Las pasadas elecciones americanas, han vuelto a poner encima de la mesa un debate que parece ya clásico: los (supuestos) fallos de las encuestas. El debate también salió con la infravaloración que se hizo a la victoria del Partido Popular el pasado 26-J, el «sorpasso» que las encuestas vaticinaron o en el Brexit.
Las encuestas, como modelos que son, son una aproximación a la realidad. Lo que suele fallar en esos modelos de aproximación no son tanto los métodos predictivos empleados, sino cómo se pondera la idea de la incertidumbre. Y es que estos ejercicios de adelantarnos a lo que puede ocurrir en un futuro (predecir), nunca borran ni eliminan la incertidumbre. El mundo es así, no es lineal.
Lo que ocurre es que nuestra mente no funciona bien bajo incertidumbre, por lo que la encanta utilizar las predicciones como una idea cerrada y segura. Así manejamos la información con más facilidad, reducimos nuestra fatiga cognitiva, y podemos conversar sobre los temas con más facilidad con la gente.
Pero los modelos predictivos, como decía, no son tan sencillos. Ni los modelos estadísticos para tratar de hacer una previsión de los resultados electorales, ni los que tratan de predecir qué ocurrirá en la economía o con la meteorología. Siempre habrá incertidumbre.
Miremos el caso de las elecciones americanas para ilustrar la idea de cuándo y por qué puede fallar un modelo predictivo. Cuando hablamos del Teorema de Bayes, ya dijimos que predecir consta de tres partes constituyentes:
- Modelos
- Calidad de datos
- Juicio humano
Vayamos por partes. Los modelos. Ningún modelo es perfecto, el famoso aforismo de la estadística («All models are wrong«) de George Box que citó en este artículo de 1976. A sabiendas que la ciencia política llevada décadas estudiando el campo, que hay gente realmente buena detrás construyendo modelos predictivos (FiveThirtyEight, Predictwise, etc.), no tengo la sensación de que fuera un problema metodológico de captura de mecanismos -atributos, variables predictoras- de elección de presidente (comportamiento de los diferentes estados, variables económicas y sociales, momentum, ruido social, etc.).
No obstante, como señala este reportaje de New York Times, es posible y probable que los modelos no recogieran bien cómo Trump desplazó el debate a la derecha y ganó en zonas rurales el gran soporte urbano que tenía Clinton. Aquí juegan otros elementos (el mecanismo de asignación de electores), pero entiendo eso sí estaba recogido. Como veis, más incertidumbres que certezas. Pero esto es lo que tiene hacer modelos; a posteriori te das cuenta, pero a priori es difícil estimar las mejores variables a incorporar.
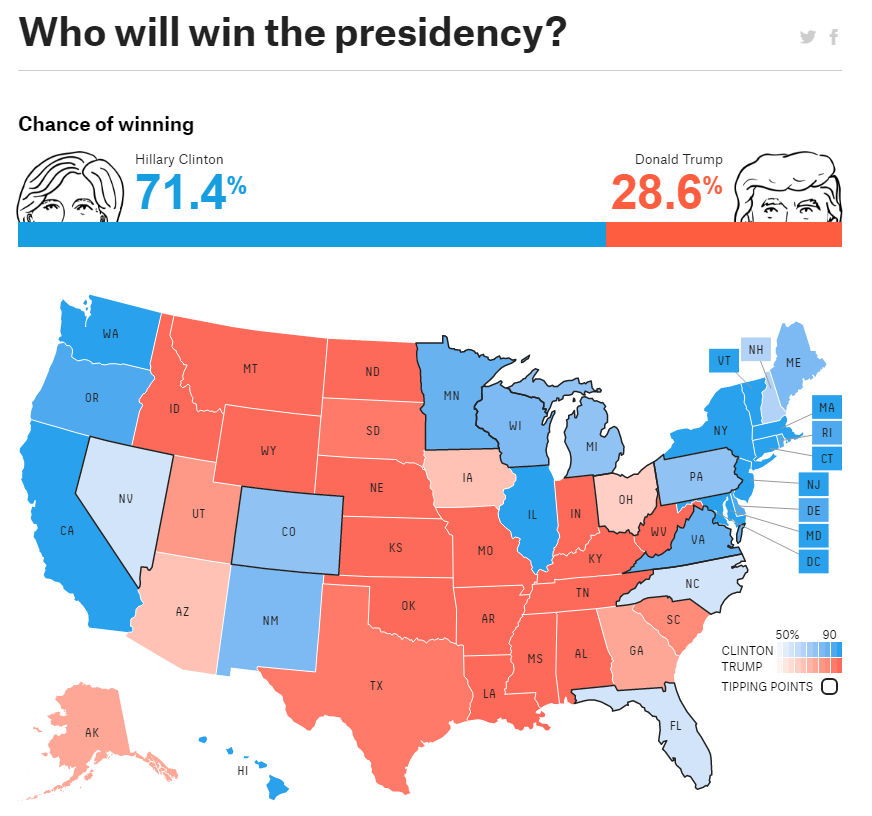
En segundo lugar, los datos en sí. De su calidad y su vital importancia, también hemos hablado mucho por aquí. Evidentemente, en un proceso electoral en el que cada vez los medios digitales tienen mayor protagonismo, es un candidato este eje a ser considerado. La falta de veracidad de las respuestas de las encuestas (no sea que alguien se entere que voy a votar a Trump, incluso un fallo de memoria, por las prisas con las que se suele responder), el sesgo de respuesta (te respondo a lo que tú me preguntas, no más), sesgos muestrales (¿cómo preguntar a todos a sabiendas de la ausencia de uso de medios digitales o telefónicos en muchos casos?, aquí es donde entraría el margen de error), etc. Es por todos estos problemas de los datos por los que cada vez hay más «cocina» o corrección de las respuestas por quién lo ha podido preguntar/hacer la encuesta. Por otro lado, no olvidemos la cada vez mayor importancia de las redes sociales, donde los efectos de red son difíciles de recoger todavía a nivel metodológico. Por todo esto, es probable que los datos que lleguen a los modelos, no sean los mejores en estos momentos. Y que haya mucho que mejorar aún en toda esta parte.
En tercer y último lugar, esta la interpretación de los resultados que ofrece un modelo. Es decir, el juicio humano. Como decíamos al comienzo, es difícil en ocasiones, en un modelo predictivo, explicar a la gente que todo lo que aquí se «modeliza» es una aproximación a una realidad mucho más complicada que lo que un modelo representa. Esa diferencia, ese gap, es lo que ponderamos con la incertidumbre. Como no sabemos lo que va a ocurrir con 100% de certeza, lo expresamos. Un intervalo de confianza del 95%, no garantiza, obviamente, nada. Este valor quiere decir que de cada 20 muestras sobre esa misma población (el electorado americano), 19 veces, el valor a predecir (el resultado electoral), estará contenido en el modelo. Solo se «fallará» (que tampoco es un término del todo correcto en este contexto), en 1 de cada 20 ocasiones. ¿Puede ser este el caso de la victoria de Donald Trump o el resto de situaciones explicadas al comienzo? Es posible y probable.
Como ven, hacer un modelo predictivo no es un tarea sencilla. Por ello, es bueno manejar esta terminología básica de elementos críticos a considerar para saber muy bien lo que se está haciendo. En nuestros Programas de Big Data, por eso empezamos siempre hablando de modelado y calidad de datos, para luego empezar con la estadística y los modelos de aprendizaje supervisado y no supervisado (Machine Learning). No todo es software, claro.
