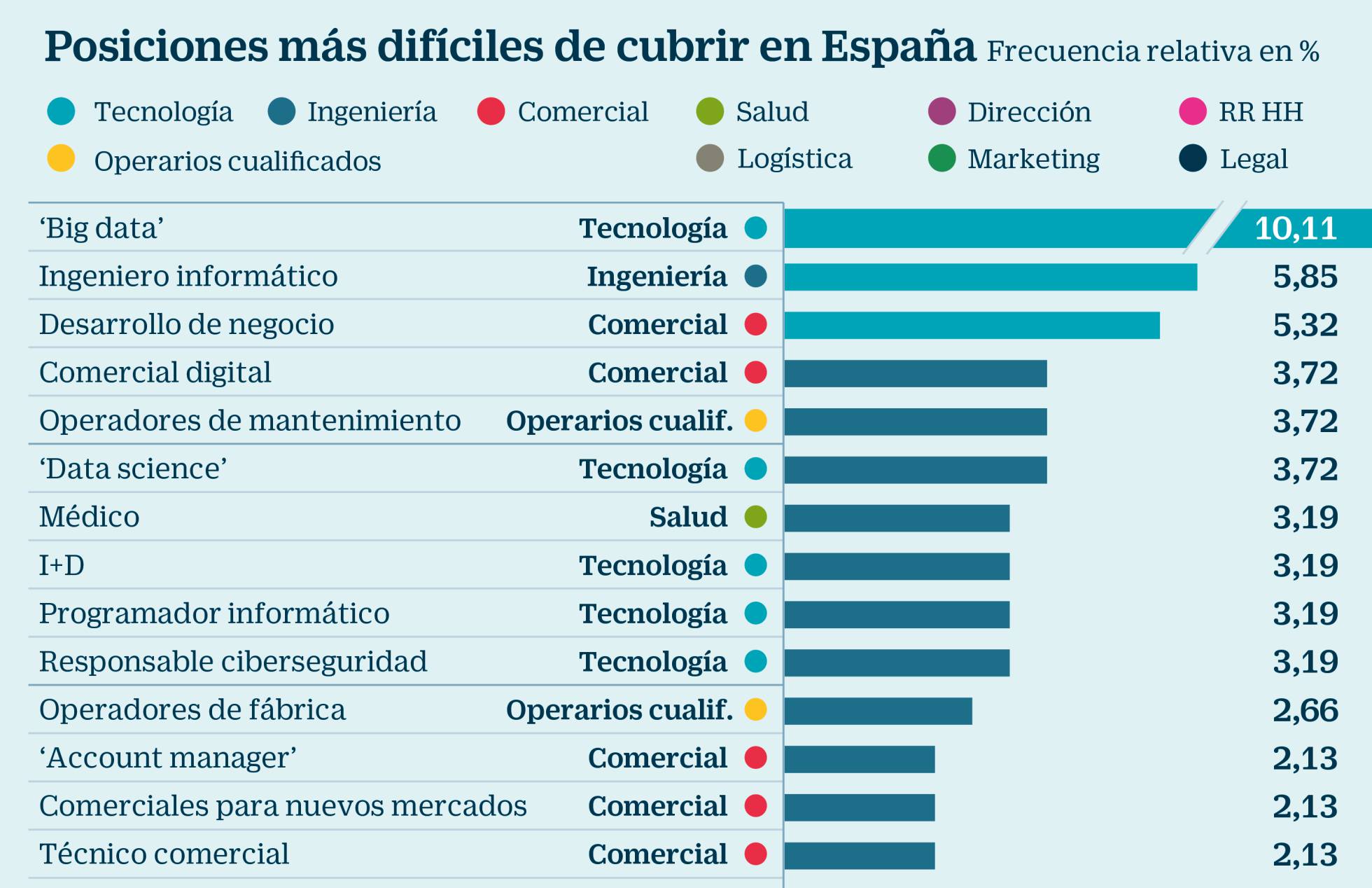
El pasado 7 de marzo, Cinco Días, publicaba esta noticia: «Big data, el perfil más difícil de cubrir en España«. Según el artículo y sus fuentes, las profesiones asociadas con las tecnologías de Big Data son las más difíciles de cubrir. Su fuente principal es el informe EPYCE 2017: Posiciones y Competencias más demandadas, elaborado por EAE Business School junto con la Asociación Española de Directores de Recursos Humanos (AEDRH), la CEOE, el Foro Inserta de la Fundación Once y Human Age Institute.
En un blog como éste, donde hablamos tanto del paradigma del Big Data y sus múltiples implicaciones en nuestras sociedades, naturalmente, no podíamos dejar sin sacar esta noticia. Llevamos años ya formando perfiles de Big Data en nuestros Programas de Big Data en Bilbao, Donostia y Madrid.
El informe original contiene aún más información. Aspecto que recomiendo revisar, para que se entienda bien no solo la metodología, sino los contenidos (datos) analizados. Miren por ejemplo esta gráfico que adjunto:
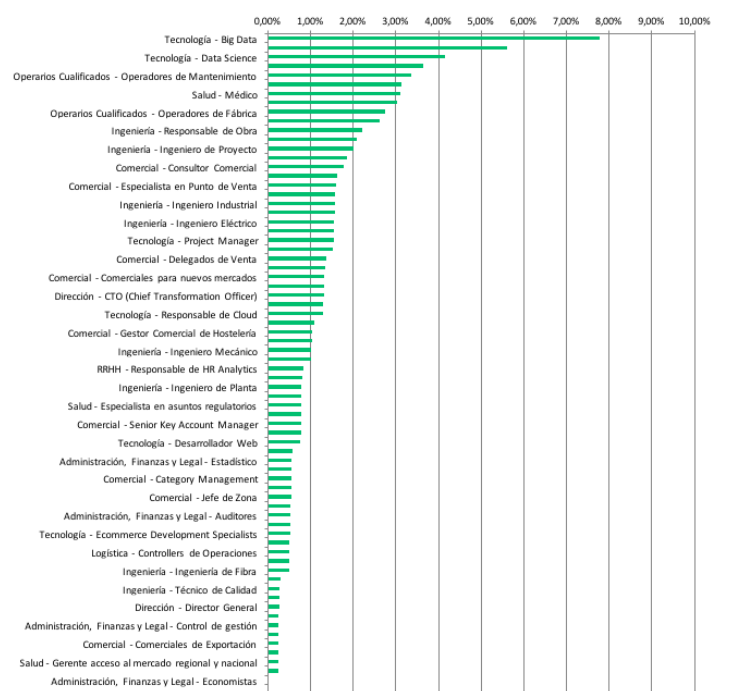
Con un nivel de detalle mayor, lo que vemos es que no solo la parte tecnológica (que siempre está en el top de los ranking de bajo desempleo), sino también la ciencia de datos (que son nuestras dos patas fundamentales en nuestros programas), son las más demandadas. En general, hay numerosas profesiones técnicas demandadas en todo el ranking y el informe. Lo cual nos viene a confirmar que efectivamente estamos viviendo una transformación tecnológica y digital en múltiples planos.
Lo que parece que viene a confirmar este informe es que estamos viviendo cierta brecha entre los perfiles que demandan las empresas y lo que realmente se dispone luego en el mercado de trabajo. Parece real esa velocidad a la que se está efectuando esta transformación digital de la sociedad, que está provocando que muchos perfiles no puedan seguirla, y no les dé tiempo a actualizar sus competencias y habilidades. El Big Data, la revolución de los datos, parece que ha venido para quedarse.
No obstante, en relación a todo esto, creo que cabría introducir tres elementos de reflexión. A buen seguro, a cualquier lector o lectora de estas estadísticas, le interesará conocer qué hay más allá de estas gráficas. Básicamente, porque la gestión de expectativas laborales en los programas formativos, creo que debe caracterizarse por la honestidad, para que luego no produzca frustraciones. Estos tres puntos son: (1) Descripción de «supermanes» y «superwomanes» en los puestos de trabajo de las empresas; (2) el concepto «experiencia» en las organizaciones; (3) el talento cuesta dinero.
En relación al (1), darse una vuelta por Linkedin suele ser muy ilustrativo a estos efectos. Las empresas, cuando buscan perfiles «de Big Data» (así en genérico y abstracto), suelen hacerlo solicitando muchas habilidades y competencias que me parece difícil que lo cubra una misma persona: conocimientos de programación (R, Python, Java, etc.), conocimiento de los frameworks de procesamiento de grandes volúmenes de datos y sus componentes (Spark y Hadoop, y ya de paso Storm, Hive, Sqoop, etc.), que sepa administrar un clúster Hadoop, que sepa cómo diseñar una arquitectura de Big Data eficiente y óptima, etc. Una persona que en definitiva, dé soporte a todo el proceso de un proyecto de Big Data, desde el inicio hasta el final. Este enfoque es bastante complicado de cubrir: para una persona manejar todo eso es realmente complicado, dado que no solo los códigos de pensamiento, sino también las habilidades, no suelen estar relacionadas.
En cuanto al (2), que se pida para estos puestos experiencia, me parece un poco temeroso. Estamos hablando de un paradigma que irrumpe con fuerza en 2013. Por lo que estar pidiendo experiencias de más de 2-3-4 años, es literalmente imposible de cubrir. Y menos en España donde todavía no hay tantas realidades en proyectos de Big Data como se cree. ¿Quizás la falta de cobertura de vacantes tenga que ver precisamente con esta situación? Por ello sería bueno saber realmente qué es lo que no están encontrando: ¿el puesto necesario? ¿el puesto definido por las empresas? ¿las expectativas mal gestionadas? Quizás sería bueno, y los empleadores bien saben que siempre les digo, que la formación es un buen mecanismo para poder prescindir de este factor de experiencia. Ahora mismo estamos colaborando con importantes empresas y organizaciones que están formando a varios perfiles a la vez porque son conocedores del límite de la experiencia del que hablamos.
Por último, en cuanto al (3). Hay una expresión inglesa que me gusta rescatar cuando hablo de esto: «You get what you pay«. Una expresión muy común también últimamente en el sector tecnológico. No podemos pretender pagar salarios bajos y que luego tengamos esos supermanes y superwomanes que decía anteriormente. Tenemos que ser coherente con ello. Nuestro conocimiento tecnológico, el talento técnico que formamos en España, está muy bien valorado en muchos lugares de Europa (Dublin, Londres, Berlín, etc.) y el mundo (San Francisco, New York, Boston, etc.). Es normal que en muchas ocasiones este talento se quiera ir al extranjero. ¿Pudiera estar aquí también parte de la explicación de la dificultad para cubrir puestos?