El interés por el concepto de «machine learning» no para de crecer. Como siempre, una buena manera de saberlo, es utilizando herramientas de agregación de intereses como son Google Trends (las tendencias de búsquedas en Google) y Google N Gram Viewer (que indexa libros que tiene Google escaneados y sus términos gramaticales). Las siguientes dos imágenes hablan por sí solas:
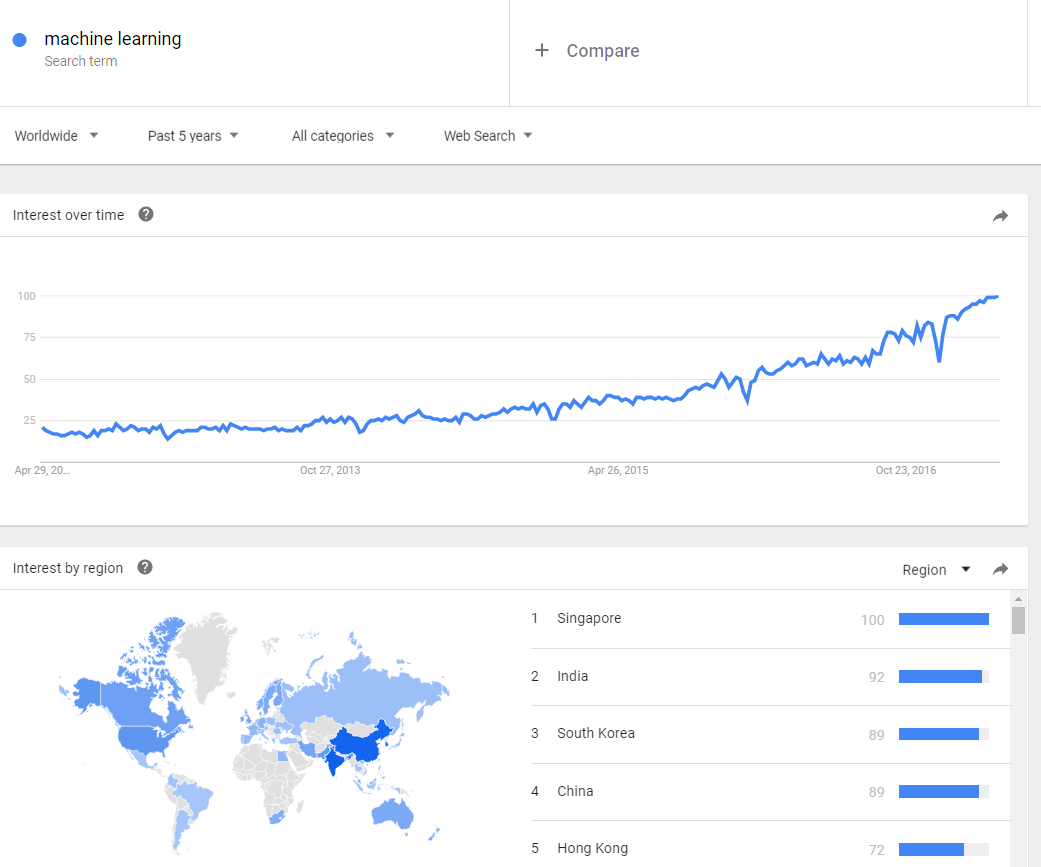
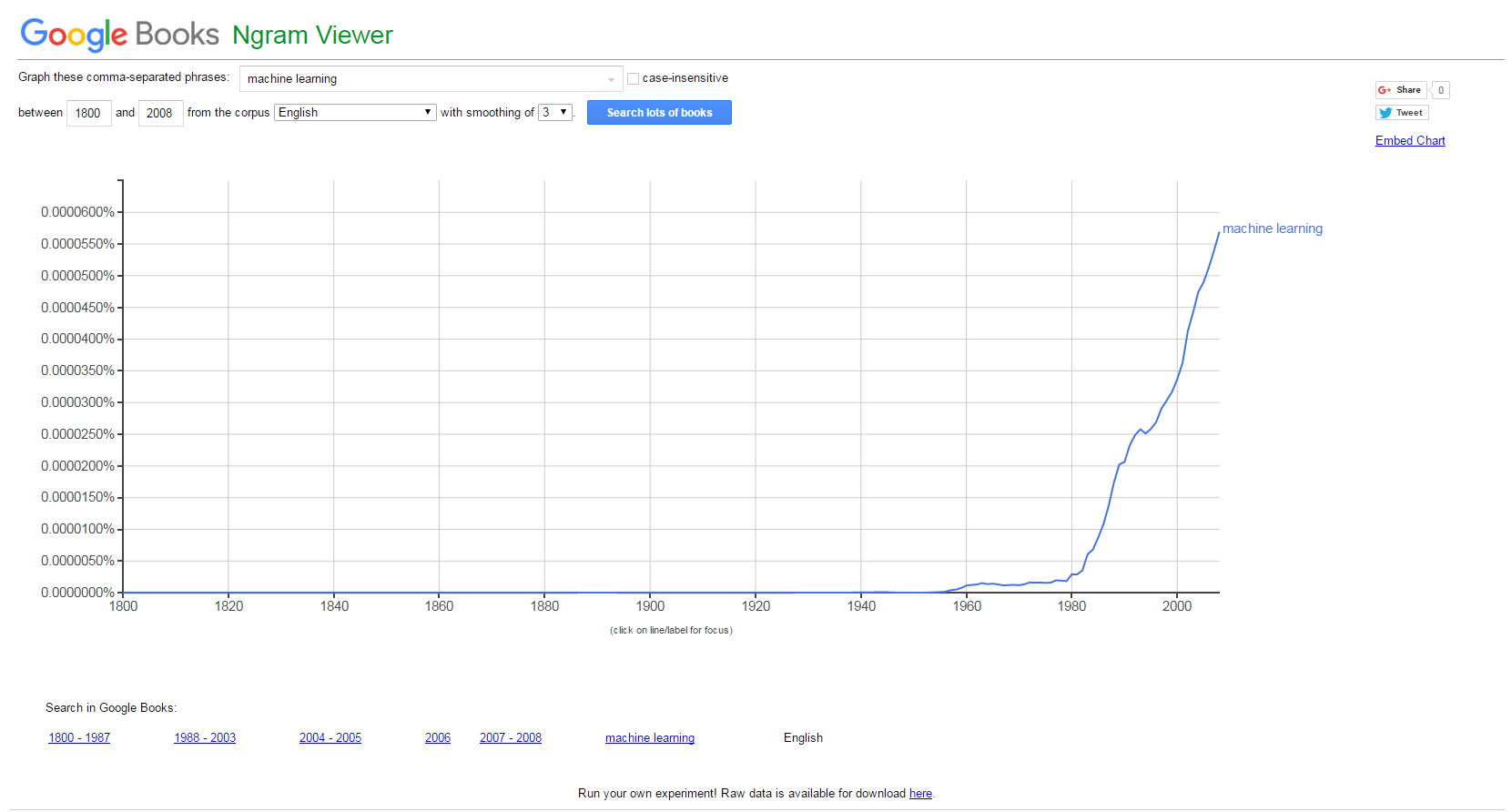
Sin embargo, no se trata de un término nuevo que hayamos introducido en esta era del Big Data. Lo que sí ha ocurrido es el «boom de los datos» (derivado de la digitalización de gran parte de las cosas que hacemos y nos rodean) y el abaratamiento de su almacenamiento y procesamiento (básicamente, los ordenadores y sus procesadores cuestan mucho menos que antes). Vamos, dos de los vectores que describen esta era que hemos bautizado como «Big Data».
Los algoritmos de machine learning están viviendo un renacimiento gracias a esta mayor disponibilidad de datos y cómputo. Estos dos elementos permiten que estos algoritmos aprendan conceptos por sí solos, sin tener que ser programados. Es decir, se trata de ese conjunto de reglas abstractas que por sí solas son construidas, lo que ha traído y permitido que se «autonconfiguren».
La utilidad que tienen estos algoritmos es bastante importante para las organizaciones, dado que son especialmente buenos para adelantarnos a lo que pueda ocurrir. Es decir, que son bastante buenos para predecir, que es como sabéis, una de las grandes «inquietudes» del momento. Se pueden utilizar estos algoritmos de ML para otras cuestiones, pero su interés máximo radica en la parte predictiva.
Este tipo de problemas, los podemos clasificar en dos grandes categorías:
- Problemas de regresión: la variable que queremos predecir es numérica (las ventas de una empresa a partir de los precios a fijar)
- Problemas de clasificación: cuando la variable a predecir es un conjunto de estados discretos o categóricos. Pueden ser:
- Binaria: {Sí, No}, {Azul, Rojo}, {Fuga, No Fuga}, etc.
- Múltiple: Comprará {Producto1, Producto2…}, etc.
- Ordenada: Riesgo {Bajo, Medio, Alto}, ec.
Estas dos categorías nos permiten caracterizar el tipo de problema a afrontar. Y en cuanto a soluciones, los algoritmos de machine learning, se pueden agrupar en tres grupos:
- Modelos lineales: trata de encontrar una línea que se «ajuste» bien a la nube de puntos que se disponen. Aquí destacan desde modelos muy conocidos y usados como la regresión lineal (también conocida como la regresión de mínimos cuadrados), la logística (adaptación de la lineal a problemas de clasificación -cuando son variables discretas o categóricas-). Estos dos modelos tienen tienen el problema del «overfit»: esto es, que se ajustan «demasiado» a los datos disponibles, con el riesgo que esto tiene para nuevos datos que pudieran llegar. Al ser modelos relativamente simples, no ofrecen resultados muy buenos para comportamientos más complicados.
- Modelos de árbol: modelos precisos, estables y más sencillos de interpretar básicamente porque construyes unas reglas de decisión que se pueden representar como un árbol. A diferencia de los modelos lineales, pueden representar relaciones no lineales para resolver problemas. En estos modelos, destacan los árboles de decisión y los random forest (una media de árboles de decisión). Al ser más precisos y elaborados, obviamente ganamos en capacidad predictiva, pero perdemos en rendimiento. Nada es gratis.
- Redes neuronales: las redes artificiales de neuronas tratan, en cierto modo, de replicar el comportamiento del cerebro, donde tenemos millones de neuronas que se interconectan en red para enviarse mensajes unas a otras. Esta réplica del funcionamiento del cerebro humano es uno de los «modelos de moda» por las habilidades cognitivas de razonamiento que adquieren. El reconocimiento de imágenes o vídeos, por ejemplo, es un mecanismo compleja que nada mejor que una red neuronal para hacer. El problema, como el cerebro humano, es que son/somos lentos de entrenar, y necesitan mucha capacidad de cómputo. Quizás sea de los modelos que más ha ganado con la «revolución de los datos»; tanto los datos como materia prima, como procesadores de entrenamiento, le vienen como anillo al dedo para las necesidades que tienen.
En el gran blog Dataconomy, han elaborado una chuleta que es realmente expresiva y sencilla para que podamos comenzar «desde cero» con algoritmos de machine learning. La tendremos bien a mano en nuestros Programas de Big Data en Deusto.

