Comentábamos en un artículo anterior, que fue allá por 2012 cuando se empieza a popularizar el término Big Data en el acervo popular. Pero eso no quiere decir, que sea entonces cuando podamos decir que comienza esta era del Big Data. De hecho, los orígenes son bastante anteriores.
Dos ingenieros de Google, Jeffrey Dean y Sanjay Ghemawat, allá por 2004, publican un artículo titulado «MapReduce: Simplified Data Processing on Large Clusters«.

Hablan de un nuevo modelo de programación que permite simplificar el procesamiento de grandes volúmenes de datos. Lo bautizan como MapReduce. Básicamente es la evolución natural y necesaria que tenían dentro de Google para procesar los grandes volúmenes de datos que ya por aquel entonces manejaban (documentos, referencias web, páginas, etc.). Lo necesitaban, porque a partir de toda esa información, sacaban una serie de métricas que luego les ayudó a popularizar industrias como el SEO y SEM. Vamos, de lo que hoy en día vive Google (Alphabet) y lo que le ha permitido ser la empresa de mayor valor bursátil del mundo.
La idea que subyace a este nuevo modelo de programación es el siguiente: ante la necesidad de procesar grandes volúmenes de datos, se puede montra un esquema en paralelo de computación que permita así distribuir el trabajo (el procesamiento de datos) entre diferentes máquinas (nodos dentro de una red) para que se pueda reducir el tiempo total de procesamiento. Es decir, una versión moderna del «divide y vencerás«, que hace que ese trabajo menor en paralelo, reduzca sustantivamente lo que de otra manera sería un único, pero GRAN trabajo.
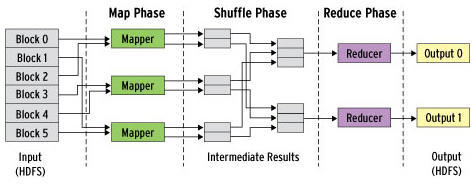
En aquel entonces, estos grandes «visionarios del Big Data» (luego volvemos a ello), se dieron cuenta que este problema que tenía Google en esos momentos, lo iban a tener otras cuantas aplicaciones. Así que decidieron desarrollar un modelo de programación que se desacoplara de las necesidades concretas de Google, y se pudiera generalizar a un conjunto de aplicaciones que pudieran luego reutilizarlo. Pensaron en un inicio a todos los problemas que pudiera tener el propio buscador. Pero se dan cuenta que quizás todavía hay un universo más amplio de problemas, por lo que se abtsrae y generaliza aún más.
De hecho, lo simplificaron tanto que dejaron la preocupación del programador en dos funciones:
- Map: transforma un conjunto de datos de partida en pares (clave, valor) a otro conjunto de datos intermedios también en pares (clave, valor). Un formato, que hará más eficiente su procesamiento y sobre todo, más fácil su «reconstruccón» futura.
- Reduce: recibe los valores intermedios procesados en formato de pares (clave, valor) para agruparlos y producir el resultado final.
Este paradigma lo adoptó Google allá por 2004. Y dado el rendimiento que tenía, se comenzó a emplear en otras aplicaciones (como decíamos ahora). Se comienzan luego a desarrollar versiones de código abierto en frameworks. Esto hace muy fácil su rápida adopción, y quizás deja una lección para la historia sobre cómo desarrollar rápidamente un paradigma.
Uno de los frameworks que comienza a ganar en popularidad es Apache Hadoop. Y, para muchos, aquí nace esta era del «Big Data». El creador del framework Hadoop se llama «Doug» Cutting, una persona con una visión espectacular. En cuanto leyó la publicación de Dean y Ghemawat se dio cuenta que si crease una herramienta bajo el paradigma MapReduce, ayudaría a muchos a procesar grandes cantidades de datos. Cutting acabó luego trabajando en Yahoo!, que es donde realmente empujó el proyecto Hadoop (qué vueltas da la vida…).
El ecosistema Hadoop consta de una serie de módulos como los que se pueden encontrar en la imagen debajo de estas líneas. Pero en su día, fueron dos sus principales componentes, y los que dan otro nuevo empuje a esta era del Big Data:
- HDFS: una implementación open-source de un sistema distribuido de ficheros (que ya había descrito Google en realidad).
- MapReduce: utilizando HDFS como soporte, la implementación del modelo de programación que hemos descrito al comienzo.

La historia sobre el origen y verdadero impulso a esta era del «Big Data», puede cerrarse con la salida de Yahoo! de Cutting en 2009. Se incorpora a Cloudera, empresa que comienza a dar servicio, soporte y formación de Hadoop a otras empresas. Para esa fecha, Hadoop ya era un ecosistema de módulos y aplicaciones, que merecen cada una un hilo aparte para entender las grandes aportaciones que hicieron las personas que hemos comentado en este artículo. Por cierto, mucha de esta historia la cuenta el propio Cutting en este hilo de Quora.
En definitiva, primero MapReduce, y luego el framework Hadoop, pueden ser considerados como el origen de esta era Big Data de la que tanto hablamos hoy en día. Y, las empresas de Internet (Google, Yahoo, hablaremos luego de Twitter, Facebook, Linkedin, etc.), las que propician la aparición de tecnologías de Big Data que luego son llevadas a otros sectores.
