Retomamos la actividad tras el verano iniciando mi tercer (y penúltimo) módulo del curso anual “Programa de Big Data y Business Intelligence” de la Universidad de Deusto. En esta primera sesión, de un breve repaso de conceptos clave de estadística quiero destacar una frase, que “cojo prestada” de la presentación de nuestro profesor Enrique Onieva, que me ha encantado porque es absolutamente cierta:
“Unos datos convenientemente torturados te dirán todo aquello que desees oír”
El arte de “torturar” datos lo manejan con maestría muchas profesiones como por ejemplo los periodistas, que encuentran soporte a los titulares que convenga publicar, o también por ejemplo (debo de reconocerlo), nosotros los consultores, en algunos informes de diagnóstico o selección. Porque es cierto que siempre encuentras en un conjunto de datos un punto de vista de análisis que refuerza tus argumentos, y a la contra lo mismo.
Por eso, en este mundo del Business Intelligence es tan crucial:
Tener claras las preguntas a responder, los objetivos perseguidos en el análisis de los datos, que a menudo requiere de una secuencia de preguntas que van de lo más general a lo más particular y que habitualmente te van obligando a enriquecer tu información con más datos de los inicialmente disponibles.
Así por ejemplo, no es lo mismo preguntarse:
“Qué producto/servicio se vende más” <-> “Con qué producto/servicio ganamos más”
“Qué máquina tiene más incidencias/averías” <-> “Qué máquina tiene más incidencias/averías por unidad de producción”
“Qué clientes hemos perdido” <-> “Qué clientes hemos perdido por nº de reclamaciones/incidencias registradas”
Conocer muy bien los datos a analizar: sus circunstancias de obtención, fiabilidad del dato, significado y relevancia de cada campo/atributo disponible, etc.
Resumiendo:
CALIDAD DEL ANÁLISIS=
CALIDAD DEL DATO
+
CALIDAD DEL GESTOR
(Artículo escrito por nuestro profesor Pedro Gómez)
Como muchos ya sabréis, Deep Learning no es sino un conjunto de algoritmos de Machine Learning que se caracterizan por emplear modelos de redes neuronales con muchas capas para lograr el aprendizaje deseado.
Para que funcionen de manera correcta, requieren de muchos ejemplos o datos a partir de los cuales los algoritmos puedan llegar a aprender de manera automática. También requieren de una gran capacidad de computación, por lo que en los últimos años han ido ganando importancia gracias entre otras cosas a la potencia de las GPUs.
La diferencia principal con el resto de técnicas de Machine Learning es que mientras las técnicas tradicionales requieren procesar primero los datos generando características de los mismos antes de aprender, las técnicas de Deep Learning consiguen realizar el aprendizaje deseado sin ese paso previo.
Algunas aplicaciones comunes del Deep Learning son:
¿Qué pasaría si intentáramos que una red neuronal escribiera el guión de una película de ciencia ficción si la entrenamos con guiones de otras películas del género?
Por el lado del software, existen varios frameworks que nos permiten utilizar las técnicas de Deep Learning. Básicamente, cada proveedor de servicios en la nube ha creado su propio framework, como parte de su estrategia para competir por dichos servicios. Uno de los más conocidos es Tensorflow de Google: https://www.tensorflow.org/
Una de las ventajas de Tensorflow, es que tiene conexión con lenguajes de programación populares en el mundo del Machine Learning, como R y Python. En el caso del ejemplo que os voy a comentar, éste ha sido el framework que he utilizado.
Imaginemos que nos quisiéramos inventar nombres de personas nuevos en euskera. Para poder entrenar un modelo que pueda aprender un modelo de lenguaje, necesitamos ejemplos de nombres en euskera ya existentes. En este caso, he descargado la lista de nombres disponibles en Euskera separada por sexos:
Nombres de personas en euskera (Fuente: http://www.euskaltzaindia.eus/index.php?option=com_content&view=article&id=4161&Itemid=699&lang=es)
Disponemos en este caso de 1529 nombres de hombres y 1669 de mujeres. La verdad es que son pocos, y para hacer un experimento más serio sería conveniente disponer de más datos. Quizás alguien disponga de un listado más completo.
Podemos intentar generar un modelo de Deep Learning que modelice la probabilidad de observar un nombre en euskera como la probabilidad conjunta condicional de cada una de las letras anteriores que aparecen en dicho nombre. Para entrenar este modelo en este caso he optado por una arquitectura de red denominada RNN, Recurrent Neural Network.
¿Será el modelo capaz de inventar nombres nuevos en Euskera a partir de los ya existentes? Os adjunto un listado de algunos de los nombres nuevos que he obtenido, ¿os suenan a nombres en euskera? Os aseguro que no figuran en la lista oficial de Euskaltzaindia:
A pesar de su vida relativamente breve, el Big data está listo para optimizar la Industria 4.0. Algunas empresas están utilizando conjuntos de datos para mejorar y observar la producción, minimizar los errores de producción, gestionar los riesgos y optimizar la velocidad de montaje en la planta de producción. No sólo el Big Data puede ayudar a lograr una mayor eficiencia, sino que también puede conducir a un ahorro de costos en la línea de producción.
Mejoras en la cadena de suministros
A menudo se usa el Big Data para identificar, corregir y reducir los riesgos involucrados en la cadena de suministro. Procesos que incluyen la adquisición de materias primas, así como el almacenamiento y distribución de productos terminados presentan desafíos únicos que se pueden abordar a través del Big Data. Las cadenas de suministro más grandes y complejas serán más susceptibles que las estructuras más pequeñas, pero casi todas pueden beneficiarse de la gran recopilación y procesamiento de datos.
La cantidad de datos no es el único obstáculo a superar. Los fabricantes están ahora lidiando con más fuentes de datos y materiales que nunca. Los registros del centro de llamadas, el tráfico en línea, las reclamaciones de los clientes e incluso los mensajes en los medios sociales se utilizan para recopilar valiosos datos de los consumidores.
Aunque gran parte de esta información va actualmente a la cuneta, puede archivarse y utilizarse en el futuro para tomar decisiones de negocios, establecer objetivos organizacionales y mejorar el servicio al cliente.
Mejora en la comunicación
También se puede utilizar el Big Data para reforzar las comunicaciones entre los compañeros de trabajo, los consumidores e incluso sus máquinas de producción. Industrial Internet of Things (IIoT) ha generado una amplia red de dispositivos y equipos interconectados.
Tanto las materias primas como las piezas acabadas pueden ser etiquetadas con chips inteligentes RFID, que informan sobre su ubicación exacta y su estado físico en cualquier momento durante el proceso de producción o envío. Las máquinas de autodiagnóstico pueden evitar problemas adicionales y evitar lesiones personales mediante el apagado automático para mantenimiento o reparación. Todas estas características tienen el potencial de eficiencia y ahorro de costos que los primeros pioneros de la industria no habrían podido imaginar en sus mejores sueños.
Aumento de oportunidades de capacitación
Una de las aplicaciones más obvias y beneficiosas de la gestión del Big Data, se puede ver en la formación de su personal. Una gran cantidad de nuevos roles son necesarios para acomodar los proyectos Big Data.
Aparte de proporcionar más oportunidades para los empleados motivados, Big Data también se puede aprovechar para fortalecer y la eficacia de sus programas de formación actuales. Al recolectar y monitorizar los datos relacionados con el desempeño individual de los trabajadores, la productividad general, o la revisión del currículum cuando sea necesario. Esto le permite enfrentar mejor las debilidades y las refuerza con formación y entrenamiento. Los resultados pueden ser comparados y contrastados entre diferentes departamentos, competidores y la industria en general.
Los fabricantes que trabajan con Big Data, cosechan las mayores recompensas, mejoras en su cadena de suministro, comunicaciones más sólidas entre compañeros de trabajo y socios y obtienen más oportunidades de capacitación.
Esto es sólo el comienzo de lo que puede ofrecer el Big Data a la Industria 4.0.
Evolución de la industria hacia la 4.0: ¿qué aporta el Big Data?
The question lies at the heart of our campaign, which argues that government’s role should be to collect and administer high-quality raw data, but make it freely available to everyone to create innovative services». “Free our Data campaign”. Reino Unido. Junio de 2006.
¿La Seguridad Social será solvente para nuestros nietos? ¿Cuál es el impacto de las nuevas inversiones en salud, educación y carreteras? ¿Cuál será la proyección de las políticas en la Industria 4.0 de la C.A. de Euskadi? Estas son, algunas de las preguntas que se pueden resolver con Big Data.
El Big Data es una combinación de la información masiva de datos y los recursos tecnológicos. Al igual que las empresas, las administraciones públicas (AAPP) pueden conocer mucho más a los ciudadanos, lo que leen, lo que perciben, etc.
La combinación e implantación de políticas de Gobierno Abierto, “Big Data” y “Open Data” pueden brindar importantes y sustanciosos beneficios a los ciudadanos. Estudios como demosEuropa (2014) concluyen que los países que apuestan por la transparencia de sus administraciones públicas mediante normas de buen gobierno cuentan con instituciones más fuertes, que favorecen la cohesión social.
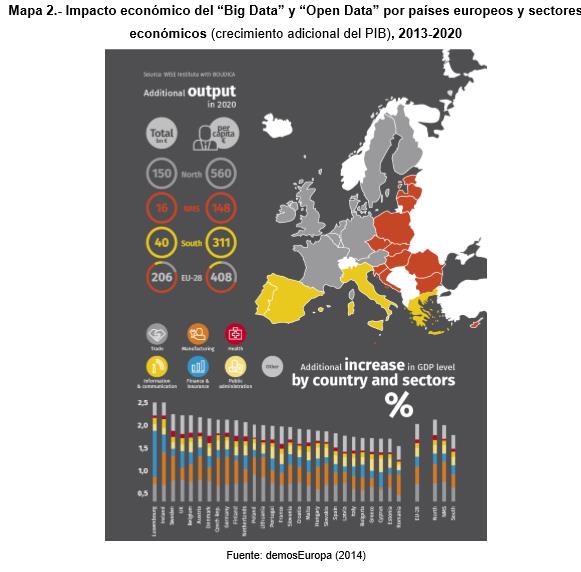
Según un estudio realizado en la Unión Europea la implementación de las políticas de Gobierno Abierto “Big Data” y “Open Data” tendrán un efecto considerable. El impacto dependerá, lógicamente, del grado de extensión y desarrollo de nuevas tecnologías en cada economía y sector productivo, así como del grado de dependencia y utilidad de dicha información en cada uno de ellos. De hecho, aunque se prevé un impacto positivo en todos los sectores económicos, las ramas de actividad sobre las que se espera un mayor impacto serán la industria manufacturera y el comercio, seguidas de las actividades inmobiliarias, el sistema sanitario y la administración pública (ver siguiente mapa).
Impacto económico Big Data y Open Data en la UE
En cuanto al impacto geográfico, conviene llamar la atención sobre el caso particular de España, ya que será uno de los países en los que menos repercusión económica tenga el “Big Data” y “Open Data”. Ello se debe al todavía limitado desarrollo de este tipo de tecnologías que permitan aflorar adecuadamente los beneficios que pueden llegar a reportar a la economía, así como de una mayor representatividad de las PYMES en el tejido empresarial español. Ahora bien, el hecho de que el impacto estimado del “Big Data” y “Open Data” sea mayor en los países del norte europeo, donde se han desarrollado mucho más estas tecnologías, pone de manifiesto que éstas ofrecen rendimientos crecientes que conviene aprovechar, independientemente del posicionamiento de cada uno de los países.
Impacto económico del Big Data y Open Data para países europeos y sectores económicos 2013-2020
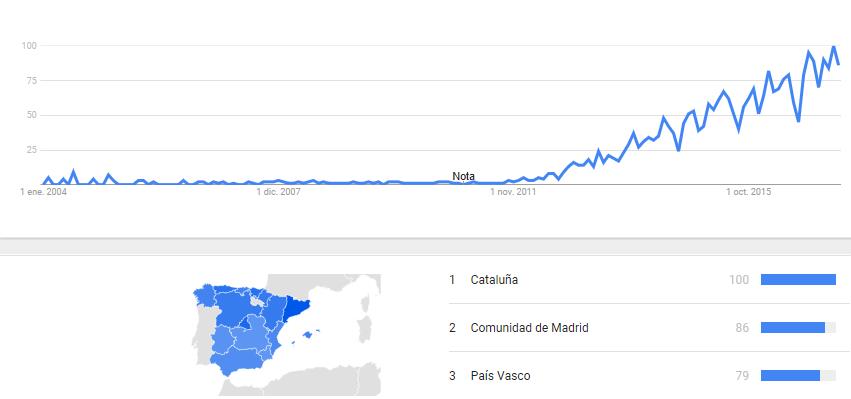
Aunque podemos percibir que la C.A. de Euskadi puede tener un comportamiento similar a las regiones del norte y centro de Europa visualizando el siguiente gráfico, dónde se refleja el interés de los ciudadanos por el Big Data.
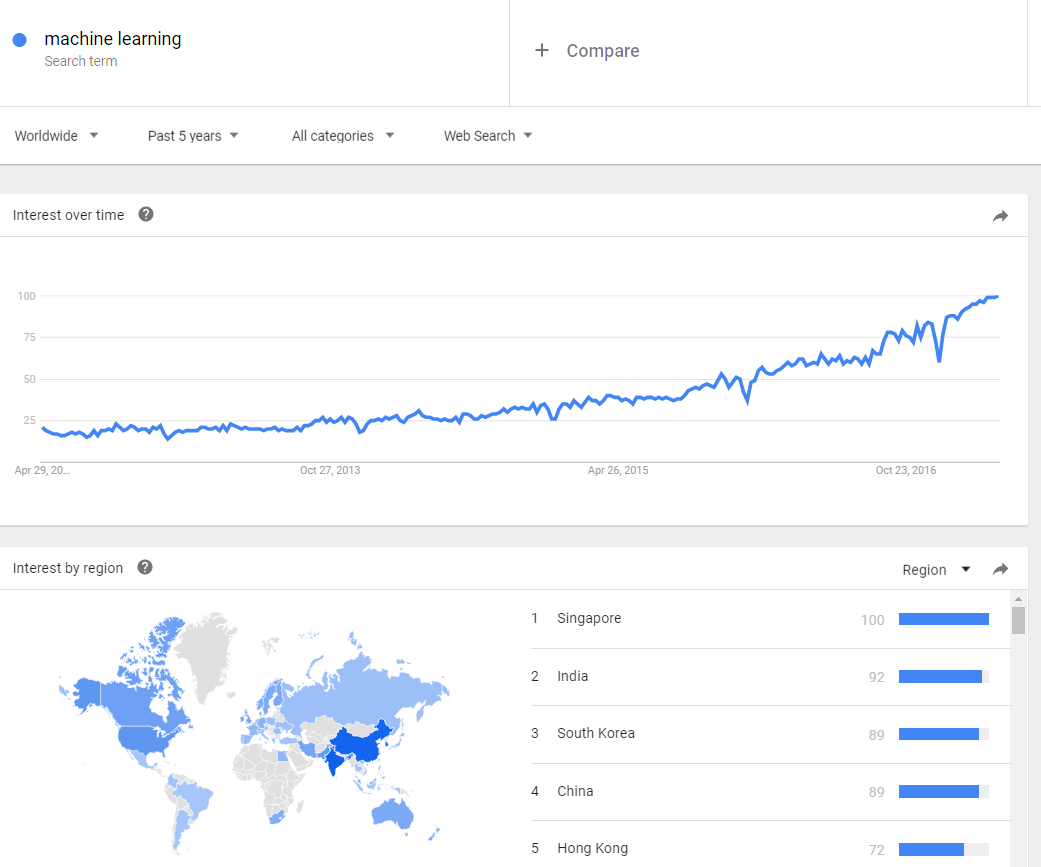
Fuente: Google. Los números reflejan el interés de búsqueda en relación con el mayor valor de un gráfico en una región y en un periodo determinados. Un valor de 100 indica la popularidad máxima de un término, mientras que 50 y 0 indican una popularidad que es la mitad o inferior al 1%, respectivamente, en relación al mayor valor.
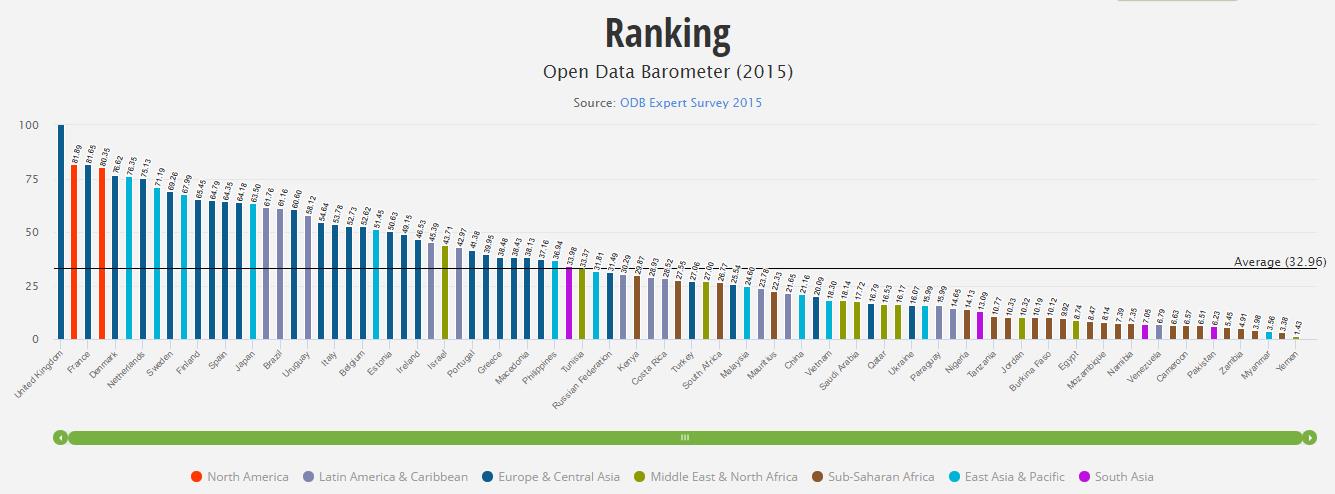
Un elevado número de países han planteado iniciativas de “Open Data”, con el objetivo de incentivar la actividad económica, favorecer la innovación y promover la rendición de cuentas por parte de las AA.PP. Estas iniciativas en absoluto se limitan a los países más avanzados, sino que se están aplicando en múltiples territorios como herramienta de desarrollo económico, como es el caso de India. No obstante, la formulación de buenas prácticas requiere una selección de los principales referentes a escala internacional. Para ello, es posible analizar estudios recientes como, por ejemplo, el Barómetro elaborado por la World Wide Web Foundation.
Open Data Barometer
Reino Unido es el país más avanzado en materia de “Open Government Data” (OGD), tanto en lo que se refiere a la adaptación de sus instituciones, ciudadanos y tejido empresarial, como en la implementación de iniciativas públicas y en el impacto conseguido por las mismas.
El Reino Unido es reconocido ejemplo como uno de los principales referentes a escala internacional en materia de Gobierno Abierto. Sus actividades en torno a la liberación de datos comenzaron en 2006, a instancias de diversas campañas impulsadas por la sociedad civil y los medios de comunicación (como “Free our Data”), y ha logrado mantener un claro apoyo a estas estrategias tanto por parte de los últimos Primeros Ministros como de los principales partidos políticos británicos.
Entre los objetivos de la estrategia de apertura de datos de Reino Unido destaca la importancia atribuida a la innovación y a la dinamización económica que estas iniciativas pueden favorecer. En este sentido, se ha creado un organismo no gubernamental, el Open Data Institute (de financiación público-privada), cuya misión específica es apoyar la creación de valor económico a partir de los datos puestos a disposición de ciudadanos y empresas. Asimismo, las distintas áreas de la Administración han recibido el mandato de diseñar estrategias propias de apertura de datos, incluyendo acciones específicas que incentiven el uso de sus datos y la realización de informes públicos periódicos sobre sus avances en este ámbito.
Por otra parte, el Reino Unido ha puesto en marcha soluciones que tratan de contribuir a resolver los problemas que surgen al publicar grandes volúmenes de datos correspondientes a áreas de actividad o responsabilidad muy diversa. En este sentido, cabe subrayar:
La creación de los Sector Transparency Boards en diversos departamentos de la Administración. Estos grupos de trabajo cuentan con la participación de representantes de la sociedad civil y de las empresas, y tienen como objetivo canalizar las solicitudes de datos y orientar al Gobierno sobre las prioridades a seguir para liberar nuevos conjuntos de datos.
El desarrollo de programas de formación, competiciones y eventos diseñados para incentivar el uso de datos públicos por parte de la sociedad civil.
La asignación de financiación pública a programas dirigidos a incrementar el aprovechamiento de los datos liberados por parte del tejido empresarial.
Asimismo, se observan esfuerzos dirigidos a incrementar la calidad, estandarización y facilidad de explotación de los datos distribuidos (como los derivados del servicio cartográfico, el registro catastral, el registro mercantil).
A estas alturas creo que todas las personas que estamos en el mundo profesional moderno hemos oído hablar de Big Data, Internet de las cosas, Industria 4.0, Inteligencia Artificial, Machine learning, etc.
Mi reflexión nace de ahí, del hecho innegable de que en estos últimos…¿cuánto? ¿5, 10, 15, 20 años? la presencia de internet y lo digital en nuestras vidas ha crecido de manera exponencial, como un tsunami que de manera silenciosa ha barrido lo anterior y ha hecho que sin darnos cuenta, hoy no podamos imaginar la vida sin móvil, sin GPS, sin whatsapp, sin ordenador, sin internet, sin correo electrónico, sin google, sin wikipedia, sin youtube, sin Redes Sociales,…Basta mirar a nuestro alrededor para ver un escenario inimaginable hace pocos años.
Hasta aquí nada nuevo, reflexiones muy habituales. Pero yo quería centrarme en un aspecto muy concreto de esta revolución en la que estamos inmersos, yo quería poner encima de la pantalla ( 😉 ) el valor económico de los datos y los nuevos modelos de negocio que esto está trayendo y va a traer consigo, con nuevos servicios, agentes y roles, actualmente inexistentes, que deberán de ser claramente regulados, tanto a través de las leyes, como sobre todo, en las compraventas y contratos entre privados. Y para ello, es importante que vayamos pensando en ello.
La gran pregunta
¿De quién es la propiedad de un dato? ¿Quién tiene la capacidad de explotar y sacar rentabilidad de los datos, tanto directamente como vendiéndolos a terceros?
Es una pregunta compleja con implicaciones legales que cómo he dicho habrá que desarrollar, pero la realidad es que, hoy por hoy, el dato lo explota quien sabe cómo hacerlo y quién tiene la capacidad tecnológica y económica para hacerlo: léase los gigantes de internet, los grandes fabricantes tecnológicos, las operadoras de telecomunicaciones, la banca y aseguradoras, grandes distribuidores, fabricantes de automóviles, etc., entre otros. Aparte está el sector público que se supone que va a actuar en este proceso, de manera neutral, velando por la privacidad de los datos y compartiendo todo lo publicable a través del open-data para la libre explotación por parte del sector privado.
Volvamos al valor del dato. Hace unos meses veía en youtube una entrevista a un Socio de Accenture que contaba, hablando sobre el bigdata, que en una comida que había tenido días antes con un Consejero de una Aseguradora, este Socio le había transmitido su sorpresa por la reciente compra de un hospital por parte de la aseguradora, ya que solo veía pérdidas y activos obsoletos…..…..a lo que el Consejero le contestó: “Ya lo sabemos, pero su valor es un intangible…estamos pagando por la información de sus pacientes”. Dichos datos iban a poder tener un doble (al menos) valor para la aseguradora, el primero, la explotación directa de los datos a través de algoritmos de machine learning que le permitirían el ajuste de los perfiles de riesgo de sus clientes y otro para comercializarlos y vendérselos, por ejemplo, a una farmacéutica.
Esto es un pequeño ejemplo de lo que ya está pasando, y no sólo en EEUU donde parece que estos temas van muy por delante, sino en nuestro entorno más cercano, donde las grandes empresas del tipo que he comentado, están comprando y vendiendo datos de clientes y usuarios.
Podríamos hablar también del caso clarísimo de las operadoras de móvil o de la banca que disponen del detalle de toda la vida de sus clientes, dónde van, con quién hablan, en qué y dónde gastan,..
Esto no es una crítica ni una denuncia porque realmente no están haciendo nada ilegal ni falto de ética, sino simplemente invertir mucho y ganar todo el dinero que pueden. Seguro que están respetando los datos personales, que sí están regulados por la LOPD, pero sí es verdad que todo esto está ocurriendo gracias a la falta de cultura digital y de conciencia del valor del dato de los usuarios-ciudadanos, que no dudamos en aceptar/firmar, sin mirar, los acuerdos de uso que nos ponen delante, con tal de poder utilizar esos servicios digitales que se han convertido en “imprescindibles” para nosotros.
Yendo al caso concreto del sector del automóvil. Hace poco leía la biografía de Elon Musk, fundador de TESLA, entre otras empresas, que es uno de los fabricantes de coches eléctricos más innovadores y digitalizados. En el libro contaba como dotan a sus coches de un complejo sistema de sensorización conectado a su central, con el que monitorizan el desempeño de cada elemento del coche así como el uso del mismo, ofreciendo a sus clientes un servicio de anticipación de necesidades y prevención de incidencias, totalmente transparente para los clientes, que pueden llegar a encontrarse, por ejemplo, como se les presenta a las 9 de la mañana en casa un técnico de TESLA para entregarles un coche de sustitución porque van arreglar el sistema de aire acondicionado que estaba empezando a desajustarse, cuando el usuario no había siquiera notado nada, o que al arrancar el coche por la mañana se les muestra en la pantalla del coche, ofertas de un supermercado al que suelen ir o de una hamburguesería que está camino al trabajo….todo esto está ocurriendo ya.
se les presenta a las 9 de la mañana en casa un técnico de TESLA para entregarles un coche de sustitución porque van arreglar el sistema de aire acondicionado que estaba empezando a desajustarse, cuando el usuario no había siquiera notado nada
Hablando de industria 4.0…., ¿podría un fabricante de maquinaria industrial ofrecer a sus clientes su producto ya sensorizado, de manera que pueda monitorizar y explotar centralizadamente los datos de funcionamiento de todas las máquinas instaladas en distintos clientes con el consiguiente incremento de la información sobre su uso que eso supone, y ofrecer directamente, o a través de una tercera empresa a la que venda esa información, servicios de mantenimiento preventivo personalizado u optimización de consumos energéticos a sus clientes? ….Todo esto y mucho más se puede hacer y se hará (si no se está haciendo ya..).
Y vuelvo al asunto que planteaba, ¿de quién es la información registrada sobre los hábitos de vida/fabricación de esos clientes?¿del fabricante que ha instalado los sensores y elementos de comunicación en el coche/máquina que permiten el registro, digitalización, transporte y explotación de los datos, o…. del cliente que es quién genera realmente el contenido?¿Podría un cliente negarse a facilitar esos datos, parece que sí, pero mejor aún, ¿podría un cliente quedarse con una parte de los beneficios que, por ejemplo, TESLA pueda estar obteniendo de la venta de sus datos a los comercios de la zona para que hagan sus ofertas o el fabricante de maquinaria pueda estar obteniendo de la venta de datos a terceros para que ofrezcan servicios de mantenimiento u optimización?
¿Podrán existir intermediarios de datos que nos gestionen y rentabilicen la información que generamos, de manera similar a como hacen los gestores de banca con nuestro dinero?
Se avecina un terreno de juego nuevo, con nuevas reglas por construir y con un enorme potencial de negocio para quienes sean capaces de entender antes sus posibilidades y desarrollar nuevos modelos de explotación y servicio, y tanto las personas como las empresas debemos, al menos, empezar a ser conscientes de nuestro valor y papel en todo esto.
Valor económico de los datos (Fuente: http://www.centrodeinnovacionbbva.com/sites/default/files/cibbva-el-valor-de-los-datos-para-el-consumidor.jpg)
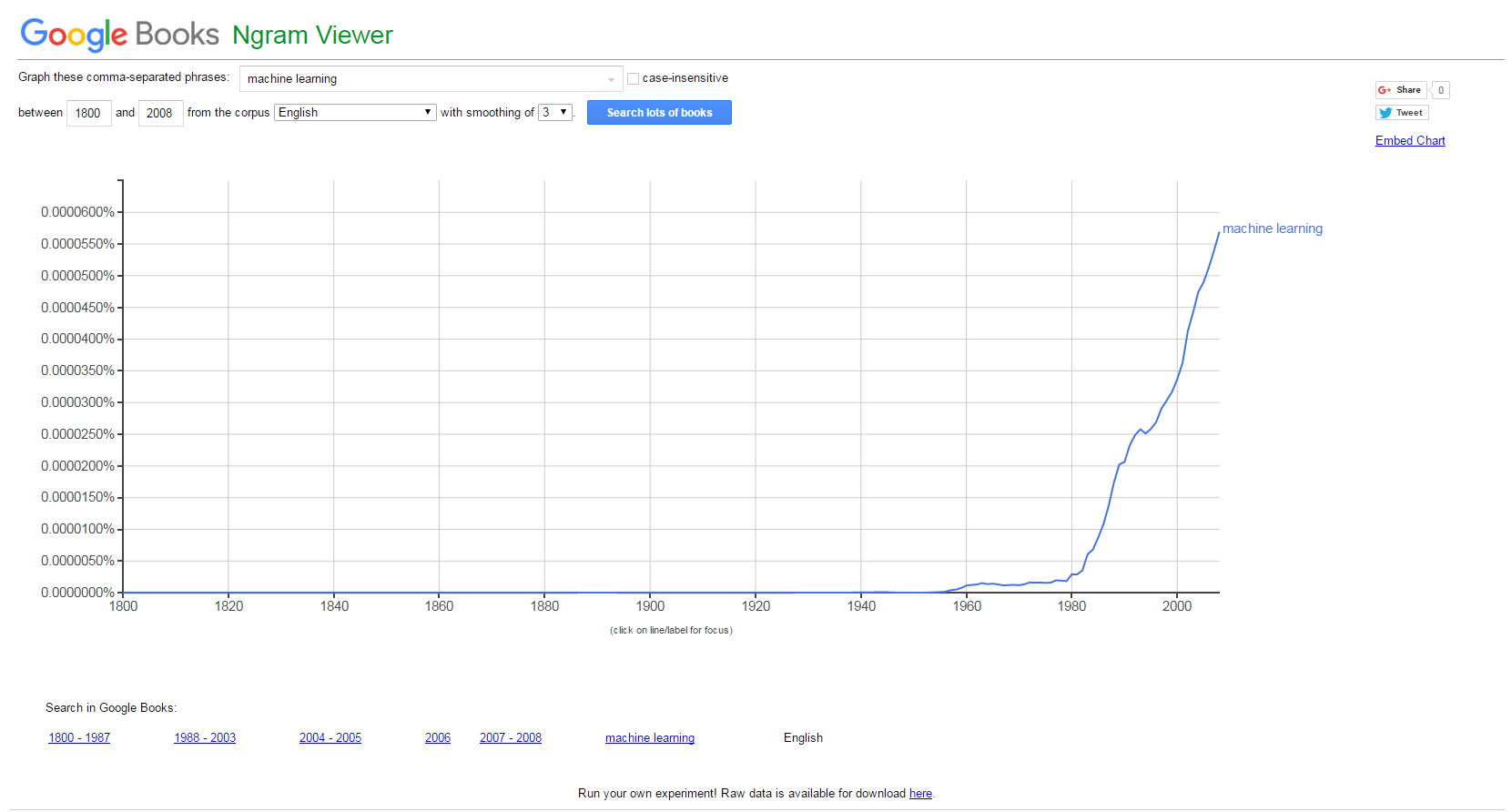
El interés por el concepto de «machine learning» no para de crecer. Como siempre, una buena manera de saberlo, es utilizando herramientas de agregación de intereses como son Google Trends (las tendencias de búsquedas en Google) y Google N Gram Viewer (que indexa libros que tiene Google escaneados y sus términos gramaticales). Las siguientes dos imágenes hablan por sí solas:
Búsqueda del término «machine learning» en Google (Fuente: Google Trends)El término «machine learning» en libros en el último siglo (Fuente: Google N Gram Viewer)
Sin embargo, no se trata de un término nuevo que hayamos introducido en esta era del Big Data. Lo que sí ha ocurrido es el «boom de los datos» (derivado de la digitalización de gran parte de las cosas que hacemos y nos rodean) y el abaratamiento de su almacenamiento y procesamiento (básicamente, los ordenadores y sus procesadores cuestan mucho menos que antes). Vamos, dos de los vectores que describen esta era que hemos bautizado como «Big Data».
Los algoritmos de machine learning están viviendo un renacimiento gracias a esta mayor disponibilidad de datos y cómputo. Estos dos elementos permiten que estos algoritmos aprendan conceptos por sí solos, sin tener que ser programados. Es decir, se trata de ese conjunto de reglas abstractas que por sí solas son construidas, lo que ha traído y permitido que se «autonconfiguren».
La utilidad que tienen estos algoritmos es bastante importante para las organizaciones, dado que son especialmente buenos para adelantarnos a lo que pueda ocurrir. Es decir, que son bastante buenos para predecir, que es como sabéis, una de las grandes «inquietudes» del momento. Se pueden utilizar estos algoritmos de ML para otras cuestiones, pero su interés máximo radica en la parte predictiva.
Este tipo de problemas, los podemos clasificar en dos grandes categorías:
Problemas de regresión: la variable que queremos predecir es numérica (las ventas de una empresa a partir de los precios a fijar)
Problemas de clasificación: cuando la variable a predecir es un conjunto de estados discretos o categóricos. Pueden ser:
Binaria: {Sí, No}, {Azul, Rojo}, {Fuga, No Fuga}, etc.
Múltiple: Comprará {Producto1, Producto2…}, etc.
Ordenada: Riesgo {Bajo, Medio, Alto}, ec.
Estas dos categorías nos permiten caracterizar el tipo de problema a afrontar. Y en cuanto a soluciones, los algoritmos de machine learning, se pueden agrupar en tres grupos:
Modelos lineales: trata de encontrar una línea que se «ajuste» bien a la nube de puntos que se disponen. Aquí destacan desde modelos muy conocidos y usados como la regresión lineal (también conocida como la regresión de mínimos cuadrados), la logística (adaptación de la lineal a problemas de clasificación -cuando son variables discretas o categóricas-). Estos dos modelos tienen tienen el problema del «overfit»: esto es, que se ajustan «demasiado» a los datos disponibles, con el riesgo que esto tiene para nuevos datos que pudieran llegar. Al ser modelos relativamente simples, no ofrecen resultados muy buenos para comportamientos más complicados.
Modelos de árbol: modelos precisos, estables y más sencillos de interpretar básicamente porque construyes unas reglas de decisión que se pueden representar como un árbol. A diferencia de los modelos lineales, pueden representar relaciones no lineales para resolver problemas. En estos modelos, destacan los árboles de decisión y los random forest (una media de árboles de decisión). Al ser más precisos y elaborados, obviamente ganamos en capacidad predictiva, pero perdemos en rendimiento. Nada es gratis.
Redes neuronales: las redes artificiales de neuronas tratan, en cierto modo, de replicar el comportamiento del cerebro, donde tenemos millones de neuronas que se interconectan en red para enviarse mensajes unas a otras. Esta réplica del funcionamiento del cerebro humano es uno de los «modelos de moda» por las habilidades cognitivas de razonamiento que adquieren. El reconocimiento de imágenes o vídeos, por ejemplo, es un mecanismo compleja que nada mejor que una red neuronal para hacer. El problema, como el cerebro humano, es que son/somos lentos de entrenar, y necesitan mucha capacidad de cómputo. Quizás sea de los modelos que más ha ganado con la «revolución de los datos»; tanto los datos como materia prima, como procesadores de entrenamiento, le vienen como anillo al dedo para las necesidades que tienen.
En el gran blog Dataconomy, han elaborado una chuleta que es realmente expresiva y sencilla para que podamos comenzar «desde cero» con algoritmos de machine learning. La tendremos bien a mano en nuestros Programas de Big Data en Deusto.
Guía para principiantes de algoritmos de Machine Learning (Fuente: dataconomy.com)
El pasado miércoles 5 de Abril, tuvimos la ceremonia de entrega de diplomas de la promoción de 2016 de nuestro Programa de Big Data y Business Intelligence en la sede de Bilbao. Un total de 58 alumnos, a los que queremos extender nuestra felicitación desde aquí también.
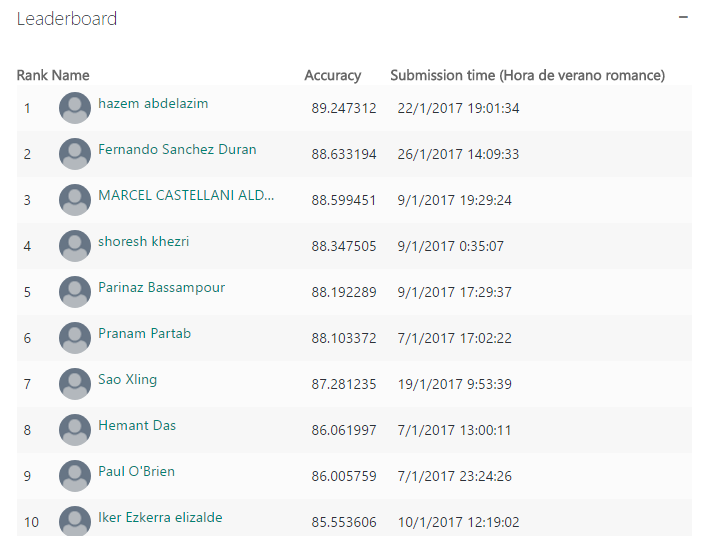
Pero quizás, una de las mejores noticias que pudimos recibir ese día es que uno de esos 58, Iker Ezkerra, Alumni de dicha promoción, nos comunicó que había quedado 10º clasificado en una competición de Big Data que había organizado Microsoft. Concretamente en esta:
Competición Microsoft modelo concesión crediticio
Una competición en la que el objetivo era desarrollar un modelo predictivo de eventuales impagos de clientes que solicitaban un préstamos hipotecario. Todo ello, utilizando tecnologías de Microsoft. Un reto interesante dado que la validación del modelo que cada participante desarrollaba, se realizaba con con 2 datasets que cada participante no conocía a priori. Se va escalando posiciones en el ranking en función del scoring que va obteniendo el modelo. ¿El resultado? El citado décimos puesto para Iker, además de obtener la certificación «Microsoft Professional Program Certificate in Data Science«.
Iker Ezkerra, décimo puesto competición Big Data Microsoft
Dentro de este proyecto, Iker tuvo que aprender un poco sobre la mecánica de concesión de créditos. Cuando solicitamos un préstamos hipotecario al banco, estas entidades financieras utilizan modelos estadísticos para determinar si el cliente va a ser capaz de hacer frente a los pagos o no. Las variables que influyen en esa capacidad de devolver el capital e intereses son muchos y complejos; ahí radica parte de la dificultad de esta competición, y donde Iker tuvo que trabajar mucho con los datos de origen para tratar de entender y acorralar bien a las variables que mejor podrían predecir el eventual «default» de un cliente.
Un total de 110.000 registros, para entrenar un modelo de Machine Learning. Por si alguien se anima en ver todo lo que pudo trabajar Iker, aquí os dejamos un enlace donde podréis encontrar el dataset. Y aquí los criterios de evaluación seguidos, que creo pueden ser interesantes para entender cómo funcionan este tipo de modelos predictivos.
Le pedí a Iker un breve párrafo describiendo su experiencia, dado que al final, nadie mejor que él para describirla. Y, muy amablemente, me envío esto, que para nosotros, desde Deusto Ingeniería, es un placer poder leer:
En los últimos meses del Programa en Big Data buscando documentación, formación y sobre todo datos que pudiese utilizar en un proyecto con el que poder poner en práctica los conocimientos que estaba adquiriendo me encontré con una Web esponsorizada por Microsoft en la que se ofrecen varios retos en los que poder poner en práctica tus conocimientos en análisis de datos. Estos retos ofrecen una visión bastante completa de lo que sería el ciclo de vida de un proyecto de análisis de datos como la limpieza del dataset, detección de outliers, normalización de datos, etc. Además algo que para mi ha sido muy interesante es que detrás de cada modelo que vas entrenando hay una «validación» de lo «bueno» que es tu modelo con lo que te sirve para darte cuenta de si tienes problemas de overfitting, limpieza de datos correcta, etc. Ya que por detrás de todo esto hay un equipo de gente que valida tu modelo con otros 2 datasets obteniendo un «score» que te permite ir escalando posiciones en una lista de competidores a nivel internacional.
Con todo esto y tras muchas horas de trabajo conseguí obtener la décima posición que para alguien que hace 1 año no sabía ni lo que era la KPI creo que no está nada mal :). Así que animo a todo el mundo con inquietudes en el mundo del dato a participar en este tipo de «competiciones» que te permiten poner a prueba los conocimientos que has adquirido y también a quitarte complejos en esta área de la informática que para algunos nos es nueva.
Felicidades, Zorionak, Congratulations, una vez más, Iker. Un placer poder disfrutar de vuestros éxitos en el mundo del Big Data.
La semana pasada, nos enteramos de una noticia que, para nosotros, los del «Big Data», debe ser bastante relevante: se ha confirmado que Google ha adquirido una de nuestras comunidades preferidas, Kaggle. Quizás alguno se pregunte por qué esta noticia es tan relevante. La propia web de Kaggle te lo dice nada más entrar:
Your Home for Data Science
La casa para hacer «ciencia de datos» o sacar valor a los datos a través de modelos analíticos. En nuestros Programas de Big Data, es frecuente que salga Kaggle durante las clases. No ya solo por invitar a nuestros estudiantes a sus competiciones, lo importante, como suele pasarnos en muchos de estos espacios web, es la comunidad en sí: más de 500.000 personas que se juntan en esa plataforma para discutir alrededor del dato y la ciencia del dato (Data Science). Y que encima, publican datasets con los que «jugar».
Datasets de Kaggle
Es la home o punto de inicio de muchas personas que se dedican al dato. El primer sitio al que acudían a buscar respuesta a algún tema que se nos complicaba. Un lugar donde estaban los mejores de todo el mundo. Donde muchos profesores hemos diseñado clases o hemos construido nuestra forma de afrontar los problemas alrededor de los datos.
Y Kaggle, ahora ha sido adquirida por Google. Esta, llevaba ya un tiempo detrás del tema, al parecer. Acababan de organizar conjuntamente una competición de 100.000 dólares para clasificar vídeos de Youtube. Una competición que permitía la integración nativa con la plataforma de machine learning de Google, la que se ha venido a conocer como Google Cloud Platform. En nuestro Programa en Tecnologías de Big Data en Madrid, ya hemos tenido un par de sesiones con nuestro profesor (y Alumni) Alex Urcola, de Google, alrededor de estas tecnologías y servicios web que ofrece Google.
Y tampoco podemos olvidar que Google seguro ha valorado la cantidad de puestos de trabajo que ya comenzaba a gestionar Kaggle: algo así como un «LinkedIn vertical» para el mundo del Big Data.
Como ven, lo que parece claro, es que la apuesta de Google por el mundo de la inteligencia artificial y el Big Data está claro. Y esto es lo que me parece noticia. Ya hablábamos en un artículo reciente sobre cómo las grandes tecnológicas querían correr en esta carrera por la inteligencia artificial. Es probable que Google ahora busque aglutinar todas sus soluciones de manejo de datos en un mismo ecosistema. Después de liberar TensorFlow (que nació dentro de las necesidades existentes en el equipo Google Brain), ha visto como su uso se dispara. En la carrera que Google mantiene con Amazon por los servicios en la nube, quizás, va siendo momento de verticalizarse en un área donde es fácil que todos veamos a Google como un actor válido y de referencia.
¿Y qué mas tiene Kaggle? Pues obviamente, como comunidad que es, talento. De hecho, de nuevo, basado en cuestiones medianamente intuitivas y lógicas, es fácil pensar que Google quiere tener en su órbita a los mayores expertos en el mundo en el manejo de datos y la algoritmia. Y eso, hoy en día, está en Kaggle. Y es que reclutar talento en esta era digital y de datos, es sin duda alguno, el gran reto que afrontan las comunidades. Que Kaggle haya sido capaz de construir ese ecosistema alrededor, hace que todos entendamos que estar cerca del talento, sea absolutamente necesario.
En el módulo de negocio del Programa de BI y Big Data hacemos un ejercicio con los alumnos. Les proponemos transformar una industria, a priori tradicional, en un modelo de negocio totalmente diferente, gracias al uso de los datos. A lo largo de las tres ediciones hemos transformado negocios tan diversos como la apicultura, la distribución de contenidos, franquicias para despiojar o peluquerías.
Uno de los casos habituales es la transformación de una OEM de automoción (fabricante de automóviles), una industria cuya transformación se acelera con las evoluciones hacia los vehículos eléctricos y autónomos. Pero esta industria tiene más cambios que abordar. A los alumnos les preguntamos, ¿cómo imaginas el mundo dentro de 10 años? ¿Y cual es el papel que ocuparían los actuales fabricantes de vehículos sabiendo que cada vez se van a vender menos vehículos y habrá más competidores?
Lo habitual es recurrir a las fórmulas en auge como el carsharing, pero pensemos en la movilidad como si fuera un servicio (Maas) y en el coche como si fuera un smartphone, el dispositivo a través del cual interaccionamos con otras aplicaciones y servicios mientras viajamos, conduciendo o no.
Entrando en otras industrias
Esta es la gran pregunta que se están haciendo los fabricantes de vehículos, ¿en qué industrias puedo incursionar gracias a los datos que extraigo de mis usuarios y dispositivos (vehículos)? y ¿a cuanto de su mercado puedo aspirar? McKinsey estimó hace dos años que la industria crecerá 215 mil millones de dólares, y esto sin construir más automóviles.
Fuente imagen: https://unsplash.com | Autor Karlis Dambrans |
Por ejemplo un sector como el de las aseguradoras que están haciendo grandes esfuerzos y aproximaciones para competir con alguien que sabe cada kilómetro que recorre un asegurado: la distancia, el día, la hora, la meteorología, los accidentes cercanos, la ocupación de vehículo, la velocidad a la que circula, las personas con las que viaja, el motivo del viaje (fiesta, negocios?), etc. Todas son variables que en un análisis del riesgo (scoring) hace que un seguro sea más barato (menos riesgo) que otro. Pólizas de seguro a medida, no por vehículo y edad como existen ahora, sino por kilómetro, circunstancia y minuto, y en tiempo real, ajustándose a las variaciones de los parámetros según viajamos. ¿Por qué un seguro debe cobrar cuando un vehículo está aparcado en nuestro garaje? Porque sin datos deben prever las coberturas de accidentes tanto si está en uso como sino, calculando entre el grueso de sus clientes la rentabilidad global de la actividad. No pueden hacer una oferta personalizada como la que podrían estar ofreciendo si dispusieran de datos, sino un sistema en el que los justos pagan por pecadores para que las cuentas cuadren a final de año. Los seguros van a tener más difícil que un fabricante de vehículos el acceso a estos datos durante la conducción. Una vez más, quien tiene el contacto con el usuario y el cliente final tiene el control del negocio, y en pocos años serán los OEM los que controlen este contacto.
¿Puede el fabricante de automóviles, que conoce todos nuestros movimientos y rutinas, convertirse en quien abastezca energéticamente a nuestros vehículos? Calculando los consumos, distancias, desplazamientos podría ofertar tarifas planas para abastecer de energía eléctrica a sus clientes conductores, incluso ofrecerles puntos de carga a los que estamos poco acostumbrados hasta ahora: cargadores de vehículos en los parking de los supermercados mientras hacemos la compra, en la universidad mientras estamos en clase, en el museo, en la playa ¿en una propiedad privada? ¿Quien es el único que sabe cuántos conductores, y a qué hora, y con cuánta recurrencia pasan por allí con los depósitos de electricidad llenos o vacíos?
Un vehículo que tiene absolutamente todo medido y calculado (y está en red con decenas de miles de vehículos y dispositivos) sabe si una ruta es más o menos económica, rápida o cómoda porque sabe el tráfico que hay, la velocidad a la que se puede viajar, y las alternativas. ¿Pagarías 5 euros por ahorrarte 7 en un desplazamiento? ¿Cambiarías de ruta si te ofrecen “llenar” el depósito al 50% porque hay un sobrante de energía en un determinado lugar en un determinado momento? Una vez más el vehículo intermediaría entre la oferta y la demanda y sería quien haría la reserva del servicio y por último, el pago (otra intermediación conseguida en una industria indirecta: la banca).
De igual forma actuaría con los mantenimientos, al identificarnos como usuario al entrar en un automóvil, automáticamente va a conocer nuestras configuraciones, nuestros hábitos y preferencias. Conocerá por ejemplo los viajes que hemos realizado anteriormente, los destinos habituales, el número de paradas. Y puede ofrecer un servicio de mantenimiento personalizado, en base a la probabilidad más alta de ser contratado por esa persona en ese momento y en ese lugar.
Podría llegar a ofrecernos música y contenidos audiovisuales (videos, podcast…) Conocería la música que habitualmente escuchamos cuando estamos viajando. Al usuario podría interesarle contratar temporalmente un servicio de streaming durante el trayecto, con una intermediación entre un Spotify o Apple Music y el viajero, y cobrándole una tasa por el tiempo de escucha de la música, vídeo, etc.
¿Podría un OEM de automoción atacar otros negocios como el de la economía colaborativa, tipo UBER, Blablacar, etc…? ¿Podría intermediar en el transporte de personas y cargas en vehículos entre empresas y particulares? Si UBER, Blablacar, Airbnb están funcionando es gracias a los datos que consigue durante la prestación de sus servicios, y la interacción digital con los mismos. No olvidemos que los fabricantes de automóviles van a ser los mejor posicionados para obtener estos datos, con opciones, si lo hacen bien, de apropiarse del negocio del alquiler, el carsharing, el free-car y cuanto modelo esté en contacto con el desplazamiento, la movilidad, los viajes….
Con datos, solo hay que echarle imaginación y hacer números… y usar las tecnologías Big Data.
Ya va a hacer un año de lo que muchos bautizaron como uno de los principales hitos de la historia de la Inteligencia Artificial. Un algoritmo de inteligencia artificial de Google, derrotaba a Lee Sedol, hasta entonces el campeón mundial y mayor experto del juego «Go». Un juego creado en China hace entre 2.000 y 3.000 años, y que goza de gran popularidad en el mundo oriental.
AlphaGo, el «jugador inteligente» de Google derrotando a Lee Sedol, experto ganador del juego «Go» (Fuente: https://qz.com/639952/googles-ai-won-the-game-go-by-defying-millennia-of-basic-human-instinct/)
No era la primera vez que las principales empresas tecnológicas empleaban estos «juegos populares» para mostrar su fortaleza tecnológica y progreso. Todavía recuerdo en mi juventud, allá por 1997, ver en directo cómo Deep Blue de IBM derrotaba a mi ídolo Garry Kasparov. O como Watson, un sistema inteligente desarrollado también por IBM, se hizo popular cuando se presentó al concurso Jeopardy y ganó a los dos mejores concursantes de la historia del programa.
La metáfora de la «batalla» muchos la concebimos como la «batalla» del humano frente a la inteligencia artificial. La conclusión de la victoria de los robots parece clara: la inteligencia artificial podía ya con el instinto humano. Nuestra principal ventaja competitiva (esos procesos difícilmente modelizables y parametrizables como la creatividad, el instinto, la resolución de problemas con heurísticas improvisadas y subjetivas, etc.), se ponía en duda frente a las máquinas.
No solo desde entonces, sino ya tiempo atrás, las principales empresas tecnológicas, están corriendo en un entorno de competitividad donde disponer de plataformas de explotación de datos basadas en software de inteligencia artificial es lo que da competitividad a las empresas. Amazon, Google, IBM, Microsoft, etc., son solo algunas de las que están en esta carrera. Disponer de herramientas que permiten replicar ese funcionamiento del cerebro y comportamiento humano, ya hemos dicho en varias ocasiones, abre nuevos horizontes de creación de valor añadido.
¿Qué es una plataforma de inteligencia artificial? Básicamente un software que una empresa provee a terceras, que hace que éstas, dependan de la misma para su día a día. El sistema operativo que creó Microsoft (Windows) o el buscador que Alphabet creó en su día (Google), son dos ejemplos de plataformas. Imaginaros vuestro día a día sin sistema operativo o google (¿os lo imagináis?). ¿Será la inteligencia artificial la próxima frontera?
No somos pocos los que pensamos que así será. IBM ya dispone de Watson, que está tratando de divulgar y meter por todas las esquinas. Una estrategia bajo mi punto de vista bastante inteligente: cuanta más gente lo vea y use, más valor añadido podrá construir sobre la misma. Es importante llegar el primero.
Según IDC, para 2020, el despliegue masivo de soluciones de inteligencia artificial hará que los ingresos generados por estas plataformas pase de los 8.000 millones de dólares actuales a los más de 47.000 millones de dólares en 2020. Es decir, un crecimiento anual compuesto (CAGR), de más de un 55%. Estamos hablando de unas cifras que permiten vislumbrar la creación de una industria en sí mismo.
CAGR de los sistemas de inteligencia artificial y cognitivos (Fuente: http://www.idc.com/getdoc.jsp?containerId=prUS41878616)
¿Y qué están haciendo las grandes tecnológicas? IBM, que como decíamos antes lleva ya tiempo en esto, creó en 2014, una división entera para explotar Watson. En 2015, Microsoft y Amazon han añadido capacidades de machine learning a sus plataformas Cloud respectivas. A sus clientes, que explotan esos servicios en la nube, les ayudan prediciendo hechos y comportamientos, lo que las aporta eficiencia en procesos. Un movimiento, bastante inteligente de valor añadido (siempre que se toque costes e ingresos que se perciben de manera directa, el despliegue y adopción de una tecnología será más sencillo). Google ha sacado en abierto (un movimiento de los suyos), TensorFlow, una librería de inteligencia artificial que pone a disposición de desarrolladores. Facebook, de momento usa todas las capacidades de análisis de grandes volúmenes de datos para sí mismo. Pero no será raro pensar que pronto hará algo para el exterior, a sabiendas que atesora uno de los mayores tesoros de datos (que esto no va solo de software, sino también de materias primas).
Según IDC, solo un 1% de las aplicaciones software del mundo disponen de características de inteligencia artificial. Por lo tanto, es bastante evidente pensar que su incorporación tiene mucho recorrido. En el informe que anteriormente decíamos, también vaticina que para ese 2020 el % de empresas que habrán incorporado soluciones de inteligencia artificial rondará el 50%.
Por todo ello, es razonable pensar que necesitaremos profesionales que sean capaces no solo de explotar datos gracias a los algoritmos de inteligencia artificial, sino también de crear valor sobre estos grandes conjuntos de datos. Nosotros, con nuestros Programas de Big Data, esperamos tener para rato. Esta carrera acaba de comenzar, y nosotros llevamos ya corriéndola un tiempo para estar bien entrenados. La intuición humana, no obstante, esperamos siga siendo difícilmente modelizable. Al menos, que podamos decirles a los algoritmos, qué deben hacer, sin perder su gobierno.