En este blog, hemos hablado de ciudades ya en otras ocasiones (aquí, aquí y aquí). Es uno de los campos en los que el «mundo del dato», más está aportando. Básicamente, porque las vivas y dinámicas de una ciudad del Siglo XXI, son núcleos generadores de datos, que también se pueden beneficiar mucho del uso de los mismos.
Son varios ya los investigadores que están tratando de introducir las bondades del análisis de datos masivo en la mejora del bienestar de una ciudad. Desde el MIT Media Lab que hace «crowdsourcing» de los datos para determinar cómo de seguras son unas calles, pasando por el uso de los datos para el diseño, el trazado urbano, etc.
Uno de los investigadores que más se está moviendo en este campo es César Hidalgo. Considera que la visión e inteligencia artificial, son campos técnicos que tienen mucho que aportar a un nuevo campo dentro del conjunto de las ciudades: el impacto social del diseño de una ciudad. En el sentido, de entender cómo las decisiones que se toman a nivel urbano y de diseño, puede impactar en la sensación de seguridad (o no) de los ciudadanos. A esto lo llamo el «impacto social».
¿Y qué pintan todo esto la visión e inteligencia artificial? Durante muchos años, no hemos tenido tecnología a nuestra disposición para entender cómo la estética y el diseño de las ciudades impactaba en las decisiones de los ciudadanos a la hora de transitar por las ciudades. Es justo esto lo que Hidalgo, junto con Marco de Nadai y Bruno Lepri narran en un artículo que presentaron en la próxima ACM Multimedia Conference 2016 celebrada en Octubre en Amsterdam.
Proponen, para testar dicha hipótesis, usar dos teorías ampliamente conocidas en el mundo del diseño de la ciudad:
- Crime prevention through environmental design (CPTED) de Jane Jacobs: las luces, ventanas, espacios abiertos, etc., contribuyen a que sus vecinos se sientan seguros en sus barrios.
- Defensible space theory de Oscar Newman: los detalles arquitectónicos que permiten crear espacios de «defensa» que hacen sentirse más seguros a los ciudadanos.
Para poder testar estas teorías, se apoyaron en una red neuronal. Lo primero, como ya sabemos, es entrenarla. Para ello, utilizaron los datos de Place Pulse, una web desarrollada por Hidalgo en 2013, que pedía a los usuarios que opinasen sobre diferentes imágenes de ciudades, para saber así si les parecían «seguras» o no.
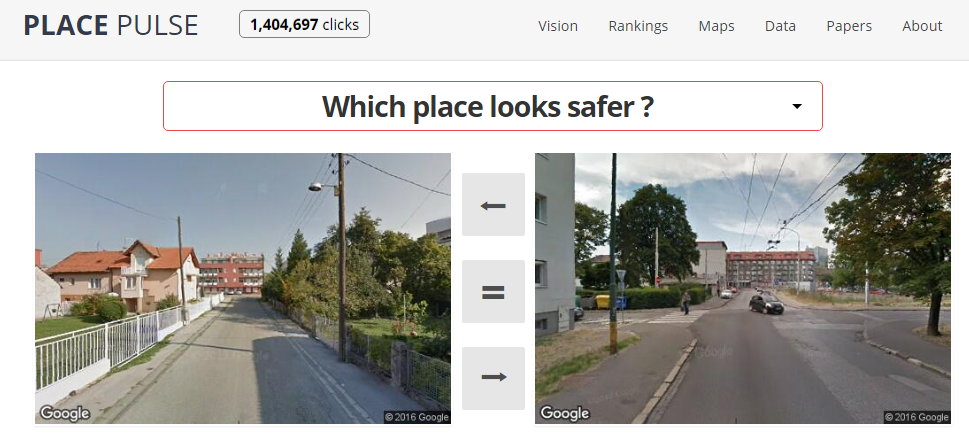
Con la red neuronal entrenada (una «deep convolutional neural network«), comenzaron a analizar miles de imágenes de Google StreetView para tratar de encontrar las características de la ciudad que hacían a sus ciudadanos sentirse más seguros. Para relacionar esos datos con el comportamiento de los ciudadanos, cruzaron los datos con los de los dispositivos móviles. Así, quedaba fijada la relación entre las decisiones humanas dentro de la ciudady las características de las mismas. Todo esto, lo han testado en las dos ciudades Italianas más importantes (Roma y Milan).
Las conclusiones obtenidas son bastante claras:
- Las calles que la red consideraba como «más seguras» son precisamente por donde más gente discurre.
- Personas con más de 50 años, así como mujeres caminando solas, buscan zonas más seguras.
- Personas con menos de 30 años, frecuentan sitios menos seguros.
Esta red neuronal, en consecuencia, puede ser considerada como una primera aproximación a la posibilidad de detectar qué partes de una ciudad son percibidas como menos seguras. Y así, ayudar a los legisladores a establecer puntos de mejora en sus ciudades. Es más, Hidalgo y el resto de autores, probaron diferentes opciones para ver cómo las interpretaba la red neuronal. y vieron como elementos como coches aparcados, paredes en blanco, grandes aceras vacías y la oscuridas, eran percibidas como sitios con poca seguridad. Y es que el diseño de ciudades, tiene implicaciones sociales que ya veis, no siempre había sido fácil de detectar.
En todo esto, como podéis ver, el cruce de datos aparece como protagonista nuclear de la película. Y es que la » V» de variedad, como he comentado en reiteradas ocasiones, veremos tiene cada vez más protagonismo. Quedan todavía muchas aplicaciones que pongan en valor el «Big Data» por hacer. Pero todas ellas comparten interés por cruzar datos de diferentes fuentes. Una ciudad, entre ellas.









