En este blog, ya hemos hablado con anterioridad de diferentes herramientas para emprender proyectos de analítica. Fue en esta entrada, comparando más allá a nivel de herramienta, cuando comparábamos R, Python y SAS, que son sobre las que pivotamos en nuestros Programas de Big Data.
El mundo de la analítica está avanzando a la velocidad de la luz, por lo que es importante que escribamos artículos volviendo a esa pregunta original sobre ¿Qué lenguaje utilizar para Data Science? No es una pregunta sencilla, porque las opciones existentes no son pocas.
La pregunta se vuelve más complicada aún en contextos como el nuestro. Tenemos que enseñar y aprender desde cero la disciplina de Data Science. Y una pregunta muy recurrente de parte de nuestros alumnos de Bilbao, Donostia y Madrid, es, ¿por qué lenguaje empieza para arrancar en este mundo del Big Data?
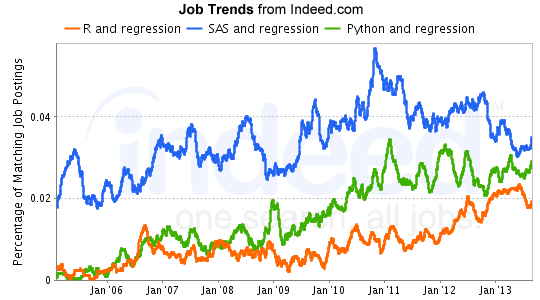
Son muchas los lenguajes que ofrecen las capacidades para ejecutar operaciones de análisis de datos de una manera más eficiente que los lenguajes tradicionales (C++, C, Java, etc.). Entre ellos, destacan algunos sospechosos habituales, y otros que están emergiendo con fuerza: R, Python, MATLAB, Octave y Julia. Éste es el menú en el que tenemos que elegir; decisión, como suele pasar con estas cuestiones, no sencilla. Dejo fuera de esta comparación soluciones analíticas como SAS, Stata o Excel, básicamente, porque no están orientadas a nivel de «lenguaje de programación», sino a nivel de herramientas.
En esta entrada, y para poder encontrar un ganador, se han comparado los lenguajes en varias dimensiones: velocidad de ejecución, curva de aprendizaje requerida, capacidades de ejecutar acciones de analítica de datos, soporte a la visualización, entornos de desarrollo, facilidad de integración con otros lenguajes/aplicaciones y las oportunidades de trabajo existentes.

Obviamente, debemos notar que las calificaciones otorgadas en cada dimensión son la opinión de Siva Prasad, la persona que lo ha elaborado. Por lo tanto, creo que no debemos tampoco sacar conclusiones exclusivamente de ello. Creo que lo más ilustrativo del caso es fijarse en que en función de cuál sea el objetivo y la necesidad concreta, hay diferentes opciones que explorar.
Lo que sí me parece igualmente interesante, son la utilidad que puede tener en función del punto en el que cada uno se encuentre. El autor, en su entrada, destaca que:
If you are a graduate student, it’s good to start with Python
Si somos estudiantes de Grado, que estamos arrancando, sugiere emplear Python.
If you are a research scholar, good to start with R and explore Octave
Si estamos por la vía de la investigación/doctorado, sugiere el empleo de R y/o Octave.
If you are an employee, I suggest to master both Python and R
Si eres una persona ya trabajando en la industria, parece que las mejores apuestas pasan por Python y R.
If you are tech enthusiast and love exploring/learning new things, you can learn Julia
Si eres un entusiasta tecnológica y te gusta explorar/aprender nuevas cosas, métete con Julia (yo, estoy en esta etapa, haciendo modelos de optimización con Julia, que es realmente potente e interesante).
If the data needs to try several different algorithms, choose R
Si necesitamos probar diferentes algoritmos para tratar el conjunto de nuestros datos, prueba con R.
If you need to use data structures and integrate with external applications, use Python
Si tenemos que utilizar muchas estructuras de datos e integrar los mismos con aplicaciones externas, probemos con Python.
Para gustos están los colores. En definitiva, que no consideremos esto como conclusiones a escribir en un libro. Pero sí por lo menos, para orientarnos, y tener primeras aproximaciones a la ciencia de datos, Data Science, así como las opciones que abre cada uno de ellos. Disfruten de todos ellos 🙂