Suelo decir en los cursos que el gran reto que nos queda por resolver es «pintar bien el Big Data«. Con estas palabras semánticamente pobres, lo que trato de decir es que la representación visual del dato no es un tema trivial; y que nos podemos esforzar en hacer un gran proyecto de tratamiento de datos, integración y depuración, etc., que si luego finalmente no lo visualizamos apropiadamente, el usuario puede no estar completamente satisfecho con ello. Por ello, he querido dedicar este artículo para hablar del área del Visual Analytics o visualización analítica e inteligente de datos.
Antoine de Saint-Exupery, autor de “El principito”, dijo eso de “La perfección se alcanza no cuando no hay nada más que añadir, sino cuando no hay nada más que quitar”. Es decir, un enfoque minimalista. Y es que la visualización de información es una mezcla entre narrativa, diseño y estadística. Estos tres campos tienen que ir inexorablemente unidos para no correr el peligro de perderse con la interpretación de la idea a través de estímulos visuales. Las buenas representaciones gráficas, deben cumplir una serie de características:
- Señalar relaciones, tendencias o patrones
- Explorar datos para inferir nuevo conocimiento
- Facilitar el entendimiento de un concepto, idea o hecho
- Permitir la observación de una realidad desde diferentes puntos de vista
- Y permitir recordar una idea.
Estos serán nuestros cinco objetivos cuando representamos algo en una gráfica o representación visual. A partir de hoy, nuestras cinco obsesiones cuando vayamos a representar una idea o relación de manera gráfica. ¿Cumplen estas características tus visualizaciones de datos e información? La puesta en valor del dato, como ven, no es algo trivial. Para prueba, un caso, cogido medianamente al azar:
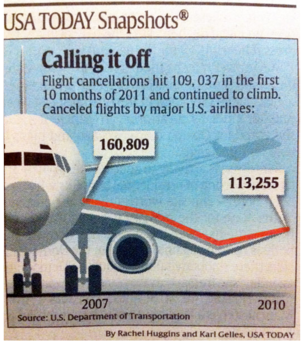
¿Problemas? En primer lugar, ¿qué quiere señalar? Si es una relación, tendencia o patrón, ¿no debería darnos más idea de si los números son relevantes o no? ¿qué significan? ¿cómo me afectan? No facilita entender un concepto, sino que introduce varias dimensiones (tiempo, cancelaciones de vuelos, variación de la tendencia, etc.). Y, encima, lo hace representándolo sobre el ala de un avión. ¿Quiere transmitir seguridad o inseguridad? Genera dudas. Hubiera sido esto más simple si fuera como una cebolla con una única capa: una idea, una relación, un concepto clave. No hace falta más.
La representación visual es una forma de expresión más. Como las matemáticas, la música o la escritura, tiene una serie de reglas que respetar. Hoy en día, en que la cantidad de datos y la tecnología ya no son un problema, el reto para las empresas recae en conocer los conceptos básicos de representación visual. Es lo que se ha venido a conocer como la ciencia del Visual Analytics, definida como la ciencia del razonamiento analítico facilitado a través de interfaces visuales interactivas. De ahí que hoy en día los medios de comunicación utilicen cada vez estas representaciones gráficas de datos e información con las que podemos interactuar.
El uso de representaciones visuales e interactivas de elementos abstractos permite ampliar y mejorar el procesamiento cognitivo. Por lo tanto, para transladar ideas y relaciones, ayuda mucho disponer de una gráfica interactiva. Hay muchos teóricos y autores que se han dedicado a generar teoría y práctica en este campo de la representación visual de información. De hecho, la historia de la visualización no es algo realmente nuevo. En el Siglo XVII, ya destacaron autores como Joseph Priestley y William Playfair. Más tarde, en el Siglo XIX, podemos citar a John Snow, Charles J. Minard y F. Nightingale como los más relevantes (destacando especialmente el primero, que a través de una representación geográfica logró contener una plaga de cólera en Londres). Ya en el Siglo XX, Jacques Bertin, John Tukey, Edward Tufte y Leland Wilkinson son los autores más citados en lo que a visualización y representación de la información se refiere.

Tufte es quizás el autor más citado. Su libro “The Visual Display of Quantitative Information”, una biblia para los equipos de visualización eficientes y rigurosas. De hecho, los principios de Tufte, los podemos resumir en la integridad gráfica y el diseño estético. Siempre destaca cómo los atributos más importantes el color, el tamaño, la orientación y el lugar de la página donde presentamos una gráfica. Y es que, por mucho que nos sorprenda o por simple que nos parezca, la codificación del valor (datos univariados, bivariados o multivariados) y la codificación de la relación de valores (líneas, mapas, diagramas, etc.), no es un asunto trivial. Un ejemplo de esto sería la siguiente gráfica:
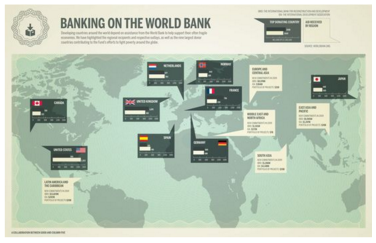
Si cogemos el gráfico anterior y yo os hago preguntas relacionadas con la identificación del mayor donante o el mayor receptor, ustedes tendrían problemas. Quizás con un patrón de color esto se hubiera resuelto. Pero ni con esas. Un mapa no es la mejora manera de representar este tipo de datos (y hoy en día se abusa mucho de los mapas). Si quiero responder a las preguntas anteriores, tengo que realizar una búsqueda de las cifras, memorizarlas y luego compararlas. Lo dicho al comienzo; una idea, un patrón, una relación, y luego, búsqueda de la mejor gráfica para ello. Por eso los gráficos de tarta… mejor dejarlos para el postre 😉 (los humanos no somos especialmente hábiles comparando trozos de un círculo cuando hablamos de áreas… que es lo que propone un gráfico de tarta con los trocitos en los que descomponemos un círculo)
Quizás la referencia más importante de todo esto que estamos hablando se encuentre en el artículo que en 1985 escribieron Cleveland y McGill, titulado “Ranking of elementary perceptual tasks”. Dos investigadores de AT&T Bell Labs, William S. Cleveland y Robert McGill, publicaron este artículo central en el Journal of the American Statistical Association. Propone una guía con las representaciones visuales más apropiadas en función del objetivo de cada gráfico, lo cual nos ofrece otro pequeño manual para ayudarnos a representar la información de manera inteligente y eficiente.
“A graphical form that involves elementary perceptual tasks that lead to more accurate judgements than another graphical form (with the same quantitative information) will result in a better organization and increase the chances of a correct perception of patterns and behavior.” (William S. Cleveland y Robert McGill, 1985)
Dicho todo esto, y con la aparición del Big Data, muchos autores comenzaron a trabajar en crear metodologías eficientes para la visualización de información. Lo que hemos denominado al comienzo como Visual Analytics: la visualización analítica, eficiente e inteligente de datos que ayuda a aumentar el entendimiento e interpretación de una idea, una relación, un patrón, etc.
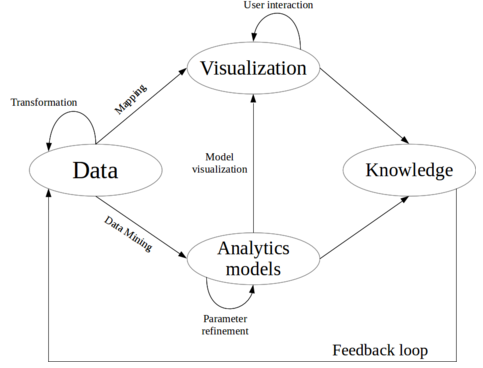
En nuestro Programa de Big Data y Business Intelligence, celebraremos próximamente una sesión en la que precisamente hablaremos de todo esto. Cómo seguir una serie de pasos y criterios a considerar para ayudar al lector, al usuario, a entender y pensar mejor. Un campo que se nutre de los conocimientos del área de Human-Computer-Interaction (HCI) y de la visualización de información. Y, como muestro en la siguiente figura (un proceso de Visual Analytics basado en trabajos de Daniel Keim y otros), aplicaremos un método para pasar del dato al conocimiento, a través de los modelos analíticos y la visualización de información que no confunda, y como decía Saint-Exupery, simplifique.
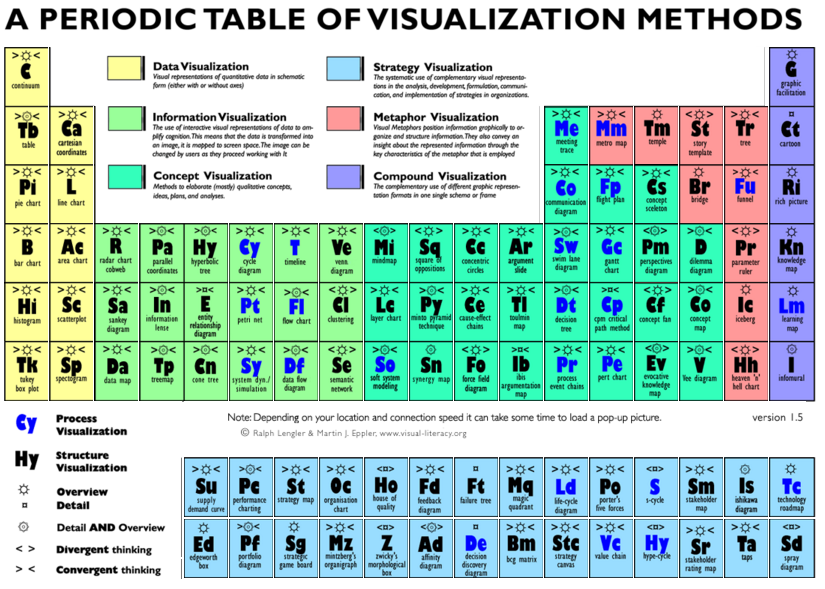
¿Cuál será el resultado de esta sesión? Un dashboard, un informe, un panel de mando de KPIs bien diseñado y elaborado. Es decir, conocimiento eficiente e inteligente para ayudar a las organizaciones a tomar decisiones apoyándose en gráficos bien elaborados. Un dashboard que cumpla con nuestros cinco principios y que permita al estudiante llevarse su tabla periódica de los métodos de visualización eficiente.