Aquellos, con mayor intermediación tienen un gran liderazgo, debido a que controlan los flujos de comunicación. Y esto, de nuevo, da mucha inteligencia a un negocio.
Pagerank: algoritmo que permite dar un valor numérico ( ranking ) a cada nodo de un grafo que mide de alguna forma su conectividad. Es el famoso pagerank que utilizó Google (de hecho, el algoritmo fue diseñado por los creadores de Google, que es de donde viene su pasado matemático).
Closeness: cuán fácil es llegar a los otros vértices. Indicará, por lo tanto, cómo de cerca queda ese influenciador para llegar a contactar con otros. Esto, permite saber cuán importante es ese nodo dentro de la red de influencia para eventuales comunicaciones o relaciones con otros nodos.
Y tú, ¿a qué esperas para que el análisis de grafos puedan aportarte inteligencia a tu representación en forma de red social? De nuevo, las matemáticas, además de la sociología, a disposición de la inteligencia de un negocio. Bienvenidos al análisis de redes sociales.
Que el Big Data puede aportar mucho al mundo del marketing es algo que ya hemos señalado con anterioridad. En la era de Internet, la era digital, y dentro del mundo del marketing, el usuario tiene el poder: busca, recomienda, sugiere, se queja, etc. Es fundamental que todos estos que afectarán, en última instancia, a la oferta de una compañía, así como al propio mercado, las marcas lo tengan controlado.
Los beneficios que una organización puede obtener del análisis de estos datos a nivel de marketing son claros: conocimiento de sus clientes, mercados, productos, etc, redundando esto en nuevos mercados, nuevos segmentos, alineamiento de la empresa a los clientes. En definitiva nuevos ingresos y ahorros.
Oportunidades que se enmarcan en una era en la que personalización y especialización que demanda un cliente exigente e informado. El consumidor considera ahora Internet en todo el proceso de compra, emplea el móvil de manera omnipresente (por lo que se multiplican los puntos de contacto) y quiere una experiencia coherente entre canales para que se fidelice a nuestra marca. Es lo que se ha venido a denominar el customer journey o buyer journey, donde el dato juega un papel fundamental. Los puntos de contacto, tanto físicos como digitales, se han multiplicado, y en cada uno de ellos, tenemos una fuente de aprendizaje de lo que quiere, recomienda, busca, etc. nuestro cliente muy importante.
El Customer Journey: un viaje a través de los puntos de contacto físicos y digitales (Fuente: http://www.chuimedia.co.ke/wp-content/uploads/sites/8/2014/11/perfect-consumers-journey.png)
Así, tenemos que ofrecer a nuestros clientes experiencias de compra únicas e integrales a través de estrategias omnicanal. Hasta un 65% de los clientes visita canales online antes de comprar en las tiendas físicas. El cliente decide el canal por el que quiere comprar, y no nosotros como empresas. Y en todo esto, el dato es el activo con el que poder habilitar todas estas opciones.
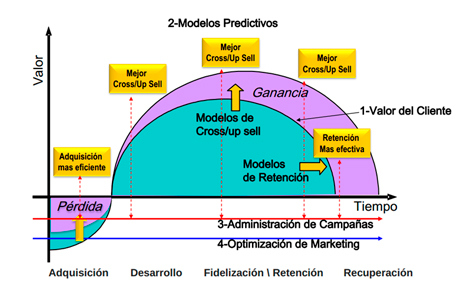
El Business Intelligence y Analytics aporta la inteligencia al dato para convertirlo en conocimiento y disponer de ese valor estratégico. Hablamos de aumentar el valor que ofrecemos al cliente, y para nosotros, como empresa, aumentar la rentabilidad que obtenemos del mismo. En la siguiente representación podemos ver cómo a lo largo del tiempo, la ganancia, el valor, que sacamos a un cliente es cada vez mayor. Y para ello, tenemos diferentes técnicas de tratamiento de datos que nos pueden ayudar en esta tarea. Y en ello, centraremos lo que resta del artículo.
Cómo aumentar el valor obtenido de los clientes (Fuente: http://www.sas.com/offices/latinamerica/argentina/resources/asset/CI_Banca2012.pdf)
La idea es analizar la parte más transaccional (de compra-venta) con las acciones de marketing. Con este dúo, sacamos acciones de marketing con objetivos, personalizado e hipersegmentado. Se trata de analizar los datos contextuales de una compra (momento, lugar, composición de la cesta de la compra), lo enmarcamos en perspectiva (frecuencia, tiempo entre última compra, etc.) analizamos el cliente (si lo hace con tarjeta de fidelización, edad y perfil sociodemográfico, si viene incentivado por un descuento, etc.) y el canal por el que entra (online -tienda online, landing page, redes sociales, etc- u offline), y preguntarnos cosas. Ya hemos dicho en alguna otra ocasión que esta era se caracteriza por la curiosidad, por saber hacernos las preguntas correctas para sacarles valor a los datos.
Por lo tanto, corresponde hablar de modelos de análisis de datos más avanzados. Y, dentro del área de marketing, los cuatro más relevantes son:
Modelos de propensión a la compra (cross y upselling): modelos que calculan la probabilidad de aceptación que tiene un cliente de adquirir productos complementarios (cross) o productos de más alta gama (up) para hacer una venta más rentable. Ambas técnicas las fomentamos presentando productos de una manera amigable, de tal modo que incite a comprar complementos que se sugieren de manera personalizada. Y para ello, se puede emplear la técnica de las reglas de asociación, también conocida como Market Basket Analysis o análisis de afinidad.
Modelos de propensión a la fuga: Uno de los fundamentos básicos de la experiencia humana es que el futuro próximo es parecido al pasado reciente. Esto lo podemos considerar para alcanzar objetivos de retener a los mejores/más rentables clientes, e identificar los factores clave que influyen en el attrition (fuga de clientes). Se utilizan scores para priorizar los clientes objetivo de acciones de retención. Estos clientes son identificados cuando alcanzan ciertos valores en variables con mucha capacidad predictiva (quejas interpuestas, menor frecuencia de compra, etc.) Cada empresa dispone de su modelo, y luego podrá aplicar acciones como descuentos a los más propensos a irse, promociones adhoc a un conjunto de clientes que si bien no son los más propensos a irse ya no tienen la mejor experiencia de cliente, etc. etc.
Optimización de las campañas y acciones dentro de una estrategia omnicanal: con la aparición de Internet, las organizaciones se vieron en la necesidad de crear presencia en múltiples canales. Las estrategias omnicanal, tienen dos objetivos principales: 1) Ofrecer al consumidor una experiencia de compra coherente y sin disrupción entre los diferentes canales; 2) Usar los canales digitales como un vector de generación de tráfico hacia la tienda. Los principales retos no son tanto tecnológicos, sino organizacionales (estructura, incentivos alineados) y operacionales (procesos, políticas y workflows consistentes). La integración con el CRM se vuelve crítica. Así, podremos responder a preguntas como: ¿en qué canal centrarnos? ¿Cuál funciona? ¿Cómo comunicar los datos de un canal con otro? Para un tamaño de cesta dado (y en definitiva, de margen absoluto determinado), ¿qué acción online u offline de marketing reforzar? Conocer cuáles son las que más leads convierten, y por segmentos de población, para así poder personalizar las acciones.
Disponemos de herramientas como Chaordic o Hubspot que permiten hacer la traza de navegación desde que un futuro cliente es un lead, para así poder conocer cuál ha sido la acción y el canal que le ha llevado a su conversión a cliente final. Una vez que teníamos identificados los objetivos (evitar fugas, aumentar la rentabilidad de un cliente determinado, etc.), es cuando podíamos a través de campañas y acciones de marketing hacer un plan de acción.
En definitiva, se trata de programar y automatizar la ejecución de campañas, interactuar con los canales, y capturar las respuestas y medir la efectividad de las mismas. A nivel matemático, lo que hacemos es un análisis de sensibilidad.
Inversión que puedo asumir para adquirir nuevos clientes a tenor del valor que les puedo sacar en el tiempo: la adquisición de clientes y cómo poder rentabilizar esa inversión en el tiempo. A sabiendas que en Internet yo pago por adquirir clientes (una lógica de marketing nueva y que la era digital aporta), rentabilizar el Coste de Adquisición (CAC) con el Valor del Cliente a lo largo del tiempo (CLV) es la idea fundamental. Muchos negocios plantean proyectos de marketing que requieren de este enfoque. Es decir, dependen de presentarles un plan de negocio donde se les argumente la pertinencia y necesidades de hacer inversiones en marketing (Coste de Adquisición) por la rentabilidad que se le puede sacar a cada cliente en el tiempo si conseguimos fidelizar al mismo. El problema es que los cálculos que se suelen hacer para calcular el coste máximo de una campaña de captación de clientes se basa en una venta única típicamente. Lo que no se tiene en cuenta es que ese mismo cliente podría repetir su compra, que es lo que suele ocurrir en los enfoques de fidelización que tan útiles resultan. Por lo tanto, hacer el cálculo matemático del CAC y el CLV resultan de enorme interés para poder poner en marcha acciones estratégicas de marketing que permitan maximizar el negocio.
En definitiva, en el campo del Marketing Intelligence, vamos a poner la estadística al servicio del negocio. Os dejamos abajo una presentación de una sesión del programa en la que vemos muchas de estas cuestiones para que podáis profundizar.
El Business Intelligence (Inteligencia de Negocios) es un conjunto de métodos y técnicas que han venido empleándose desde hace años en diferentes sectores para ayudar en la toma de decisiones. Básicamente consiste en el procesamiento de datos para obtener información resumida y sintetizada de todos ellos.
Lo que ha ocurrido es que en los últimos años ha aparecido un nuevo paradigma, que hemos venido a denominar Big Data. Un paradigma que se puede describir por sus cinco elementos que lo caracterizan: Volumen (gran cantidad de datos), Variedad (diferentes formatos, estructuras, etc. de datos), Velocidad (gran velocidad a la que los generemos), Variabilidad (datos no muy estáticos, sino que cambian con cierta frecuencia) y Valor (el gran potencial de generación de valor que tienen para las organizaciones).
Las cinco V del Big Data (Fuente: http://boursinos.gr/wp-content/uploads/sites/8/2014/02/bigdata-v5-lens.jpg)
Este nuevo paradigma, junto con los métodos avanzados de procesamiento estadístico y matemático (incertidumbre y exactitud) de datos, enriquecen y permiten una toma de decisiones aún más estratégica e informada. Ahora, una empresa no solo puede resumir el pasado (enfoque Business Intelligence), sino que también puede establecer relaciones y comparaciones entre variables para tratar de adelantarse al futuro (Business Analytics).
Business Analytics vs. Business Intelligence (Fuente: https://wiki.smu.edu.sg/is101_2012/img_auth.php/e/ec/Business_Analytics.jpg)
Es decir, que evolucionamos del Business Intelligence tradicional al Business Analytics gracias al nuevo paradigma que trae el Big Data y los métodos de procesamiento de datos más avanzados. Con estos servicios de Business Analytics, básicamente, a una compañía, lo que podemos ofrecerle son dos tipos de explotaciones de datos:
Informar: ver lo que ha ocurrido en el pasado, y tomar decisiones reactivas (Business Intelligence).
Predecir: inferir lo que puede ocurrir en el pasado, y tomar decisiones proactivas (Business Analytics)
A partir de estos principios básicos de lo que el Business Analytics es, ya pueden ustedes imaginarse el gran potencial que tiene. Como decía al comienzo, el Business Analytics trae una inteligencia a los negocios enriquecido a través de modelos estadísticos que permiten descubrir nuevas estructuras, patrones, relaciones entre variables, etc. Esto, sumado a la era de la ingente cantidad de datos, hace que las compañías se puedan beneficiar de todo ello en muchas áreas: sanidad, educación, marketing, producción, logística, etc.
Para que se hagan ustedes a la idea, y puedan llevarlo a un plano práctico de su día a día, puede responder a preguntas como:
¿Cómo puedo descubrir más información relevante sobre mis clientes? Datos como los drivers que le llevan realmente a comprar, cómo se relacionan mis clientes entre ellos, qué opiniones son las que han sido clave para la toma de decisión de compra, etc.
¿Qué pasaría si cambio el precio de mis productos/servicios? Es decir, disponer de un análisis de sensibilidad de una variable (precio) respecto a su impacto en otra (ventas totales de ese producto o sobre otros), de manera que puedo ver la relación entre las mismas.
¿Cómo puedo reducir la tasa de abandonos de mis clientes? Es decir, construir un modelo de propensión a la fuga, para saber qué puntos o acciones son las que pueden llevar a un cliente a abandonarme. De esta manera, a futuro, tendría más probabilidad de encontrar clientes que pudieran marcharse de la compañía.
¿Cómo puedo identificar a los clientes más rentables? No desde el punto de vista de las ventas totales, sino del valor que extraigo de cada uno de ellos (entendiendo valor como margen de beneficio)
¿Cómo puedo detectar fraude? Analizando el histórico de valores que van tomando las variables para los casos de éxito (no hay fraude, se paga a tiempo, no hay insolvencias, etc.) y los de fracaso (fraudes, impagos, etc.), se pueden construir modelos que relacionen las variables que frecuentemente están asociados a los casos de fracaso, y así poder anticiparse a futuro.
etc.
Para poder hacer esto, como pueden imaginarse, los métodos de descubrimiento de información resultan fundamentales. Bueno, partiendo de la base que lo más importante es que tengamos bien preprocesada nuestra información, porque sin eso, cualquier algoritmo fallará. Esto es precisamente lo que hablamos al introducir los ETL y la importancia de la calidad de datos y su preprocesado.
Los métodos a utilizar son variados y a veces uno no sabe cuál de ellos va a dar mejores resultados o cuál de ellos se adecúa a lo que yo realmente estoy buscando. En el blog Peekaboo publicaron un cheat sheet (una «chuleta» de toda la vida) que utilizo siempre en los cursos introductorios a Business Analytics, dado que es bastante expreisva.
Selección de la técnica de tratamiento de datos más adecuada (Fuente: http://1.bp.blogspot.com/-ME24ePzpzIM/UQLWTwurfXI/AAAAAAAAANw/W3EETIroA80/s1600/drop_shadows_background.png)
Más que una chuleta, es un flujograma que terminará en el método que deberíamos utilizar para el objetivo que perisgamos. Como podéis ver, simplemente navegando por las preguntas que se van realizando a través del flujograma, puedo llegar yo a saber qué familia de tratamiento de datos es la más adecuada para los objetivos que persigo.
Como podéis comprobar, el punto de partida es tener una muestra de 50 instancias/observaciones. A partir de ahí, o bien debemos buscar más, o bien poder seguir navegando hasta encontrar el método más adecuado. ¿Qué buscamos?
¿Predecir una categoría? Los clasificadores pueden servir para alcanzar estos objetivos.
¿Agrupar mis instancias/observaciones por un comportamiento común? Las técnicas de clusterización me permiten a mí agrupar observaciones por patrones similares.
En definitiva, ya podéis observar cómo la ayuda a la toma de decisiones estratégicas (el Business Intelligence tradicional), se ha visto enriquecido gracias a dos nuevas dimensiones: una tecnológica (el Big Data) y otra matemática/estadística. ¿A qué esperas para sacar valor del Business Analytics en tu organización?
Asistiendo a una jornada de Alex Rayón, es cada vez más evidente que la forma de hacer marketing tiene que cambiar. Alex es director del seminario de Big Data & Business Intelligence (BDBI), organizado entre la Facultad de Ingeniería de Deusto y Deusto Business School, y profesor e investigador en la Universidad de Deusto sobre Marketing y Big Data y muy activo en esta área.
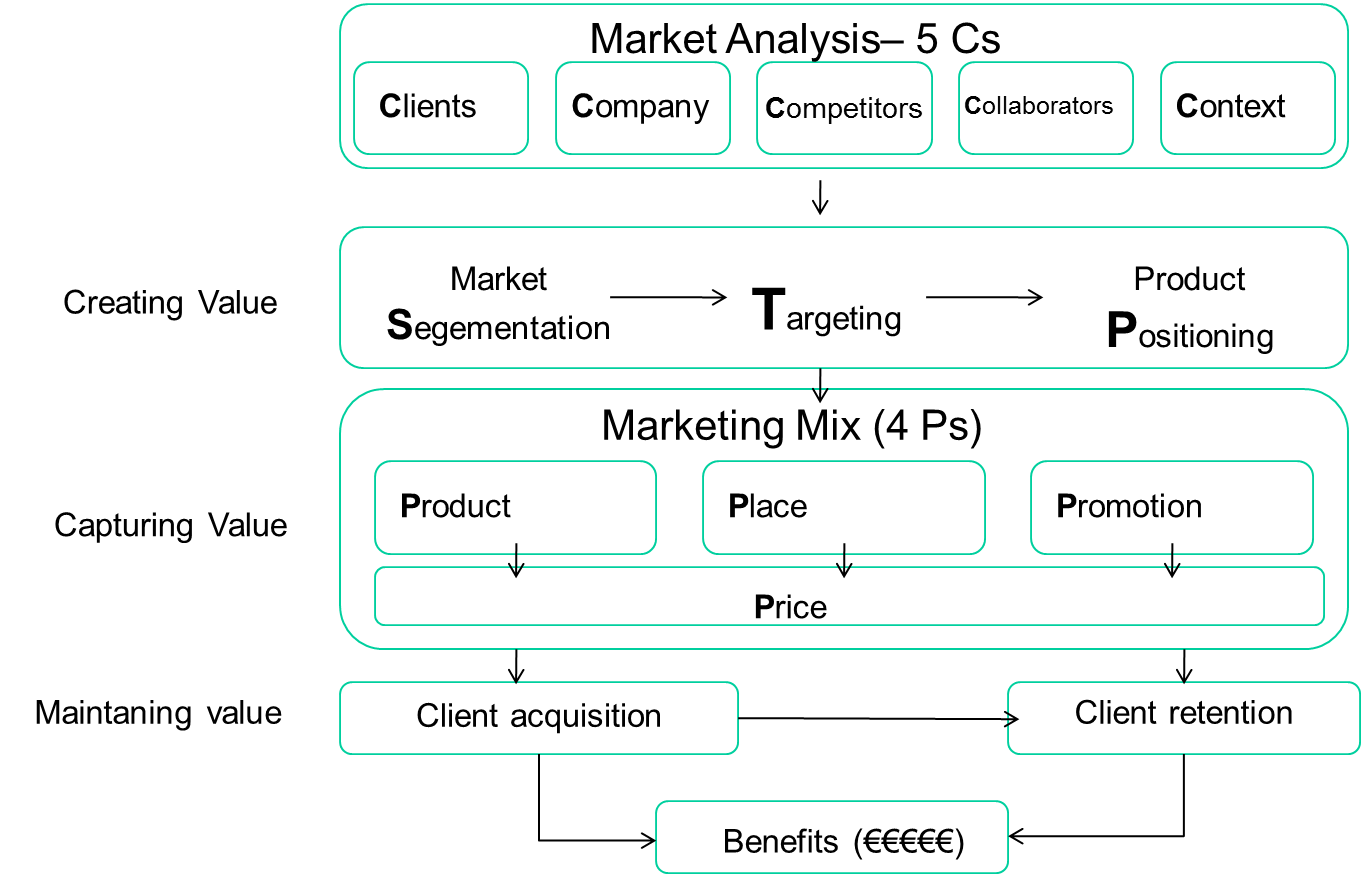
Desde el punto de vista de marketing, tradicionalmente el proceso del marketing (marketing estratégico y marketing operacional) se puede ilustrar con la siguiente figura:
El proceso de marketing (Fuente: elaboración propia)
Evidentemente en el análisis de las 5C, todos los datos que se puedan traducir en información ayudarán a tener un mejor diagnóstico de nuestro entorno.
Pero lo que me interesa de esta jornada es la aplicación del BDBI en la creación de valor para el cliente. Una de las claves en el marketing es la segmentación (¿quién es mi cliente?). Tradicionalmente las empresas identifican quién es su público objetivo, basado en parámetros demográficos, sociales, económicos, comportamiento, etc… de un mercado más general. Con esta identificación, buscan cuáles son sus problemas, necesidades, etc… escogen un público determinado y se posicionan en ese nicho.
Como decía Kotler, gurú del marketing del siglo pasado – como pasa el tiempo-, si resuelves el problema de segmentación, automáticamente tendrás las respuestas para definir tus 4Ps (producto, promoción, lugar y precio) y te saldrán automáticamente. Porque una vez sabes quién es tu potencial cliente, ya sabes qué producto tienes que ofrecerle, qué ventajas tiene que tener sobre los competidores, dónde está y cómo poder llegar a él, qué precio está dispuesto a pagar. Teniendo muy claro quién es mi cliente, cuántas horas de reuniones nos podríamos ahorrar discutiendo sobre el precio…
Evidentemente BDBI tiene mucho que decir en la segmentación. Pero no tanto a priori, si no a posteriori. Con la cantidad de datos que las empresas tienes sobre nosotros, ya no hace falta hacer hipótesis de quién es nuestro cliente: basta mirar en los datos e identificarlos.
Gracias a las herramientas de BDBI (que por cierto, ni son caras ni difíciles de usar), basta un poco de curiosidad, jugar con los datos y empezar a ver correlaciones. ¿Hay alguna relación entre los clientes que compran 2 mismos productos? ¿Es nuestra segmentación inicial la que se refleja en las compras de nuestros clientes y las ventas de nuestros productos? ¿A qué horas del día hay un comportamiento de compra parecido? Por ejemplo, en Tableau, una empresa que intenta facilitar la visualización de BDBI, podéis ver un caso sobre la segmentación y el hecho de cuestionarnos nuestras hipótesis iniciales.
Esta aproximación que aparentemente parece que es sólo válida para comercios B2C online se pueden extraer de otros lugares. El BDBI no es exclusivo de negocios online, nacidos en la era digital. Efectivamente, lo tienen más fácil, pero todas las empresas pueden empezar a explorar. Quizás sea ese uno de los retos para la implementación del BDBI en los negocios que no vienen del mundo online. Como comentaba Alex, un 60%- 80% de los esfuerzos para una estrategia de BDBI se centran en los datos y en el ETL (Extracción, Transformación y carga o Load), encontrarlos entre las diferentes partes del negocio (ERPs, CRM, departamento financiero, controller, etc…), limpiarlos y ponerlos bonitos. Aunque Alex menciona 4 etapas y el tiempo que se va a dedicar a cada etapa:
Etapa 1: Cargar datos (hasta un 80%)
Etapa 2: Preguntas (5%)
Etapa 3: Modelo estadístico/analítico (5%)
Etapa 4: Visualización de resultados (10%)
Quizás mi visión sería empezar por las preguntas y terminar en el modelo estadístico. Pero lo que estoy seguro es que una de las grandes aportaciones del BDBI al marketing es en el tema de segmentación, pasando de una segmentación clásica a una clusterización (que hasta ahora era más complicado). La maravilla del BDBI es que no tenemos que pensar cuáles son las variables para hacer el cluster, las propias herramientas nos dirás qué cluster son los que representan mejor a los clientes y qué características. También, incluso nos permitirá saber cuál es la probabilidad de que un cliente de telefonía abandone su compañía y qué características tiene o saber la características del cliente de un banco portugués que no compra un producto y el proceso comercial asociado. Y por otra parte, ayudarnos a hacer preguntas que hasta ahora ni nos habíamos imaginado.
Lo que está claro, es que si una empresa quiere sobrevivir en los próximos 10 años, de una forma u otra, el BDBI le impactará de alguna manera. La pregunta es ¿espero a que me obliguen o empiezo a explorar ya? La creación de valor en mi organización a través del Big Data y Business Intelligence está a mi disposición.