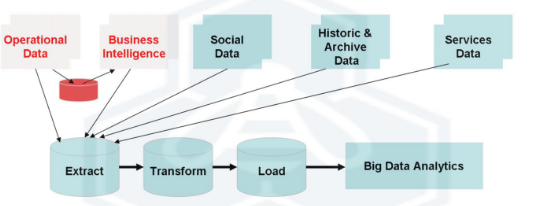
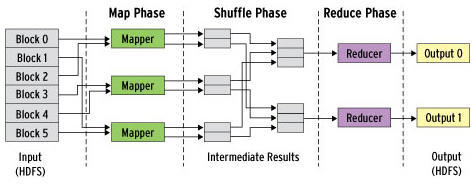
En un artículo anterior, hablábamos del nacimiento de esta era del Big Data. Y comentábamos, que el framework Hadoop había jugado en ello un papel fundamental. Desde entonces, su uso no ha dejado de crecer en el mundo empresarial.
El «mercado de Hadoop» está en pleno crecimiento. Hablamos de un mercado en el que las empresas, cogen el framework open source del que hablábamos, y desarrollan sus propias soluciones. Es una carrera entre tres principales «players»:
- MapR: valorada ya en más de 1.000 millones de dólares. Es noticia, porque ha conseguido más financiación aún.
- Cloudera: la empresa a la que se fue en 2009 «Doug» Cutting, el creador de Hadoop. En financiación, ha conseguido capital ya por 1.000 millones de dólares.
- Hortonworks: en bolsa desde 2014, y con una valoración bursátil actual de 435 millones de dólares.
Con estas cifras, además de entender el dinamismo del sector ahora mismo, se deja entrever que las valoraciones de las que estamos hablando de tecnologías Big Data, no son nada pequeños. Y si utilizamos estas cifras para aproximarnos a su verdadero valor, creo que podemos pensar que valor, existe.
Vamos a hablar de MapR, solo por la reciente noticia del aumento de su capital nuevamente. Y lo haremos como excusa para entender qué empresas están detrás de todo ello, y cuál es su base de clientes. Una tecnología de procesamiento de datos masivos que se asienta sobre el paradigma MapReduce, y que ofrece a las empresas la posibilidad de procesamiento Batch y Tiempo real (ya hablaremos de ello).

Ellos se autodefinen como plataforma de datos de convergencia, en el sentido que te permite hacer «de todo» con los datos con un mismo paquete de módulos tecnológicos. Una empresa que ha duplicado en el último trimestre su cartera de clientes, que ya incluyen a empresas del tamaño de American Express, Audi, Ericsson, NTT, Philips o el banco Mizuho. Su modelo de negocio se asienta sobre las licencias y los servicios de soporte. Representan un 90% de sus ingresos totales. Y esto es lo que exponen en su propia web:
MapR proporciona, en el marco del universo Hadoop, una plataforma unificada que dispone de funcionalidades de misión crítica, que permite realizar desarrollos de producción en tiempo real. MapR cuenta con cerca de 700 clientes de los sectores de finanzas, gobierno, salud, Internet, industria, medios, retail y telecomunicaciones. Amazon, Cisco, Google, Teradata y HP también forman parte del ecosistema de partners de MapR.
¿Y cuál es su propuesta de valor? Básicamente, sobreponerse a las restricciones que tiene la distribución estándar de Hadoop, pero bajo una licencia que sigue siendo Apache. En lugar del HDFS del que hablábamos, ofrece MapRFS para una gestión de datos más eficiente, confiable y fácil de usar. Por ello, suelen decir que está más orientada a la «producción empresarial» que las dos anteriores.
Además, su módulo de integración de datos es realmente eficiente, permitiendo a las organizaciones integrar y procesar datos «legacy» así como nuevos, procedentes de diferentes plataformas. Una vez hecho esto, igualmente proveen soluciones de analítica avanzada.
El procesamiento de datos en el mundo de las empresas está en tanta transformación, que todas estas empresas proveedoras de soluciones de procesamiento de grandes volúmenes de datos, seguirán registrando cifras récord. La tendencia así parece demostrarlo. Aquellas que más están cambiando (aquellas que más competitividad están consiguiendo), son clientes de MapR, Hortonworks o Cloudera. Por ello, nada hace pensar que esta tendencia va a cambiar.