Los datos son una fuente inagotable de inteligencia para aplicar en la gestión de servicios de una ciudad, mejorar esos servicios con IA significa optimizar su eficiencia. Nuestras ciudades pueden ser más inteligentes y nuestra eco-responsabilidad también. De todo esto y mucho más nos hablaron el martes 16 de febrero de 2020, Jorge Sanchez y Bill Rafferty de SAS
Archivo de la etiqueta: inteligencia artificial
Webinar Salud 4.0: Big Data como clave del éxito.
El 23 de septiembre de 2020, Begoña García-Zapirain nos hablo de un tema que más que nunca es actualidad, Salud 4.0: Big Data como clave del éxito
Webinar Soccer Analytics: el fútbol como nunca antes lo habías visto.
El Big Data llega a todos los ámbitos de la sociedad y el fútbol no podía ser menos. Vuelve la liga y vuelven los webinar Deusto Big Data.
Gonzalo Colsa, Ex-Futbolista Profesional y CEO-Cofundador de Sportteamers y Alex Rayon vicerrector de relaciones internacionales y director de Deusto Big Data, nos van a ayudar a ver el fútbol desde otra perspectiva.
Webinar Arquitectura Big Data en tiempos del Covid-19. No vamos a construir modelos, pero también mola.
El 7 de mayo de 2020, Ibon Bolaños nos contó como Hadoop no es un ecosistema cerrado y que son muchas las herramientas que pueden interactuar con el. Se hizo una breve exposición de como Hadoop se está quedando atrás en detrimento de Spark. Y por último, se dieron unas pinceladas de en qué momento puede ser interesante plantearse ir a la nube
Webinar Un acercamiento desde los datos al tratamiento de las noticias sobre el COVID-19 empleando metodologías Big Data»
El jueves 30 de abril, Carlos Correa, Carlos Arciniega y Javier Perez a través de este webinar nos presentaron el caso de uso que han desarrollado para el análisis de las noticias aparecidas en los medios digitales relativas al COVID19. Conocimos qué servicios se han utilizado para recoger las noticias, los métodos y modelos empleados para su análisis automático (limpieza, unificación de formatos, detección de entidades, asignación de sentimiento, legalización…) y finalmente el modelo, arquitectura y entorno necesarios para la visualización de resultados a través de PowerBI.
Webinar ¿Cómo funcionan las aplicaciones más sorprendentes de Inteligencia Artificial?.
El 28 de abril de 2020, Alfonso Mendela hizo repaso a las aplicaciones más sorprendentes de la inteligencia artificial, explicando de manera sencilla cómo se han entrenado las redes neuronales capaces de realizar tareas como generación de texto, imagen, detección de cáncer, segmentación, y más! ¿Cómo se entrena cada tipo de red? ¿Qué datos necesitamos? ¿ A qué resultados podemos aspirar? Aprenderemos que aplicando los mismos métodos sobre nuestros datos y utilizando nuestro conocimiento de dominio podemos crear nuevas aplicaciones que serán referentes en el futuro
El MIT creará una facultad de Inteligencia Artificial
Dos noticias de estos últimos días han llamado mi atención. Por un lado, hemos sabido que en el Instituto de Tecnología de California (Caltech) la asignatura con mayor número de estudiantes, a pesar de ser optativa, vuelve a ser Machine Learning. Los estudiantes provienen de 23 diferentes especializaciones (fiel a la tradición americana de elección de asignaturas a lo largo de la carrera de especialización). Aquí el tweet que lo cuenta:
It’s official: #MachineLearning course by Professor Yaser Abu-Mostafa is (again) the biggest class at @Caltech, undergraduate or graduate in all departments, in spite of being an elective offered every year. The students come from 23 different majors!#DataScience #AI #BigData
— Caltech Telecourse (@telecourse) October 19, 2018
Por otro lado, y de bastante más envergadura, el MIT anuncia que va a crear una nueva facultad para trabajar la Inteligencia Artificial (IA). Un total de 1.000 millones de dólares serán invertidos. Tiene sentido que sea el MIT nuevamente, que ya tuvo mucho que ver en el nacimiento de esta disciplina que trata de desarrollar métodos que aprendan del comportamiento de los datos para luego poder generalizar. Es ya la mayor inversión realizada hasta la fecha por una institución académica en el campo de la IA.

Como se puede leer en la noticia, el MIT está diseñando la facultad mezclando inteligencia artificial, machine learning (métodos de aprendizaje sobre datos) y la propia ciencia de datos. Pero, no se quedará ahí, dado que pretende mezclarlo con otras áreas de conocimiento. Me han resultado especialmente reveladoras las palabras pronunciadas por el Rector del MIT, Rafael Reif, al hacer el anuncio:
“Computing is no longer the domain of the experts alone,”
“It’s everywhere, and it needs to be understood and mastered by almost everyone.”
De nuevo, la misma idea expresada anteriormente: los datos están transformando el mundo y sus diferentes contextos, por lo que se vuelve necesario conocer las principales técnicas para poder hacer uso de la capacidad organizativa, transformadora y de soporte que traen los métodos de gestión basados en modelos analíticos. Como dice el Rector, no es un campo propio solo de la ingeniería o la informática, sino que empieza llegar a nuevos terrenos. La inteligencia artificial, con la llegada de los grandes volúmenes de datos, ha vuelto a escena para transformar el mundo.
Otro de los aspectos reseñables de este anuncio es que introducirán la ética en sus programas de estudio. Entender el potencial impacto que tienen estos modelos inteligentes sobre los diferentes planos de la sociedad es importante. Especialmente, para los que adquirirán esas capacidades de transformación. No solo en política, sino en salud, educación, servicios sociales, etc., puede tener un impacto donde la ética no quede bien parada si no queda explícitamente reflejada. Los humanos creamos la tecnología, por lo que debemos enseñar que a la hora de hacerlo, nuestros sesgos y prejuicios debemos dejarlos de lado y hacer tecnología neutra o bien compensada.
Esto último ha vuelto a salir a escena estos días con la noticia en la que conocíamos que el algoritmo que Amazon usaba para seleccionar a sus trabajadores y trabajadoras discriminaba a las mujeres. Tarde, pero Amazon ya ha prescindido de él. Este lamentable hecho), no pensemos que existe sólo contra las mujeres y en el contexto laboral. Se pueden dar en cualquier espacio que tenga esos sesgos en el mundo real, como bien explicaba este artículo de Bloomberg.
Hace unos meses escribí un artículo sobre los movimientos que se estaban dando en diferentes países para el diseño y la creación de Ministerios de Inteligencia Artificial. Vemos como otro de los agentes sociales más relevantes para entender las consecuencias de las máquinas inteligentes, las universidades, también se están moviendo. Es interesante seguir esta tendencia para saber hasta dónde podremos llegar. ¿Veremos estas tendencias pronto por Europa?
Como dije en ese artículo:
La intencionalidad del ser humano es inherente a lo que hacemos. Actuamos en base a incentivos y deseos. Disponer de tecnologías que permiten hacer de manera automatizada un razonamiento como sujetos morales (simulando a un humano), sin que esto esté de alguna manera regulado, al menos, genera dudas. Máxime, cuando las reglas que gobiernan esos razonamientos, no las conocemos.
¿Quién va a llevarse el beneficio que reportan nuestros datos?
(Artículo escrito por Olatz Arrieta, alumna de la promoción de 2017 en el Programa en Big Data y Business Intelligence en Bilbao)
La era del Big Data
A estas alturas creo que todas las personas que estamos en el mundo profesional moderno hemos oído hablar de Big Data, Internet de las cosas, Industria 4.0, Inteligencia Artificial, Machine learning, etc.
Mi reflexión nace de ahí, del hecho innegable de que en estos últimos…¿cuánto? ¿5, 10, 15, 20 años? la presencia de internet y lo digital en nuestras vidas ha crecido de manera exponencial, como un tsunami que de manera silenciosa ha barrido lo anterior y ha hecho que sin darnos cuenta, hoy no podamos imaginar la vida sin móvil, sin GPS, sin whatsapp, sin ordenador, sin internet, sin correo electrónico, sin google, sin wikipedia, sin youtube, sin Redes Sociales,…Basta mirar a nuestro alrededor para ver un escenario inimaginable hace pocos años.
Hasta aquí nada nuevo, reflexiones muy habituales. Pero yo quería centrarme en un aspecto muy concreto de esta revolución en la que estamos inmersos, yo quería poner encima de la pantalla ( 😉 ) el valor económico de los datos y los nuevos modelos de negocio que esto está trayendo y va a traer consigo, con nuevos servicios, agentes y roles, actualmente inexistentes, que deberán de ser claramente regulados, tanto a través de las leyes, como sobre todo, en las compraventas y contratos entre privados. Y para ello, es importante que vayamos pensando en ello.
La gran pregunta
¿De quién es la propiedad de un dato? ¿Quién tiene la capacidad de explotar y sacar rentabilidad de los datos, tanto directamente como vendiéndolos a terceros?
Es una pregunta compleja con implicaciones legales que cómo he dicho habrá que desarrollar, pero la realidad es que, hoy por hoy, el dato lo explota quien sabe cómo hacerlo y quién tiene la capacidad tecnológica y económica para hacerlo: léase los gigantes de internet, los grandes fabricantes tecnológicos, las operadoras de telecomunicaciones, la banca y aseguradoras, grandes distribuidores, fabricantes de automóviles, etc., entre otros. Aparte está el sector público que se supone que va a actuar en este proceso, de manera neutral, velando por la privacidad de los datos y compartiendo todo lo publicable a través del open-data para la libre explotación por parte del sector privado.
Volvamos al valor del dato. Hace unos meses veía en youtube una entrevista a un Socio de Accenture que contaba, hablando sobre el bigdata, que en una comida que había tenido días antes con un Consejero de una Aseguradora, este Socio le había transmitido su sorpresa por la reciente compra de un hospital por parte de la aseguradora, ya que solo veía pérdidas y activos obsoletos…..…..a lo que el Consejero le contestó: “Ya lo sabemos, pero su valor es un intangible…estamos pagando por la información de sus pacientes”. Dichos datos iban a poder tener un doble (al menos) valor para la aseguradora, el primero, la explotación directa de los datos a través de algoritmos de machine learning que le permitirían el ajuste de los perfiles de riesgo de sus clientes y otro para comercializarlos y vendérselos, por ejemplo, a una farmacéutica.
Esto es un pequeño ejemplo de lo que ya está pasando, y no sólo en EEUU donde parece que estos temas van muy por delante, sino en nuestro entorno más cercano, donde las grandes empresas del tipo que he comentado, están comprando y vendiendo datos de clientes y usuarios.
Podríamos hablar también del caso clarísimo de las operadoras de móvil o de la banca que disponen del detalle de toda la vida de sus clientes, dónde van, con quién hablan, en qué y dónde gastan,..
Esto no es una crítica ni una denuncia porque realmente no están haciendo nada ilegal ni falto de ética, sino simplemente invertir mucho y ganar todo el dinero que pueden. Seguro que están respetando los datos personales, que sí están regulados por la LOPD, pero sí es verdad que todo esto está ocurriendo gracias a la falta de cultura digital y de conciencia del valor del dato de los usuarios-ciudadanos, que no dudamos en aceptar/firmar, sin mirar, los acuerdos de uso que nos ponen delante, con tal de poder utilizar esos servicios digitales que se han convertido en “imprescindibles” para nosotros.
Yendo al caso concreto del sector del automóvil. Hace poco leía la biografía de Elon Musk, fundador de TESLA, entre otras empresas, que es uno de los fabricantes de coches eléctricos más innovadores y digitalizados. En el libro contaba como dotan a sus coches de un complejo sistema de sensorización conectado a su central, con el que monitorizan el desempeño de cada elemento del coche así como el uso del mismo, ofreciendo a sus clientes un servicio de anticipación de necesidades y prevención de incidencias, totalmente transparente para los clientes, que pueden llegar a encontrarse, por ejemplo, como se les presenta a las 9 de la mañana en casa un técnico de TESLA para entregarles un coche de sustitución porque van arreglar el sistema de aire acondicionado que estaba empezando a desajustarse, cuando el usuario no había siquiera notado nada, o que al arrancar el coche por la mañana se les muestra en la pantalla del coche, ofertas de un supermercado al que suelen ir o de una hamburguesería que está camino al trabajo….todo esto está ocurriendo ya.
se les presenta a las 9 de la mañana en casa un técnico de TESLA para entregarles un coche de sustitución porque van arreglar el sistema de aire acondicionado que estaba empezando a desajustarse, cuando el usuario no había siquiera notado nada
Hablando de industria 4.0…., ¿podría un fabricante de maquinaria industrial ofrecer a sus clientes su producto ya sensorizado, de manera que pueda monitorizar y explotar centralizadamente los datos de funcionamiento de todas las máquinas instaladas en distintos clientes con el consiguiente incremento de la información sobre su uso que eso supone, y ofrecer directamente, o a través de una tercera empresa a la que venda esa información, servicios de mantenimiento preventivo personalizado u optimización de consumos energéticos a sus clientes? ….Todo esto y mucho más se puede hacer y se hará (si no se está haciendo ya..).
Y vuelvo al asunto que planteaba, ¿de quién es la información registrada sobre los hábitos de vida/fabricación de esos clientes?¿del fabricante que ha instalado los sensores y elementos de comunicación en el coche/máquina que permiten el registro, digitalización, transporte y explotación de los datos, o…. del cliente que es quién genera realmente el contenido?¿Podría un cliente negarse a facilitar esos datos, parece que sí, pero mejor aún, ¿podría un cliente quedarse con una parte de los beneficios que, por ejemplo, TESLA pueda estar obteniendo de la venta de sus datos a los comercios de la zona para que hagan sus ofertas o el fabricante de maquinaria pueda estar obteniendo de la venta de datos a terceros para que ofrezcan servicios de mantenimiento u optimización?
¿Podrán existir intermediarios de datos que nos gestionen y rentabilicen la información que generamos, de manera similar a como hacen los gestores de banca con nuestro dinero?
Se avecina un terreno de juego nuevo, con nuevas reglas por construir y con un enorme potencial de negocio para quienes sean capaces de entender antes sus posibilidades y desarrollar nuevos modelos de explotación y servicio, y tanto las personas como las empresas debemos, al menos, empezar a ser conscientes de nuestro valor y papel en todo esto.

Guía para comenzar con algoritmos de Machine Learning
El interés por el concepto de «machine learning» no para de crecer. Como siempre, una buena manera de saberlo, es utilizando herramientas de agregación de intereses como son Google Trends (las tendencias de búsquedas en Google) y Google N Gram Viewer (que indexa libros que tiene Google escaneados y sus términos gramaticales). Las siguientes dos imágenes hablan por sí solas:
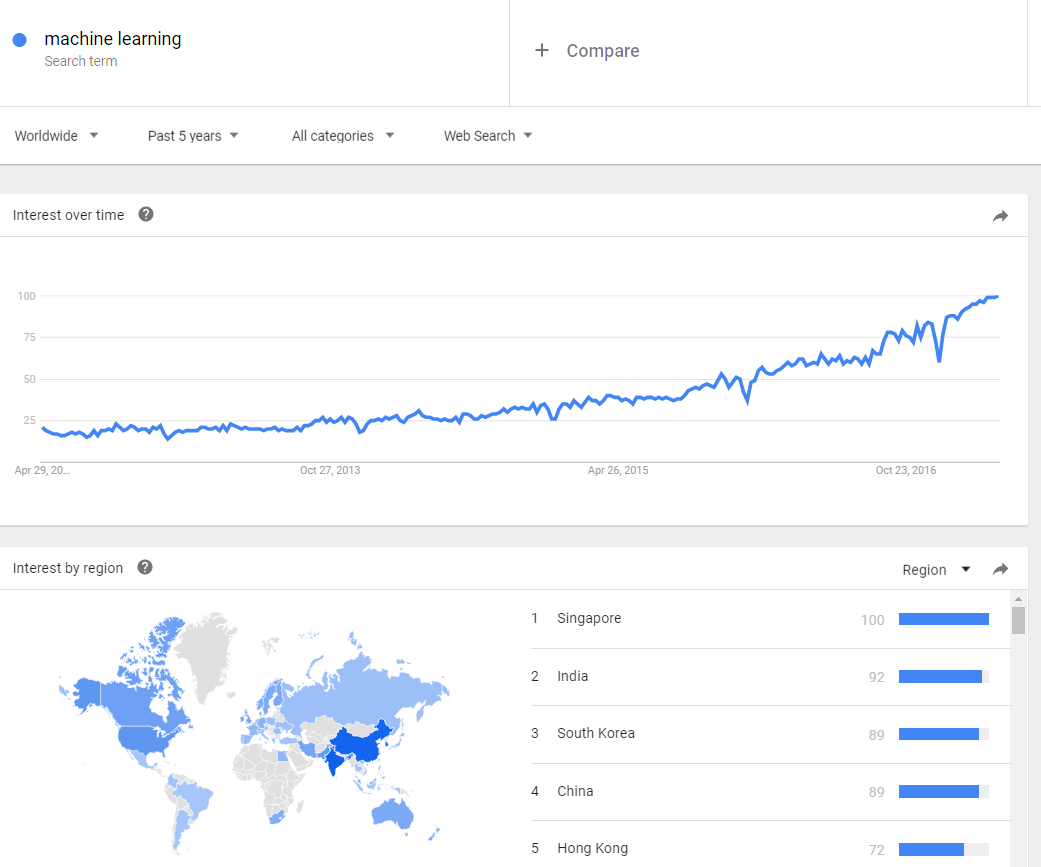
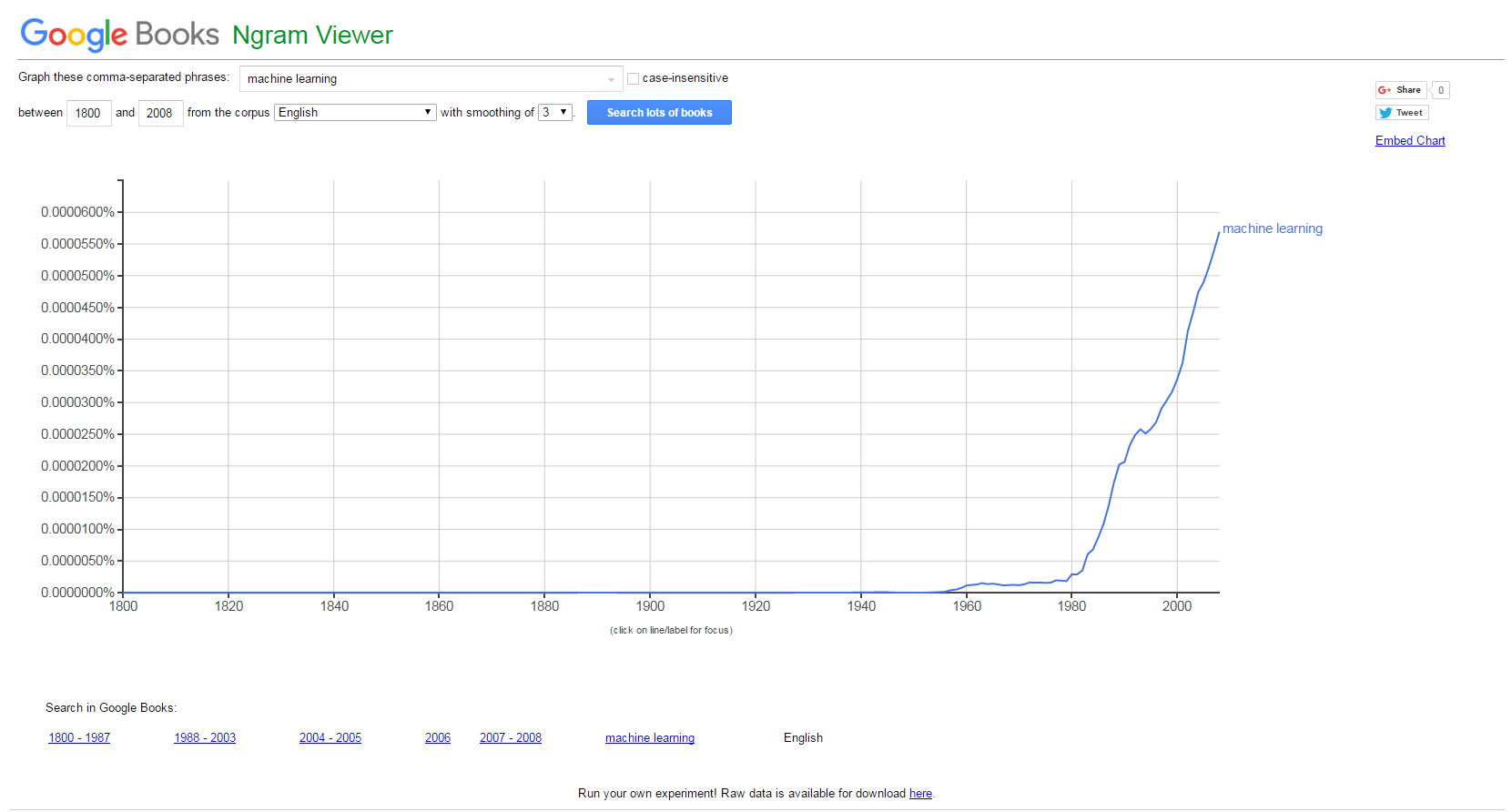
Sin embargo, no se trata de un término nuevo que hayamos introducido en esta era del Big Data. Lo que sí ha ocurrido es el «boom de los datos» (derivado de la digitalización de gran parte de las cosas que hacemos y nos rodean) y el abaratamiento de su almacenamiento y procesamiento (básicamente, los ordenadores y sus procesadores cuestan mucho menos que antes). Vamos, dos de los vectores que describen esta era que hemos bautizado como «Big Data».
Los algoritmos de machine learning están viviendo un renacimiento gracias a esta mayor disponibilidad de datos y cómputo. Estos dos elementos permiten que estos algoritmos aprendan conceptos por sí solos, sin tener que ser programados. Es decir, se trata de ese conjunto de reglas abstractas que por sí solas son construidas, lo que ha traído y permitido que se «autonconfiguren».
La utilidad que tienen estos algoritmos es bastante importante para las organizaciones, dado que son especialmente buenos para adelantarnos a lo que pueda ocurrir. Es decir, que son bastante buenos para predecir, que es como sabéis, una de las grandes «inquietudes» del momento. Se pueden utilizar estos algoritmos de ML para otras cuestiones, pero su interés máximo radica en la parte predictiva.
Este tipo de problemas, los podemos clasificar en dos grandes categorías:
- Problemas de regresión: la variable que queremos predecir es numérica (las ventas de una empresa a partir de los precios a fijar)
- Problemas de clasificación: cuando la variable a predecir es un conjunto de estados discretos o categóricos. Pueden ser:
- Binaria: {Sí, No}, {Azul, Rojo}, {Fuga, No Fuga}, etc.
- Múltiple: Comprará {Producto1, Producto2…}, etc.
- Ordenada: Riesgo {Bajo, Medio, Alto}, ec.
Estas dos categorías nos permiten caracterizar el tipo de problema a afrontar. Y en cuanto a soluciones, los algoritmos de machine learning, se pueden agrupar en tres grupos:
- Modelos lineales: trata de encontrar una línea que se «ajuste» bien a la nube de puntos que se disponen. Aquí destacan desde modelos muy conocidos y usados como la regresión lineal (también conocida como la regresión de mínimos cuadrados), la logística (adaptación de la lineal a problemas de clasificación -cuando son variables discretas o categóricas-). Estos dos modelos tienen tienen el problema del «overfit»: esto es, que se ajustan «demasiado» a los datos disponibles, con el riesgo que esto tiene para nuevos datos que pudieran llegar. Al ser modelos relativamente simples, no ofrecen resultados muy buenos para comportamientos más complicados.
- Modelos de árbol: modelos precisos, estables y más sencillos de interpretar básicamente porque construyes unas reglas de decisión que se pueden representar como un árbol. A diferencia de los modelos lineales, pueden representar relaciones no lineales para resolver problemas. En estos modelos, destacan los árboles de decisión y los random forest (una media de árboles de decisión). Al ser más precisos y elaborados, obviamente ganamos en capacidad predictiva, pero perdemos en rendimiento. Nada es gratis.
- Redes neuronales: las redes artificiales de neuronas tratan, en cierto modo, de replicar el comportamiento del cerebro, donde tenemos millones de neuronas que se interconectan en red para enviarse mensajes unas a otras. Esta réplica del funcionamiento del cerebro humano es uno de los «modelos de moda» por las habilidades cognitivas de razonamiento que adquieren. El reconocimiento de imágenes o vídeos, por ejemplo, es un mecanismo compleja que nada mejor que una red neuronal para hacer. El problema, como el cerebro humano, es que son/somos lentos de entrenar, y necesitan mucha capacidad de cómputo. Quizás sea de los modelos que más ha ganado con la «revolución de los datos»; tanto los datos como materia prima, como procesadores de entrenamiento, le vienen como anillo al dedo para las necesidades que tienen.
En el gran blog Dataconomy, han elaborado una chuleta que es realmente expresiva y sencilla para que podamos comenzar «desde cero» con algoritmos de machine learning. La tendremos bien a mano en nuestros Programas de Big Data en Deusto.

La carrera hacia la ventaja competitiva en la era del dato: plataformas de Inteligencia Artificial y la derrota de la intuición humana
Ya va a hacer un año de lo que muchos bautizaron como uno de los principales hitos de la historia de la Inteligencia Artificial. Un algoritmo de inteligencia artificial de Google, derrotaba a Lee Sedol, hasta entonces el campeón mundial y mayor experto del juego «Go». Un juego creado en China hace entre 2.000 y 3.000 años, y que goza de gran popularidad en el mundo oriental.

No era la primera vez que las principales empresas tecnológicas empleaban estos «juegos populares» para mostrar su fortaleza tecnológica y progreso. Todavía recuerdo en mi juventud, allá por 1997, ver en directo cómo Deep Blue de IBM derrotaba a mi ídolo Garry Kasparov. O como Watson, un sistema inteligente desarrollado también por IBM, se hizo popular cuando se presentó al concurso Jeopardy y ganó a los dos mejores concursantes de la historia del programa.
La metáfora de la «batalla» muchos la concebimos como la «batalla» del humano frente a la inteligencia artificial. La conclusión de la victoria de los robots parece clara: la inteligencia artificial podía ya con el instinto humano. Nuestra principal ventaja competitiva (esos procesos difícilmente modelizables y parametrizables como la creatividad, el instinto, la resolución de problemas con heurísticas improvisadas y subjetivas, etc.), se ponía en duda frente a las máquinas.
No solo desde entonces, sino ya tiempo atrás, las principales empresas tecnológicas, están corriendo en un entorno de competitividad donde disponer de plataformas de explotación de datos basadas en software de inteligencia artificial es lo que da competitividad a las empresas. Amazon, Google, IBM, Microsoft, etc., son solo algunas de las que están en esta carrera. Disponer de herramientas que permiten replicar ese funcionamiento del cerebro y comportamiento humano, ya hemos dicho en varias ocasiones, abre nuevos horizontes de creación de valor añadido.
¿Qué es una plataforma de inteligencia artificial? Básicamente un software que una empresa provee a terceras, que hace que éstas, dependan de la misma para su día a día. El sistema operativo que creó Microsoft (Windows) o el buscador que Alphabet creó en su día (Google), son dos ejemplos de plataformas. Imaginaros vuestro día a día sin sistema operativo o google (¿os lo imagináis?). ¿Será la inteligencia artificial la próxima frontera?
No somos pocos los que pensamos que así será. IBM ya dispone de Watson, que está tratando de divulgar y meter por todas las esquinas. Una estrategia bajo mi punto de vista bastante inteligente: cuanta más gente lo vea y use, más valor añadido podrá construir sobre la misma. Es importante llegar el primero.
Según IDC, para 2020, el despliegue masivo de soluciones de inteligencia artificial hará que los ingresos generados por estas plataformas pase de los 8.000 millones de dólares actuales a los más de 47.000 millones de dólares en 2020. Es decir, un crecimiento anual compuesto (CAGR), de más de un 55%. Estamos hablando de unas cifras que permiten vislumbrar la creación de una industria en sí mismo.
¿Y qué están haciendo las grandes tecnológicas? IBM, que como decíamos antes lleva ya tiempo en esto, creó en 2014, una división entera para explotar Watson. En 2015, Microsoft y Amazon han añadido capacidades de machine learning a sus plataformas Cloud respectivas. A sus clientes, que explotan esos servicios en la nube, les ayudan prediciendo hechos y comportamientos, lo que las aporta eficiencia en procesos. Un movimiento, bastante inteligente de valor añadido (siempre que se toque costes e ingresos que se perciben de manera directa, el despliegue y adopción de una tecnología será más sencillo). Google ha sacado en abierto (un movimiento de los suyos), TensorFlow, una librería de inteligencia artificial que pone a disposición de desarrolladores. Facebook, de momento usa todas las capacidades de análisis de grandes volúmenes de datos para sí mismo. Pero no será raro pensar que pronto hará algo para el exterior, a sabiendas que atesora uno de los mayores tesoros de datos (que esto no va solo de software, sino también de materias primas).
Según IDC, solo un 1% de las aplicaciones software del mundo disponen de características de inteligencia artificial. Por lo tanto, es bastante evidente pensar que su incorporación tiene mucho recorrido. En el informe que anteriormente decíamos, también vaticina que para ese 2020 el % de empresas que habrán incorporado soluciones de inteligencia artificial rondará el 50%.
Por todo ello, es razonable pensar que necesitaremos profesionales que sean capaces no solo de explotar datos gracias a los algoritmos de inteligencia artificial, sino también de crear valor sobre estos grandes conjuntos de datos. Nosotros, con nuestros Programas de Big Data, esperamos tener para rato. Esta carrera acaba de comenzar, y nosotros llevamos ya corriéndola un tiempo para estar bien entrenados. La intuición humana, no obstante, esperamos siga siendo difícilmente modelizable. Al menos, que podamos decirles a los algoritmos, qué deben hacer, sin perder su gobierno.
