El 7 de mayo de 2020, Ibon Bolaños nos contó como Hadoop no es un ecosistema cerrado y que son muchas las herramientas que pueden interactuar con el. Se hizo una breve exposición de como Hadoop se está quedando atrás en detrimento de Spark. Y por último, se dieron unas pinceladas de en qué momento puede ser interesante plantearse ir a la nube
Archivo de la etiqueta: spark
Big Data: la posición más difícil de cubrir en España
El pasado 7 de marzo, Cinco Días, publicaba esta noticia: «Big data, el perfil más difícil de cubrir en España«. Según el artículo y sus fuentes, las profesiones asociadas con las tecnologías de Big Data son las más difíciles de cubrir. Su fuente principal es el informe EPYCE 2017: Posiciones y Competencias más demandadas, elaborado por EAE Business School junto con la Asociación Española de Directores de Recursos Humanos (AEDRH), la CEOE, el Foro Inserta de la Fundación Once y Human Age Institute.
En un blog como éste, donde hablamos tanto del paradigma del Big Data y sus múltiples implicaciones en nuestras sociedades, naturalmente, no podíamos dejar sin sacar esta noticia. Llevamos años ya formando perfiles de Big Data en nuestros Programas de Big Data en Bilbao, Donostia y Madrid.
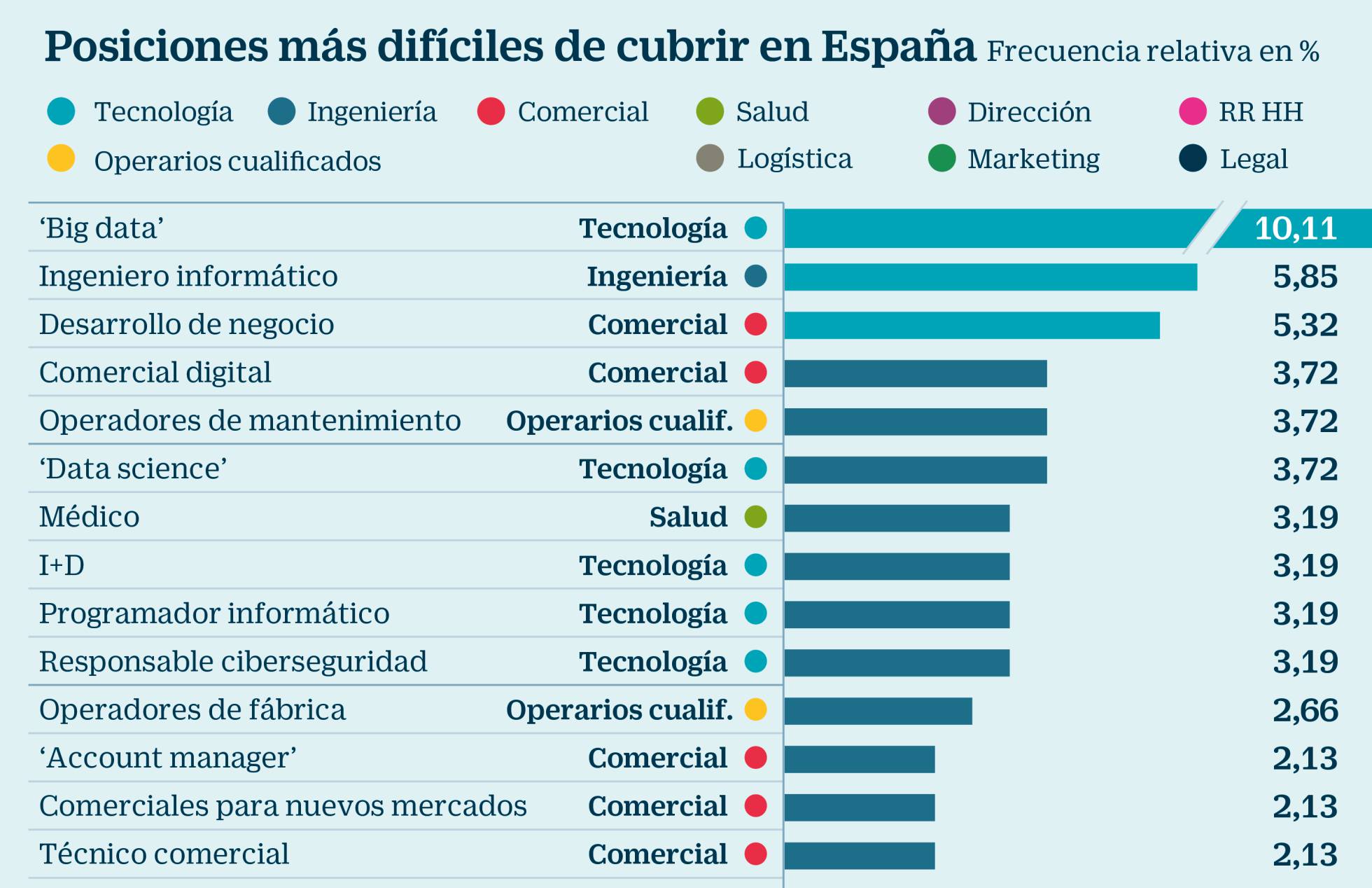
El informe original contiene aún más información. Aspecto que recomiendo revisar, para que se entienda bien no solo la metodología, sino los contenidos (datos) analizados. Miren por ejemplo esta gráfico que adjunto:
Con un nivel de detalle mayor, lo que vemos es que no solo la parte tecnológica (que siempre está en el top de los ranking de bajo desempleo), sino también la ciencia de datos (que son nuestras dos patas fundamentales en nuestros programas), son las más demandadas. En general, hay numerosas profesiones técnicas demandadas en todo el ranking y el informe. Lo cual nos viene a confirmar que efectivamente estamos viviendo una transformación tecnológica y digital en múltiples planos.
Lo que parece que viene a confirmar este informe es que estamos viviendo cierta brecha entre los perfiles que demandan las empresas y lo que realmente se dispone luego en el mercado de trabajo. Parece real esa velocidad a la que se está efectuando esta transformación digital de la sociedad, que está provocando que muchos perfiles no puedan seguirla, y no les dé tiempo a actualizar sus competencias y habilidades. El Big Data, la revolución de los datos, parece que ha venido para quedarse.
No obstante, en relación a todo esto, creo que cabría introducir tres elementos de reflexión. A buen seguro, a cualquier lector o lectora de estas estadísticas, le interesará conocer qué hay más allá de estas gráficas. Básicamente, porque la gestión de expectativas laborales en los programas formativos, creo que debe caracterizarse por la honestidad, para que luego no produzca frustraciones. Estos tres puntos son: (1) Descripción de «supermanes» y «superwomanes» en los puestos de trabajo de las empresas; (2) el concepto «experiencia» en las organizaciones; (3) el talento cuesta dinero.
En relación al (1), darse una vuelta por Linkedin suele ser muy ilustrativo a estos efectos. Las empresas, cuando buscan perfiles «de Big Data» (así en genérico y abstracto), suelen hacerlo solicitando muchas habilidades y competencias que me parece difícil que lo cubra una misma persona: conocimientos de programación (R, Python, Java, etc.), conocimiento de los frameworks de procesamiento de grandes volúmenes de datos y sus componentes (Spark y Hadoop, y ya de paso Storm, Hive, Sqoop, etc.), que sepa administrar un clúster Hadoop, que sepa cómo diseñar una arquitectura de Big Data eficiente y óptima, etc. Una persona que en definitiva, dé soporte a todo el proceso de un proyecto de Big Data, desde el inicio hasta el final. Este enfoque es bastante complicado de cubrir: para una persona manejar todo eso es realmente complicado, dado que no solo los códigos de pensamiento, sino también las habilidades, no suelen estar relacionadas.
En cuanto al (2), que se pida para estos puestos experiencia, me parece un poco temeroso. Estamos hablando de un paradigma que irrumpe con fuerza en 2013. Por lo que estar pidiendo experiencias de más de 2-3-4 años, es literalmente imposible de cubrir. Y menos en España donde todavía no hay tantas realidades en proyectos de Big Data como se cree. ¿Quizás la falta de cobertura de vacantes tenga que ver precisamente con esta situación? Por ello sería bueno saber realmente qué es lo que no están encontrando: ¿el puesto necesario? ¿el puesto definido por las empresas? ¿las expectativas mal gestionadas? Quizás sería bueno, y los empleadores bien saben que siempre les digo, que la formación es un buen mecanismo para poder prescindir de este factor de experiencia. Ahora mismo estamos colaborando con importantes empresas y organizaciones que están formando a varios perfiles a la vez porque son conocedores del límite de la experiencia del que hablamos.
Por último, en cuanto al (3). Hay una expresión inglesa que me gusta rescatar cuando hablo de esto: «You get what you pay«. Una expresión muy común también últimamente en el sector tecnológico. No podemos pretender pagar salarios bajos y que luego tengamos esos supermanes y superwomanes que decía anteriormente. Tenemos que ser coherente con ello. Nuestro conocimiento tecnológico, el talento técnico que formamos en España, está muy bien valorado en muchos lugares de Europa (Dublin, Londres, Berlín, etc.) y el mundo (San Francisco, New York, Boston, etc.). Es normal que en muchas ocasiones este talento se quiera ir al extranjero. ¿Pudiera estar aquí también parte de la explicación de la dificultad para cubrir puestos?
Tecnologías de ingesta de datos en proyectos «Big Data» en tiempo real
Cuando hablamos de las etapas que componían un proyecto de Big Data, y sus diferentes paradigmas para afrontarlo, una cuestión que cité fue la siguiente:
Si antes decíamos que un proyecto “Big Data” consta de cuatro etapas –(1) Ingestión; (2) Procesamiento; (3) Almacenamiento y (4) Servicio-, con este enfoque, nada más ser “ingestados”, son transferidos a su procesamiento. Esto, además, se hace de manera continua. En lugar de tener que procesar “grandes cantidades”, son, en todo momento, procesadas “pequeñas cantidades”.
Hadoop, que marcó un hito para procesar datos en batch, dejaba paso a Spark, como plataforma de referencia para el análisis de grandes cantidades de datos en tiempo real. Y para que Spark traiga las ventajas que solemos citar (100 vez más rápido en memoria y hasta 10 veces más en disco que Hadoop y su paradigma MapReduce), necesitamos sistemas ágiles de «alimentación de datos». Es decir, de ingesta de datos.
Es el proceso por el cual los datos que se obtienen en tiempo real van siendo capturados temporalmente para un posterior procesamiento. Ese momento «posterior» es prácticamente instantáneo a efectos de escala temporal. Esto se está produciendo mucho, por ejemplo, en el mundo de los sensores y el IoT (Internet of Things). No podemos lanzar alarmas en tiempo real si no contamos con una arquitectura como esta. Muchos sectores son ya los que están migrando a estas arquitecturas de ingesta de datos en un mundo en tiempo real.
Y es que el «tiempo real», el streaming, comienza ya desde la etapa de ingestión de datos. Tenemos que conectarnos a fuentes de datos en tiempo real, como decíamos, para permitir su procesamiento instantéano. En la era del Business Intelligence, e incluso en la era del «Big Data batch», los ETL eran los que permitían hacer estas cosas. Hemos hablado ya de su importancia. Sin embargo, son herramientas que en tiempo real, no ofrecen el rendimiento esperado, por lo que necesitamos alternativas.

Estas son el tipo de cosas que permiten hacer Spark y Storm, cuyo paradigma en tiempo real ya comentamos en su día. Aparecen, junto a ellos, una serie de tecnologías y herramientas que permiten implementar y dar sentido a todo este funcionamiento:
- Flume: herramienta para la ingesta de datos en entornos de tiempo real. Tiene tres componentes principales: Source (fuente de datos), Channel (el canal por el que se tratarán los datos) y Sink (persistencia de los datos). Para entornos de exigencias en términos de velocidad de respuesta, es una muy buena alternativa a herramientas ETL tradicionales.
- Kafka: sistema de almacenamiento distribuido y replicado. Muy rápido y ágil en lecturas y escrituras. Funciona como un servicio de mensajería y fue creado por Linkedin para responder a sus necesidades (por eso insisto tanto en que nunca estaríamos hablando de “Big Data” sin las herramientas que Internet y sus grandes plataformas ha traído). Unifica procesamiento OFF y ON, por lo que suma las ventajas de ambos sistemas (batch y real time). Es un sistema distribuido de colas, el más conocido actualmente, pero existen otros como RabbitMQ, y soluciones en la cloud como AWS Kinesis.
- Sistemas de procesamiento de logs, donde podemos encontrar tecnologías como LogStash, Chukwa y Fluentd.
Con estas principales tecnologías en el menú, LogStash y Flume, se han convertido en las dos principales soluciones Open Source para lo que podríamos bautizar como «ETL en tiempo real». Es decir, para la necesidad de recoger datos en tiempo real. La ingesta de datos como etapa de un proyecto de Big Data.
Y, de este modo, nacen «packs tecnológicos» alternativos al ETL como es EFK, acrónimo de Elastic Search + Flume + Kibana. Se trata de una plataforma para procesar datos en tiempo real, tanto estructurados como no estructurados. Todo ello, con tecnologías Open Source, lo que podría venir a animar a muchas empresas que lean esta noticia, y entiendan el valor que tiene esto para sus seguras necesidades (cada vez más) en tiempo real.
- Elastic Search: motor de búsqueda, orientado a documentos, basado en Apache Lucene.
- Flume: ejcución de procesos de extracción, transformación y carga de datos de manera eficiente.
- Kibana: dashboards en tiempo real, procesando y aprovechando los datos en tiempo real indexados vía Elastich Search.
Con todo esto, quedarían esquemas tecnológicamente muy enriquecidos y útiles para necesidades de negocio como el que se presenta a continuación:
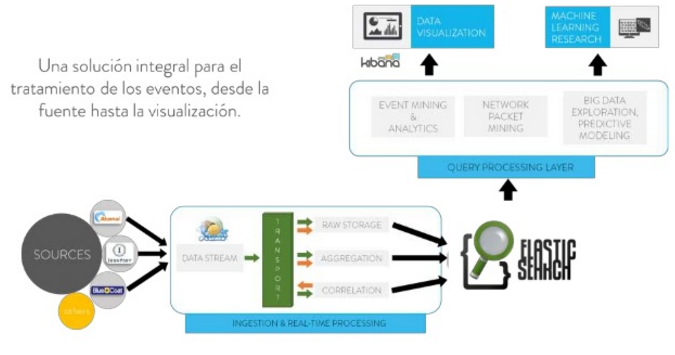
Como podéis apreciar, en estos ecosistemas, los ETL ya no cumplen la función que han venido desempeñando históricamente. Su rendimiento en tiempo real es realmente bajo. Por lo que tenemos que dar un paso más allá. E introducir nuevas tecnologías de ingestión de datos. Kakfa, Flume, Elastic Search, etc., son esas tecnologías. Si tu empresa está empezando a tener problemas con el datamart tradicional, o si la base de datos ya no da mucho más de sí, quizás en este ecosistema tecnológico tengamos la solución.
Nosotros, en nuestro Programa de Big Data, todo esto lo vemos durante 25 horas, montando una arquitectura en tiempo real que dé respuesta a las necesidades de empresas que cada vez necesitan más esto. Las tecnologías de ingesta de datos al servicio de las necesidades de negocios en tiempo real.
Arquitectura Lambda para sistemas Big Data (y III)
(venimos de una serie hablando de los tres paradigmas, para haber hablado luego del paradigma batch y luego del tiempo real)
Terminamos esta serie de artículos, hablando de las arquitecturas Lambda. Y es que una de las cosas que decíamos a la hora de procesar flujos de datos en tiempo real, es que se puede no renunciar a la aproximación batch. Es decir, que podemos diseñar sistemas de Big Data que los integren a ambos, dando así una opción genérica y que para cada necesidad concreta, pueda emplear las tecnologías Batch o Tiempo Real.
Nathan Marz publicó el libro «Big Data: Principles and best practices of scalable realtime data systems» en abril de 2015 para explicar todo esto (aquí está el primer capítulo, gratis). Lo resumió en «la Arquitectura Lambda«, que representamos a continuación:

En la web http://lambda-architecture.net/ se puede comprobar como son muchos los casos de aplicación de este paradigma que se han producido en los últimos tiempos.
El problema ante el que nos solemos encontrar al tratar con grandes volúmenes de datos es que no existe una técnica predefinida para hacerlo. Ya hemos visto con los paradigmas anteriores que el enfoque a adoptar para el procesamiento puede ser diferente. En esta ocasión, el creador de este paradigma Lambda, propone descomponer el problema en tres capas: Batch, Serving y Speed.

En este paradigma todo comienza con una ecuación que podríamos formular de la siguiente manera: query = function(all data). Consiste en que en esa capa Batch inicial que veíamos, disponer de vistas indexadas de datos que han sido pre-computadas, de tal manera que cuando tenga una necesidad en tiempo real, no necesite procesar todo el largo conjunto de datos, sino simplemente acceder a la vista de datos que tuviera pre-computada. De esta manera, me adelanto a la necesidad de consultar datos, disponiendo de largos subconjuntos de los mismos ya pre-computados, de tal manera que se trataría de localizar los mismos. Es importante entrever que estas pre-consultas son aleatorias, por lo que para analizar todo el dataset tendríamos que lanzar varias consultas.
Supongamos que tenemos un proyecto de análisis de datos de una web con Google Analytics. Dejamos así «preparada» una función con todas las métricas que quisiéramos consultar (páginas vistas, visitantes únicos, búsquedas orgánicas, etc.) en una función con (URL, día). De esta manera, cuando queramos lanzar una consulta para un día determinado, solo necesitaríamos consultar la vista del rango de día donde hubiera caído el día concreto que nos interesa, y así, ágilmente, conseguir la información que nos interesa. En esta capa intervienen Hadoop o Spark.
Posteriormente, tenemos la capa de servicio. La capa anterior, creaba esas vistas con los datos pre-computados. Pero, siempre necesitaremos una capa que cargue esas vistas en algún lugar que luego permita se puedan consultar. Esto se hace en la capa de servicio. Indexa las vistas creadas en la capa batch, las actualiza cada vez que llegan nuevas versiones de la capa batch. Dado que no recibe escrituras de datos «aleatorias» (que suele ser el factor que hace realmente lenta una Base de Datos tradicional), esta capa es realmnete robusta, predecible, fácil de configurar y operar. Ya ven, un problema habitual de las bases de datos, resuelto no tanto con tecnología (que también), sino con enfoques de tratamiento de datos. En esta capa, destaca ElaphantDB, por ejemplo.
Y, por último, aparece la capa de velocidad. Cuando alguien quiere acceder a una consulta de datos, lo hace a través de una combinación de la capa de servicio y de la capa de velocidad. Esto lo podemos ver en el siguiente gráfico:

La capa de velocidad es similar a la batch en el sentido que produce vistas a partir de los datos que recibe. Ahora bien, hay algunas diferencias clave. La más importante es que para conseguir altas velocidades, esta capa no mira a todos los nuevos datos de golpe. Solo actualiza aquellos nuevos datos que recibe, lo que le permite ofrecer de manera efectiva consultas de datos en tiempo real. Por eso se suele decir que esta capa actúa con actualizaciones incrementales, solo marcando como nuevo aquello que sea estrictamente necesario para ofrecer al usuario una vista en tiempo real.
Y todos esos módulos y funcionalidades es lo que nos permite disponer de una arquitectura Lambda que de manera completa representamos en la siguiente figura. Nada mejor para seguir ampliando conocimientos que leer el libro de Nathan Marz, que lo explica realmente bien y al detalle.

Con este artículo, cerramos esta serie en la que hemos hablado de los diferentes paradigmas para afrontar un proyecto de Big Data real. Como veis, muchas novedades, y mucha cabeza puesta en hacer sistemas realmente eficientes y ágiles para las organizaciones.
Paradigma tiempo real para sistemas Big Data (II)
(venimos de una serie de un artículo introductorio a los tres paradigmas, y de uno anterior hablando del paradigma batch)
Decíamos en el artículo anterior, que a la hora de procesar grandes volúmenes de datos existen dos principales enfoques: procesar una gran cantidad de datos por lotes o bien hacerlo, en pequeños fragmentos, y en «tiempo real». Parece, así, bastante intuitivo pensar cuál es la idea del paradigma en tiempo real que trataremos en este artículo.
Este enfoque de procesamiento y análisis de datos se asienta sobre la idea de implementar un modelo de flujo de datos en el que los datos fluyen constantemente a través de una serie de componentes que integran el sistema de Big Data que se esté implatando. Por ello, se le como como procesamiento «streaming» o de flujo. Así, en tiempos muy pequeños, procesamos de manera analítica parte de la totalidad de los datos. Y, con estas características, se superan muchas de las limitaciones del modelo batch.
Por estas características, es importante que no entendamos este paradigma como la solución para analizar un conjunto de grandes datos. Por ello, no presentan esa capacidad, salvo excepciones. Por otro lado, una cosa es denominarlo «tiempo real» y otra es realmente pensar que esto se va a producir en veradero tiempo tiempo. Las limitaciones aparecen por:
- Se debe disponer de suficiente memoria para almacenar entradas de datos en cola. Fíjense en la diferencia con el paradigma batch, donde los procesos de Map y Reduce podrían ser algo lentos, dado que escribían en disco entre las diferentes fases.
- La tasa de productividad del sistema debería ser igual o más rápida a la tasa de entrada de datos. Es decir, que la capacidad de procesamiento del sistema sea más ágil y eficiente que la propia ingesta de datos. Esto, de nuevo, limita bastante la capacidad de dotar de «instantaneidad al sistema».

Uno de los principales objetivos de esta nueva arquitectura es desacoplar el uso que se hacía de Hadoop MapReduce para dar cabida a otros modelos de computación en paralelo como pueden ser:
- MPI (Message Passing Interface): estándar empleado en la programación concurrente para la sincronización de procesos ante la existencia de múltiples procesadores.
- Spark: plataforma desarrollada en Scala para el análisis avanzado y eficiente frente a las limitaciones de Hadoop. Tiene la habilidad de mantener todo en memoria, lo que le da ratios de hasta 100 veces mayor rapidez frente a MapReduce. Tiene un framework integrado para implementar análisis avanzados. Tanto Cloudera, como Hortonworks, lo utilizan.
Y, con estos nuevos modelos, como hemos visto a lo largo de esta corta pero intensa historia del Big Data, aparecen una serie de tecnologías y herramientas que permiten implementar y dar sentido a todo este funcionamiento:
- Flume: herramienta para la ingesta de datos en entornos de tiempo real. Tiene tres componentes principales: Source (fuente de datos), Channel (el canal por el que se tratarán los datos) y Sink (persistencia de los datos). Para entornos de exigencias en términos de velocidad de respuesta, es una muy buena alternativa a herramientas ETL tradicionales.

- Kafka: sistema de almacenamiento distribuido y replicado. Muy rápido y ágil en lecturas y escrituras. Funciona como un servicio de mensajería y fue creado por Linkedin para responder a sus necesidades (por eso insisto tanto en que nunca estaríamos hablando de «Big Data» sin las herramientas que Internet y sus grandes plataformas ha traído). Unifica procesamiento OFF y ON, por lo que suma las ventajas de ambos sistemas (batch y real time). Funciona como si fuera un cluster.
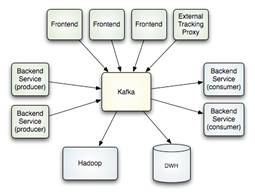
- Storm: sistema de computación distribuido, por lo que se emplea en la etapa de análisis de datos (de la cadena de valor de un proyecto de Big Data). Se define como un sistema de procesamiento de eventos complejos (Complex Event Processing, CEP), lo que le hace ideal para responder a sistemas en los que los datos llegan de manera repentina pero continua. Por ejemplo, en herramientas tan habituales para nosotros como WhatsApp, Facebook o Twitter, así como herramientas como sensores (ante la ocurrencia de un evento) o un servicio financiero que podamos ejecutar en cualquier momento.
Vistas estas tres tecnologías, queda claro que la arquitectura resultante de un proyecto de tiempo real quedaría compuesto por Flume (ingesta de datos de diversas fuentes) –> Kafka (encolamos y almacenamos) –> Storm (analizamos).
Vistas todas estas características, podemos concluir que para proyectos donde el «tamaño» sea el *verdadero* problema, el enfoque Batch será el bueno. Cuando el «problema» sea la velocidad, el enfoque en tiempo real, es la solución a adoptar.
(continuará)
Paradigma batch para sistemas Big Data (I)
(venimos de un artículo introductorio a los tres paradigmas)
Cuando hablamos del verdadero momento en el que podemos considerar nace esta «era del Big Data», comentamos que se puede considerar el desarrollo de MapReduce y Hadoop como las primeras «tecnologías Big Data». Estas tecnologías se centraban en un enfoque de Batch Processing. Es decir, el objetivo era acumular todos los datos que se pudieran, procesarlos y producir resultados que se «empaquetaban» por lotes.
Con este enfoque, Hadoop ha sido la herramienta más empleada. Es una herramienta realmente buena para almacenar enormes cantidades de datos y luego poder escalarlos horizontalmente mientras vamos añadiendo nodos en nuestro clúster de máquinas.
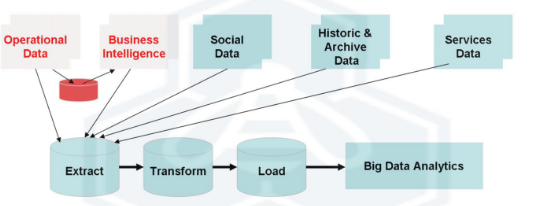
Como se puede apreciar en la imagen, el «problema» que aparece en este enfoque es que el retraso en tiempo que introduce disponer de un ETL que carga los datos para su procesamiento, no será tan ágil como hacerlo de manera continua con un enfoque de tiempo real. El procesamiento en trabajos batch de Hadoop MapReduce es el que domina en este enfoque. Y lo hace, apoyándose en todo momento de un ETL, de los que ya hablamos en este blog.
Hasta la fecha la gran mayoría de las organizaciones han empleado este paradigma «Batch». No era necesaria mayor sofisticación. Sin embargo, como ya comentamos anteriormente, existen exigencias mayores. Los datos, en muchas ocasiones, deben ser procesados en tiempo real, permitiendo así a la organización tomar decisiones inmediatamente. Esas organizaciones en las que la diferencia entre segundos y minutos sí es crítica.
Hadoop, en los últimos tiempos, es consciente de «esta economía de tiempo real» en la que nos hemos instalado. Por ello, ha mejorado bastante su capacidad de gestión. Sin embargo, todavía es considerado por muchos una solución demasiado rígida para algunas funciones. Por ello, hoy en día, «solo» es considerado el ideal en casos como:
- No necesita un cálculo con una periodicidad alta (una vez al día, una vez al de X horas, etc.)
- Cálculos que se deban ejecutar solo a final de mes (facturas de una gran organización, asientos contables, arqueos de caja, etc.)
- Generación de informes con una periodicidad baja.
- etc.
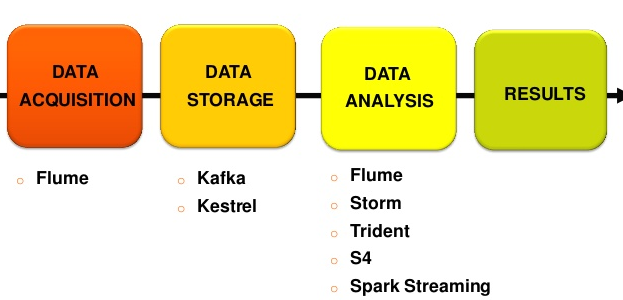
Como el tema no es tan sencillo como en un artículo de este tipo podamos describir, en los últimos años han nacido una serie de herramientas y tecnologías alrededor de Hadoop para ayudar en esa tarea de analizar grandes cantidades de datos. Para analizar las mismas -a pesar de que cada una de ellas da para un artículo por sí sola-, lo descomponemos en las cuatro etapas de la cadena de valor de un proyecto de Big Data:
1) Ingesta de datos
Destacan tecnologías como:
- Flume: recolectar, agregar y mover grandes cantidades de datos desde diferentes fuentes a un data store centralizado.
- Comandos HDFS: utilizar los comandos propios de HDFS para trabajar con los datos gestionados en el ecosistema de Hadoop.
- Sqoop: permitir la transferencia de información entre Hadoop y los grandes almacenes de datos estructurados (MySQL, PostgreSQL, Oracle, SQL Server, DB2, etc.)
2) Procesamiento de datos
Destacan tecnologías como:
- MapReduce: del que ya hablamos, así que no me extiendo.
- Hive: framework creado originalmente por Facebook para trabajar con el sistemas de ficheros distribuidos de Hadoop (HDFS). El objetivo no era otro que facilitar el trabajo, dado que a través de sus querys SQL (HiveQL) podemos lanzar consultas que luego se traducen a trabajos MapReduce. Dado que trabajar con este último resultaba laborioso, surgió como una forma de facilitar dicha labor.
- Pig: herramienta que facilta el análisis de grandes volúmenes de datos a través de un lenguaje de alto nivel. Su estructura permite la paralelización, que hace aún más eficiente el procesamiento de volúmenes de datos, así como la infraestructura necesaria para ello.
- Cascading: crear y ejecutar flujos de trabajo de procesamiento de datos en clústeres Hadoop usando cualquier lenguaje basado en JVM (la máquina virtual de Java). De nuevo, el objetivo es quitar la complejidad de trabajar con MapReduce y sus trabajos. Es muy empleado en entornos complejos como la bioinformática, algoritmos de Machine Learning, análisis predictivo, Web Mining y herramientas ETL.
- Spark: facilita enormemente el desarrollo de programas de uso masivo de datos. Creado en la Universidad de Berkeley, ha sido considerado el primer software de código abierto que hace la programación distribuida accesible y más fácil para «más públicos» que los muy especializados. De nuevo, aporta facilidad frente a MapReduce.
3) Almacenamiento de datos
Destacan tecnologías como:
- HDFS: sistema de archivos de un cluster Hadoop que funciona de manera más eficiente con un número reducido de archivos de datos de gran volumen, que con una cantidad superior de archivos de datos más pequeños.
- HBase: permite manejar todos los datos y tenerlos distribuidos a través de lo que denominan regiones, una partición tipo Nodo de Hadoop que se guarda en un servidor. La región aleatoria en la que se guardan los datos de una tabla es decidida, dándole un tamaño fijo a partir del cual la tabla debe distribuirse a través de las regiones. Aporta, así, eficiencia en el trabajo de almacenamiento de datos.
4) Servicio de datos
En esta última etapa, en realidad, no es que destaque una tecnología o herramienta, sino que destacaría el «para qué» se ha hecho todo lo anterior. Es decir, qué podemos ofrecer/servir una vez que los datos han sido procesados y puestos a disposición del proyecto de Big Data.
Seguiremos esta serie hablando del enfoque de «tiempo real», y haciendo una comparación con los resultados que ofrece este paradigma «batch».
Procesando «Big Data»: paradigmas batch, tiempo real y Lambda
Lo que podemos llamar como la cadena de valor de un proyecto Big Data consiste básicamente en recopilar/integrar/ingestar, procesar, almacenar y servir grandes volúmenes de datos. Eso es, en esencia, lo que hacemos en un proyecto de BIg Data. Para ejecutar esas funciones, como hemos comentado en este blog en varias ocasiones, tenemos una serie de tecnologías, que suelen ser citadas en ocasiones en relación a la función que ejercen. Es lo que aprendemos en nuestro módulo M2.2 del Programa de Big Data y Business Intelligence de nuestra universidad.
Dado el interés que está despertando en los últimos años la parte «procesamiento» (debido fundamentalmente a cómo se origina esto del Big Data) es interesante hablar de las diferentes alternativas tecnológicas que existen para procesar «Big Data». Ya saben, datos que se disponen en grandes volúmenes, que se generan a gran velocidad y con una amplitud de formatos importante.
Esta etapa de la cadena de valor es la responsable de recoger los datos brutos y convertirlos/transformarlos a datos enriquecidos que pueden dar respuesta a la pregunta que nos estamos haciendo. Y para enfrentar esta etapa, en los últimos años, se han desarrollado dos paradigmas fundamentales:
- Paradigma «Batch Processing«: son procesos que se asientan fundamentalmente en el paradigma MapReduce, que ya explicamos en un artículo anterior, y que decíamos, permitió comenzar esta apasionante carrera alrededor del Big Data. Siguen el modelo «batch» que tan importante resultó en el mundo de la informática original: se ejecutan de manera periódica y trabajan con grandísimos volúmenes de datos.
Existen varias alternativas para proveer de estos servicios: la más importante es Hadoop MapReduce, que funciona dentro del framework de aplicaciones de Hadoop. Se apoya en el planificador YARN. Dado el bajo nivel con el que trabajan estas tecnologías, estos últimos años han nacido soluciones de más alto nivel para ejecutar estas tareas, tales como Apache Pig.
Estamos hablando de tecnologías que funcionan realmente bien con grandes cantidades de datos. Sin embargo, los procesos de Map y Reduce pueden ser algo lentos cuando estamos hablando de cantidades realmente «BIG», dado que escriben en disco entre las diferentes fases. Por ello, como siempre, se produce una evolución natural, y aparecen tecnologías que resuelven este problema, entre las que destaca Apache Spark.
Haremos un artículo separado, dada su importancia, para hablar exclusivamente y en detalle de este paradigma «Batch Processing«. - Paradigma «Streaming Processing«: a diferencia del enfoque «batch» anterior, el «streaming», como su propio concepto describe, funciona en tiempo real. Si antes decíamos que un proyecto «Big Data» consta de cuatro etapas –(1) Ingestión; (2) Procesamiento; (3) Almacenamiento y (4) Servicio-, con este enfoque, nada más ser «ingestados», son transferidos a su procesamiento. Esto, además, se hace de manera continua. En lugar de tener que procesar «grandes cantidades», son, en todo momento, procesadas «pequeñas cantidades».
Como con el enfoque batch, hay una serie de tecnologías que permiten hacer esto. Se pueden clasificar en dos familias: 1) Full-streaming: Apache Storm, Apache Samza y Apache Flink; y 2) Microbatch: Spark Streaming y Storm Trident.
Son tecnologías que procesan datos en cuestión de mili o nanosegundos. Se diferencian entre ellas por las garantías que aportan ante fallos en la red o en los sistemas de información. La siguiente tabla resume muy bien estas diferencias. Por lo tanto, más que por «gustos», la diferencia puede radicar en cuanto a su «sistema de garantías»: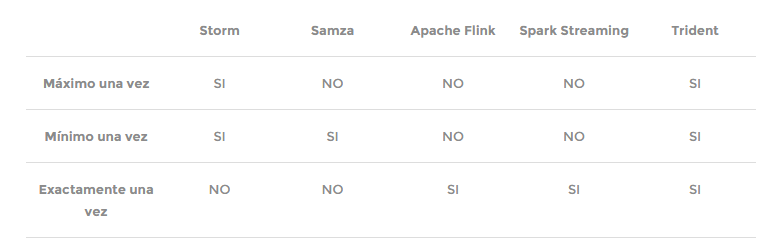
Fuente: http://madrid.bigdataweek.com/2015/11/18/tecnologias-en-el-mundo-del-big-data/ Haremos un artículo separado, dada su importancia, para hablar exclusivamente y en detalle de este paradigma «Streaming Processing«.
A estos dos, podemos añadir la arquitectura Lambda, la más reciente en llegar a este mundo de necesidades en evolución de las diferentes alternativas de procesar datos. Provee parte de solución Batch y parte de solución en Tiempo Real. Como su propio creador Nathan Marz explica aquí:
The lambda architecture solves the problem of computing arbitrary functions on arbitrary data in real time by decomposing the problem into three layers: the batch layer, the serving layer, and the speed layer.
Estamos hablando de diferentes paradigmas; esto es, de diferentes maneras de afrontar el problema. Y dada la importancia de cada uno de ellos, he considerado interesante hacer un artículo monográfico de cada una de ellas. Paradigmas que nos van a ayudar a procesar las grandes cantidades de datos de un proyecto de Big Data. Y conocer y empezar a dominar así las tecnologías que disponemos para cada paradigma.
