Lo que podemos llamar como la cadena de valor de un proyecto Big Data consiste básicamente en recopilar/integrar/ingestar, procesar, almacenar y servir grandes volúmenes de datos. Eso es, en esencia, lo que hacemos en un proyecto de BIg Data. Para ejecutar esas funciones, como hemos comentado en este blog en varias ocasiones, tenemos una serie de tecnologías, que suelen ser citadas en ocasiones en relación a la función que ejercen. Es lo que aprendemos en nuestro módulo M2.2 del Programa de Big Data y Business Intelligence de nuestra universidad.
Dado el interés que está despertando en los últimos años la parte «procesamiento» (debido fundamentalmente a cómo se origina esto del Big Data) es interesante hablar de las diferentes alternativas tecnológicas que existen para procesar «Big Data». Ya saben, datos que se disponen en grandes volúmenes, que se generan a gran velocidad y con una amplitud de formatos importante.
Esta etapa de la cadena de valor es la responsable de recoger los datos brutos y convertirlos/transformarlos a datos enriquecidos que pueden dar respuesta a la pregunta que nos estamos haciendo. Y para enfrentar esta etapa, en los últimos años, se han desarrollado dos paradigmas fundamentales:
- Paradigma «Batch Processing«: son procesos que se asientan fundamentalmente en el paradigma MapReduce, que ya explicamos en un artículo anterior, y que decíamos, permitió comenzar esta apasionante carrera alrededor del Big Data. Siguen el modelo «batch» que tan importante resultó en el mundo de la informática original: se ejecutan de manera periódica y trabajan con grandísimos volúmenes de datos.
Existen varias alternativas para proveer de estos servicios: la más importante es Hadoop MapReduce, que funciona dentro del framework de aplicaciones de Hadoop. Se apoya en el planificador YARN. Dado el bajo nivel con el que trabajan estas tecnologías, estos últimos años han nacido soluciones de más alto nivel para ejecutar estas tareas, tales como Apache Pig.
Estamos hablando de tecnologías que funcionan realmente bien con grandes cantidades de datos. Sin embargo, los procesos de Map y Reduce pueden ser algo lentos cuando estamos hablando de cantidades realmente «BIG», dado que escriben en disco entre las diferentes fases. Por ello, como siempre, se produce una evolución natural, y aparecen tecnologías que resuelven este problema, entre las que destaca Apache Spark.
Haremos un artículo separado, dada su importancia, para hablar exclusivamente y en detalle de este paradigma «Batch Processing«. - Paradigma «Streaming Processing«: a diferencia del enfoque «batch» anterior, el «streaming», como su propio concepto describe, funciona en tiempo real. Si antes decíamos que un proyecto «Big Data» consta de cuatro etapas –(1) Ingestión; (2) Procesamiento; (3) Almacenamiento y (4) Servicio-, con este enfoque, nada más ser «ingestados», son transferidos a su procesamiento. Esto, además, se hace de manera continua. En lugar de tener que procesar «grandes cantidades», son, en todo momento, procesadas «pequeñas cantidades».
Como con el enfoque batch, hay una serie de tecnologías que permiten hacer esto. Se pueden clasificar en dos familias: 1) Full-streaming: Apache Storm, Apache Samza y Apache Flink; y 2) Microbatch: Spark Streaming y Storm Trident.
Son tecnologías que procesan datos en cuestión de mili o nanosegundos. Se diferencian entre ellas por las garantías que aportan ante fallos en la red o en los sistemas de información. La siguiente tabla resume muy bien estas diferencias. Por lo tanto, más que por «gustos», la diferencia puede radicar en cuanto a su «sistema de garantías»: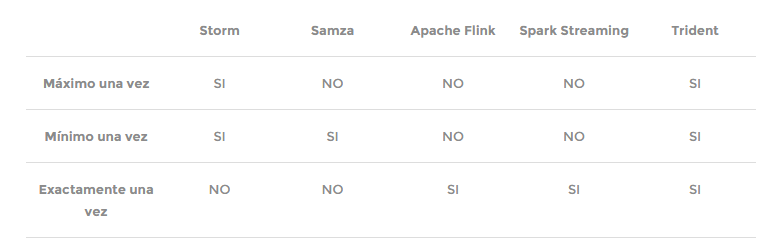
Fuente: http://madrid.bigdataweek.com/2015/11/18/tecnologias-en-el-mundo-del-big-data/ Haremos un artículo separado, dada su importancia, para hablar exclusivamente y en detalle de este paradigma «Streaming Processing«.
A estos dos, podemos añadir la arquitectura Lambda, la más reciente en llegar a este mundo de necesidades en evolución de las diferentes alternativas de procesar datos. Provee parte de solución Batch y parte de solución en Tiempo Real. Como su propio creador Nathan Marz explica aquí:
The lambda architecture solves the problem of computing arbitrary functions on arbitrary data in real time by decomposing the problem into three layers: the batch layer, the serving layer, and the speed layer.
Estamos hablando de diferentes paradigmas; esto es, de diferentes maneras de afrontar el problema. Y dada la importancia de cada uno de ellos, he considerado interesante hacer un artículo monográfico de cada una de ellas. Paradigmas que nos van a ayudar a procesar las grandes cantidades de datos de un proyecto de Big Data. Y conocer y empezar a dominar así las tecnologías que disponemos para cada paradigma.
