Nada más hacerse público el caso de los Papeles de Panamá, escribimos un artículo en este blog para describir cómo el paradigma del Big Data (con sus método de trabajo del dato, sus tecnologías, su aproximación al dato, etc.) había jugado un papel fundamental para ser clave y posibilitar el procesamiento de la mayor filtración de la historia del periodismo (2.6 terabytes, y 11,5 millones de documentos -Wikileaks, para que se hagan a la idea, fueron 1,7 GB “solo”-).
Dado que hemos empezado ya nuestra actividad para el próximo lanzamiento en Otoño de nuestro Programa de Big Data y Business Intelligence en nuestra sede de Donostia – San Sebastián, quisimos organizar una jornada en la que pudiéramos contar con una de las principales protagonistas de dicha investigación. Mar Cabra, que ha desarrollado su carrera alrededor del periodismo de datos y la transparencia, y que ha formado parte del International Consortium of Investigative Journalists que ha estado detrás de la investigación sobre este escándalo social y moral.
Os dejo, lo primero, su presentación, que resumo a continuación:
La verdad es que Mar señaló muchos de los puntos críticos que trabajamos en nuestros Programas de Big Data y Business Intelligence:
- Tuvieron muchos problemas con la calidad de los datos. Estaban muy «sucios», y dedicaron gran cantidad del tiempo a ponerlos limpios y eficientes para su procesamiento.
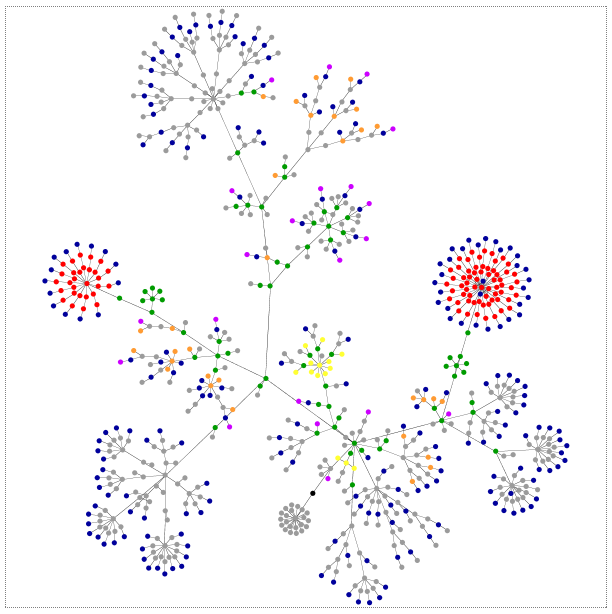
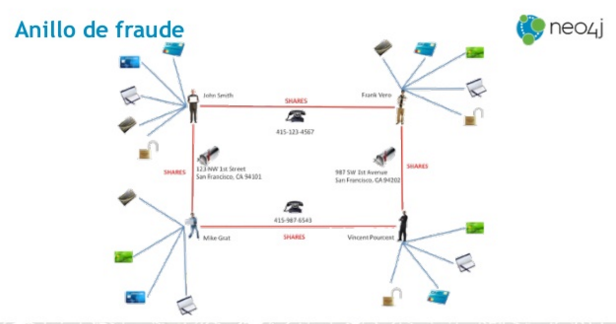
- Nos introdujo las tecnologías que han estado detrás de la investigación y cómo han jugado un papel totalmente determinante para que fuera un éxito el proyecto. En esta entrada ya detallamos todas las tecnologías, pero por resumir las más determinantes, Mar nos habló de Talend como ETL, NEO4J para almacenamiento y Linkurious para la representación visual. Su expresividad y las facilidades para el descubrimiento de conocimiento, fueron aspectos críticos.
- Entre los 11,5 millones de documentos de la filtración, prácticamente 5 millones eran emails, 3 millones formatos de bases de datos, 2.1 millones PDFs, 1.1 millones eran imágenes y el resto, otro tipo de documentos. Como vemos, el grado de no-estructuración de la información y los datos era tan alto, que la importancia de las tecnologías que facilitan el procesamiento de datos no estructurados, ha sido de vital importancia.
- Nos habló mucho sobre cómo la visualización resulta crítica para que la gente luego entienda el conocimiento hallado de una manera bastante resumida y ágil. En la visualización que han realizado en colaboración con The Guardian, destacó The Power Players, que podéis consultar aquí.
- No solo se trata de la mayor filtración de la historia del periodismo, sino también de la mayor colaboración de la historia del periodismo. La importancia que ha tenido el haber compartido datos dentro del marco de un consorcio, trabajando con una tecnología de red social abierta, ha sido crítica. Se han evitado los silos de datos, clave para que se pudieran compartir los documentos del despacho Mossack Fonseca.
- Las tecnologías de bases de datos de grafos les han permitido una navegación por la información tan eficiente, que han sido capaces de procesar en meses lo que de otra manera les hubiera llevado años. De esto ya hablamos en una entrada anterior. Ella lo llamó «magia» destacando lo siguiente (literal):
- Hago clicks en “puntos” y encuentro historias!
- Descubro nuevos nombres con las búsquedas fuzzy
- Encuentra el camino más corto (shortest path)
- Si a alguien le interesa, y quiere adentrarse en la base de datos de grafos generada y estructurada para modelizar los Papeles de Panamá, puede acceder aquí. Un ejercicio de transparencia y colaboración al que Mar no paraba de invitarnos.
Para terminar, os dejo los vídeos de su intervención completa, así como la entrevista que la hicimos (que resume los puntos comentados anteriormente). Un caso, como ven, el de los Papeles de Panamá, en el que el Big Data ha aportado a la sociedad mucho.