El pasado miércoles 5 de Abril, tuvimos la ceremonia de entrega de diplomas de la promoción de 2016 de nuestro Programa de Big Data y Business Intelligence en la sede de Bilbao. Un total de 58 alumnos, a los que queremos extender nuestra felicitación desde aquí también.
Pero quizás, una de las mejores noticias que pudimos recibir ese día es que uno de esos 58, Iker Ezkerra, Alumni de dicha promoción, nos comunicó que había quedado 10º clasificado en una competición de Big Data que había organizado Microsoft. Concretamente en esta:
Una competición en la que el objetivo era desarrollar un modelo predictivo de eventuales impagos de clientes que solicitaban un préstamos hipotecario. Todo ello, utilizando tecnologías de Microsoft. Un reto interesante dado que la validación del modelo que cada participante desarrollaba, se realizaba con con 2 datasets que cada participante no conocía a priori. Se va escalando posiciones en el ranking en función del scoring que va obteniendo el modelo. ¿El resultado? El citado décimos puesto para Iker, además de obtener la certificación «Microsoft Professional Program Certificate in Data Science«.
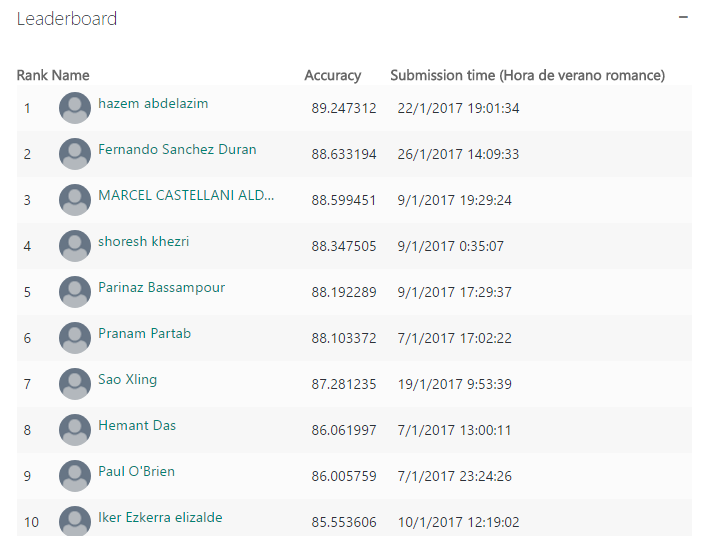
Dentro de este proyecto, Iker tuvo que aprender un poco sobre la mecánica de concesión de créditos. Cuando solicitamos un préstamos hipotecario al banco, estas entidades financieras utilizan modelos estadísticos para determinar si el cliente va a ser capaz de hacer frente a los pagos o no. Las variables que influyen en esa capacidad de devolver el capital e intereses son muchos y complejos; ahí radica parte de la dificultad de esta competición, y donde Iker tuvo que trabajar mucho con los datos de origen para tratar de entender y acorralar bien a las variables que mejor podrían predecir el eventual «default» de un cliente.
Un total de 110.000 registros, para entrenar un modelo de Machine Learning. Por si alguien se anima en ver todo lo que pudo trabajar Iker, aquí os dejamos un enlace donde podréis encontrar el dataset. Y aquí los criterios de evaluación seguidos, que creo pueden ser interesantes para entender cómo funcionan este tipo de modelos predictivos.
Le pedí a Iker un breve párrafo describiendo su experiencia, dado que al final, nadie mejor que él para describirla. Y, muy amablemente, me envío esto, que para nosotros, desde Deusto Ingeniería, es un placer poder leer:
En los últimos meses del Programa en Big Data buscando documentación, formación y sobre todo datos que pudiese utilizar en un proyecto con el que poder poner en práctica los conocimientos que estaba adquiriendo me encontré con una Web esponsorizada por Microsoft en la que se ofrecen varios retos en los que poder poner en práctica tus conocimientos en análisis de datos. Estos retos ofrecen una visión bastante completa de lo que sería el ciclo de vida de un proyecto de análisis de datos como la limpieza del dataset, detección de outliers, normalización de datos, etc. Además algo que para mi ha sido muy interesante es que detrás de cada modelo que vas entrenando hay una «validación» de lo «bueno» que es tu modelo con lo que te sirve para darte cuenta de si tienes problemas de overfitting, limpieza de datos correcta, etc. Ya que por detrás de todo esto hay un equipo de gente que valida tu modelo con otros 2 datasets obteniendo un «score» que te permite ir escalando posiciones en una lista de competidores a nivel internacional.
Con todo esto y tras muchas horas de trabajo conseguí obtener la décima posición que para alguien que hace 1 año no sabía ni lo que era la KPI creo que no está nada mal :). Así que animo a todo el mundo con inquietudes en el mundo del dato a participar en este tipo de «competiciones» que te permiten poner a prueba los conocimientos que has adquirido y también a quitarte complejos en esta área de la informática que para algunos nos es nueva.
Felicidades, Zorionak, Congratulations, una vez más, Iker. Un placer poder disfrutar de vuestros éxitos en el mundo del Big Data.

