Como saben, la semana pasada, organizamos un evento titulado «Las tecnologías Big Data al servicio de la sociedad«. Un evento en el que a través del famoso caso de los Papeles de Panamá, tratábamos de divulgar la utilidad que tiene este nuevo paradigma del Big Data -sus métodos y tecnologías- también para beneficio de toda la sociedad.
Iremos, a lo largo de los próximos días difundiendo los contenidos y materiales generados para esa sesión. Empezamos la serie hablando de la intervención de Mario Iñiguez, Co-founder de Adamantas Analytics, que nos explicó cómo poner en valor las tecnologías de Big Data con las Bases de Datos NoSQL de grafos.
Las Bases de Datos NoSQL aparecen a la par de la explosión de la web 2.0. En ese momento, se produce un crecimiento espectacular del volumen de datos. Además, generado por el propio usuario, con información volátil, variada, no estructurada y extensa. Las relaciones se multiplican, no existe una estructuración previa. En este contexto, el paradigma de Bases de Datos Relacional que venimos usando desde los años 70, nos limitaba mucho. Un modelo de datos estático y con dificultad de adaptación a cambios, que dispone de relaciones explícitas entre tablas, es un paradigma que no casa bien con esta explosión de datos no estructurados.
Ahí es cuando empezamos a hablar de la necesidad de disponer de un nuevo paradigma. Lo bautizamos como NoSQL, manifestando claramente su desvinculación de este paradigma relacional que había venido siendo imperante hasta entonces. Y, aparecen, cuatro nuevos tipos de bases de datos:
- Clave valor: el más popular, además de ser la más sencilla en cuanto a funcionalidad. Cassandra, BigTable o HBase son ejemplos de este tipo. Son bastante eficientes tanto en lectura como en escritura. En nuestro programa vemos Cassandra.
- Columnares: las bases de datos, en lugar de estar estructuradas por filas, están estructuradas por columnas. Al tratarse de una sola dimensión, hace más eficiente la recuperación de la información. En nuestro programa, trabajamos con Vertica.
- Documentos: almacena la información como un documento, permitiendo realizar consultas bastante avanzadas sobre el mismo. Por ello, suele considerarse como el más versátil. MongoDB o CouchDB son ejemplos de ello. Nosotros en nuestro Programa de Big Data hacemos alguna sesión práctica con MongoDB.
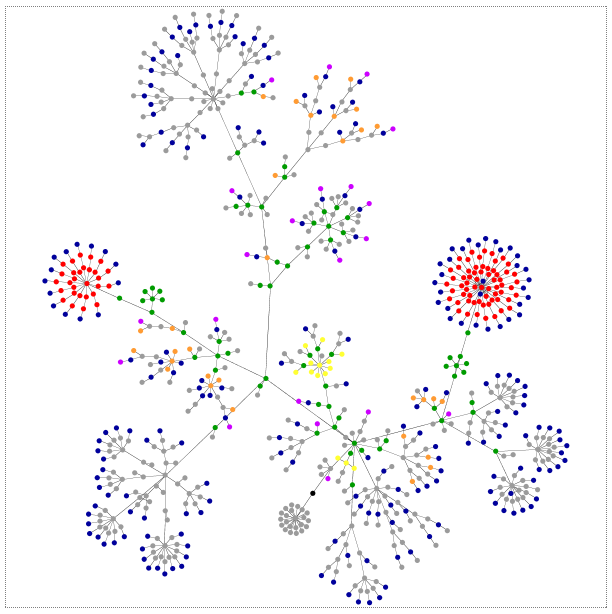
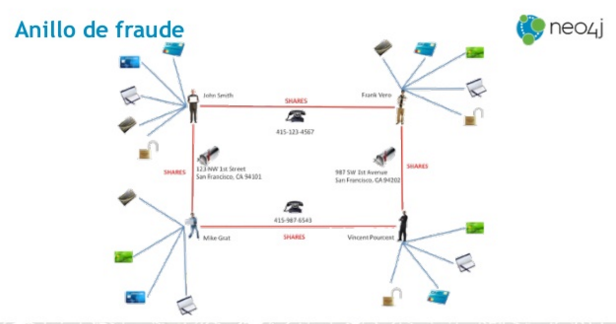
- Grafos: los datos son representados como nodos y aristas que modelizan la relación entre esos nodos. De esta manera, podemos emplear la teoría de grafos -de lo que ya hemos hablado en el pasado– para recorrer y navegar por su contenido. Su principal ventaja es que permite una navegación más eficiente entre relaciones que en un modelo relacional. Neo4J -la empleada en el caso de los Papeles de Panamá- o Virtuoso son ejemplos de ello, siendo Neo4J la que vemos en nuestro programa y sobre la que sacaremos un programa específico el próximo Otoño (dada la relevancia que va adquiriendo, por lo que ya informaremos de ellol).
Este último tipo, el de grafos, fue el que nos introdujo Mario y sobre el que nos contó sus bondades. Uno de los elementos que destacó Mario es cómo esta forma de representar la información se aproxima bastante al pensamiento humano (cómo representamos la información en nuestro cerebro). A través de varios ejemplos (éste de Open Corporates de Goldman Sachs o éste de la complejidad económica del MIT), vimos las principales ventajas de representar la información en grafos. Que, básicamente, se resumen en un tiempo de ejecución bastante menor que una base de datos relacional (en la transparencia 7 de la siguiente presentación podéis ver la comparativa empírica que hizo Mario).
Para concluir, Mario nos resumió las principales utilidades de este nuevo tipo de bases de datos NOSQL de grafos:
- Disponer de más información con agilidad y eficiencia (lugares más visitados, análisis de sentimiento, rutas y medios, quejas y reclamaciones, círculos de influencia, etc.)
- Y, desencadenar acciones (mejora de infraestructuras, mejora de servicios, mejora de la oferta turística, oportunidades de negocio, promoción comercio local)
Además, os dejamos un vídeo donde le preguntaba por los principales puntos que trató durante su intervención y que provocó varias preguntas de la audiencia. Como concluíamos, el modelo relacional podría tener sus días contados si las tecnologías de BBDD NoSQL siguen mejorando el rendimiento y resultados de procesar grandes cantidades de datos. Será interesante ver la evolución.