Nuestra línea de trabajo Big Data de la Facultad de Ingeniería de la Universidad de Deusto estará presente en el próximo Congreso HORECA de AECOC que se celebrará los próximos 1 y 2 de Marzo en Madrid. Me han invitado para divulgar los principales beneficios que aporta el Big Data a la HOstelería, REstauración y CAfeterías (HORECA), desde una perspectiva de negocio. Una oportunidad inigualable para presentar todos nuestros trabajos, dado que es un congreso que reúne anualmente a más de 500 directivos y empresarios de las empresas de toda la cadena de valor de la hostelería.
Venimos colaborando con AECOC en diferentes actividades. Una asociación que recoge a los fabricantes y distribuidores del gran consumo, tal y como su acrónimo indica (la Asociación Española de Codificación Comercial, los que ponen «los códigos de barras«). El curso pasado nos premiaron con el máximo máximo reconocimiento de la categoría de Tecnología Aplicada y el Accésit de la de Supply Chain por una herramienta para la mejora de la cadena de suministro (proyecto donde participó mi compañero Alberto de la Calle) y a nuestra «Deusto Moto Team«, por el diseño y creación de una moto ecológica para el transporte urbano de mercancías (proyecto de mi compañero Jon García Barruetabeña y sus estudiantes).
Y ahora, se interesan por las oportunidades que todos nuestros trabajos en Big Data brindan al sector del consumo en general, y al canal HORECA en particular. Y de ello quería hablar hoy, aprovechando que tengo que preparar las ideas para la conferencia.
Como suelo decir, el Big Data, sirve para tres cuestiones principales:
- Ganar más dinero
- Evitar perderlo por la fuga de clientes (la importancia de la fidelización)
- Ahorro de costes mediante la optimización de procesos
Dada la enorme competencia existente ya hoy en día, la diferenciación debe venir por otras vías. La gran cantidad de canales que disponen los consumidores, el bombardeo de impactos publicitarios, la gigantesca campaña de descuentos y tarjetas de fidelización, etc., está provocando que las marcas tengan que dar un paso más allá. Y, al canal HORECA todo ello le viene genial. Y es que el Big Data, permite:
- Geolocalizar el target de clientes
- Estimar el mercado potencial de clientes
- Hacer una previsión de ventas por zonas y puntos de venta
- Que permite, a su vez, optimizar el proceso de abastacimiento y logística
- Optimizar las campañas de marketing y distribución
- etc.
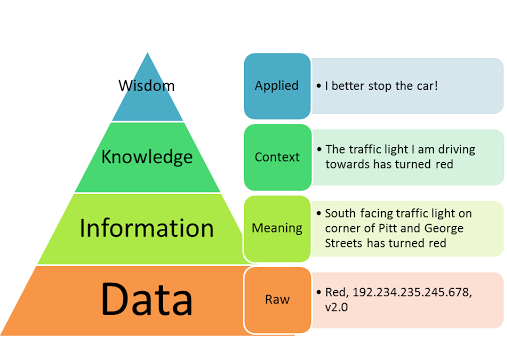
La clave para las marcas de consumo recae en ser capaces de, primero, generar y estructura bien los datos, y, en segundo lugar, ser capaces de sacar valor de los mismos transformándolos en conocimiento. Hablaré de estos dos elementos a continuación, como forma de agrupar los principales retos y oportunidades que dispone una marca de consumo hoy en día.
En primer lugar, la imperancia de disponer de «datos de calidad«. En nuestro Programa de Big Data y Business Intelligence, lo primero que hacemos es ver esta parte. Tener datos y más datos no tiene sentido por si solo. Hablamos de la importancia de disponer de:
- Un buen modelo de datos como instrumento de representación y recuperación de los datos, que permita que todos los sistemas que alimentan y explotan los mismos se entiendan.
- Una buena calidad de los datos que se consigue resolviendo problemas de calidad que pueden aparecer en cinco dimensiones (Relevancia, Unicidad, Completitud, Exactitud y Consistencia).
Esta parte, quizás la «menos sexy del mundo del Big Data«, resulta al final de todo quizás la que más condiciona el éxito de un proyecto. Las empresas deben tener conciencia sobre ello. Y es que en un mundo en el que las fuentes de datos pueden ser internas o externas, estructuradas o desestructuras, etc., ordenar y limpiar los datos es más importante que nunca. Para un canal HORECA, que tendrá datos de redes sociales, información en los CRM, información de los TPVs (transacciones comerciales pagadas vía tarjeta de crédito), datos georeferenciados por dispositivos móviles, etc., resulta fundamental.
En segundo lugar, ser capaces de transformar estos «datos bien preparados» en conocimiento. Es decir, poner los datos a trabajar para ayudar a tomar decisiones. Se trata de introducir la modelización estadística (previsión) y la matemática (optimización), que es lo que vemos en nuestro módulos M2.2. del Programa de Big Data y Business Intelligence.
Y para ello, creo que se deben ejecutar las transformaciones de datos en conocimiento en tres etapas:
- Diagnóstico y modelado de perfiles de clientes: resulta crítico conocer mejor al cliente, para que así podamos focalizar mejor el target, definir las estructuras comerciales, promociones, políticas de distribución, etc. Una lectura hacia lo que ha ocurrido en el pasado. En cada punto del canal HORECA, resultaría interesante disponer:
- Cómo es la gente que ahí compra
- Su nivel de ingresos
- Tipología del hogar dominante
- Tasa de desemploe
- Precio medio del m2 de la vivienda
- Dónde está la competencia
- Dónde se sitúan los puntos de venta
- etc.
- Del modelado del pasado, a la predicción del futuro: una vez que sabemos algo sobre los patrones de consumo, tendencias, etc., es hora de tratar de adelantarnos a la ocurrencia de los hechos. Aquí es cuando hablamos de un enfoque de futuro (el Business Analytics). De tal manera que podamos estimar el mercado potencial para una zona dada, preveer las ventas en cada área o en un canal de venta determinado. Aquí se trata de darle a una empresa:
- Modelos de propensión a la compra por zonas y puntos
- Modelos de propensión a la fuga de clientes por previsiones de abandono
- Localizar el potencial de cada target de mercado (densidad de cada zona)
- Estimar el lugar óptimo para la apertura de un nuevo emplazamiento sobre la base de la rentabilidad (considerando target, competencia y canibalizar otros puntos de venta propios)
- Entender lo que gasta y en qué gasta cada perfil de cliente
- Diseñar estrategias para el cross y up-selling
- Ajustar la distribución de productos
- Patrones de consumo georeferenciados (¿se consume más cerca del trabajo o del hogar? Las ofertas y mensajes publicitarios no debieran ser iguales)
- % de probabilidad de compra de un determinado producto por parte de un determinado perfil de cliente
- etc.
- De la predicción a la prescripción: esto es lo que buscan las empresas. Fijaros la cantidad de pasos previos que he descrito para llegar al punto por el cual las empresas van a pagar un proyecto de Big Data. Van a pagar por saber qué tienen que hacer para ganar más dinero, evitar perderlo u optimizar procesos. Es decir, van a pagar por que les prescribamos que deben hacer. Si nos ajustamos más al target de mercado, y tener una previsión de ventas por puntos y zonas, podremos ajustar mejor los mensajes y las estructuras comerciales, logrando así una mayor eficiencia en el uso de recursos, y por lo tanto, un mayor retorno sobre la inversión. Con las predicciones anteriores, podríamos prescribir a una empresa en relación a todas sus áreas funcionales, haciendo así un 360º a la empresa y su inteligencia:
- Distribución
- Abastecimiento
- Comercial
- Marketing
- Ventas
- Publicidad
- etc.
Como hemos venido señalando, el poder del Big Data es realmente enorme. En nuestras manos está sacar todo su potencial. Y es que al final, para una empresa del canal HORECA, un mayor conocimiento geográfico del cliente, concentrar esfuerzos donde hay potencial, incrementar la rentabilidad comercial resulta clave para su eficiencia económica y financiera.