Asistiendo a una jornada de Alex Rayón, es cada vez más evidente que la forma de hacer marketing tiene que cambiar. Alex es director del seminario de Big Data & Business Intelligence (BDBI), organizado entre la Facultad de Ingeniería de Deusto y Deusto Business School, y profesor e investigador en la Universidad de Deusto sobre Marketing y Big Data y muy activo en esta área.
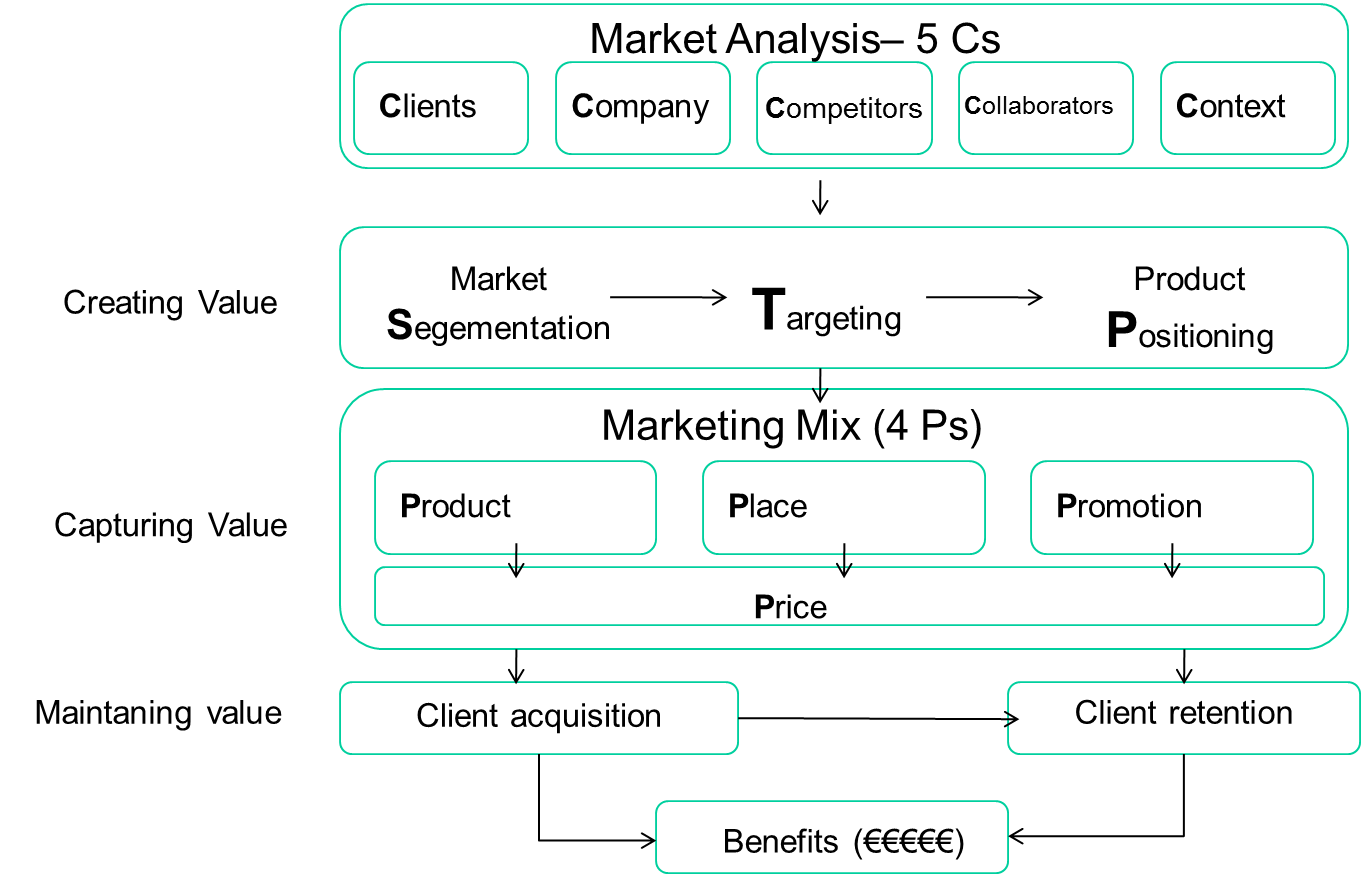
Desde el punto de vista de marketing, tradicionalmente el proceso del marketing (marketing estratégico y marketing operacional) se puede ilustrar con la siguiente figura:
El proceso de marketing (Fuente: elaboración propia)
Evidentemente en el análisis de las 5C, todos los datos que se puedan traducir en información ayudarán a tener un mejor diagnóstico de nuestro entorno.
Pero lo que me interesa de esta jornada es la aplicación del BDBI en la creación de valor para el cliente. Una de las claves en el marketing es la segmentación (¿quién es mi cliente?). Tradicionalmente las empresas identifican quién es su público objetivo, basado en parámetros demográficos, sociales, económicos, comportamiento, etc… de un mercado más general. Con esta identificación, buscan cuáles son sus problemas, necesidades, etc… escogen un público determinado y se posicionan en ese nicho.
Como decía Kotler, gurú del marketing del siglo pasado – como pasa el tiempo-, si resuelves el problema de segmentación, automáticamente tendrás las respuestas para definir tus 4Ps (producto, promoción, lugar y precio) y te saldrán automáticamente. Porque una vez sabes quién es tu potencial cliente, ya sabes qué producto tienes que ofrecerle, qué ventajas tiene que tener sobre los competidores, dónde está y cómo poder llegar a él, qué precio está dispuesto a pagar. Teniendo muy claro quién es mi cliente, cuántas horas de reuniones nos podríamos ahorrar discutiendo sobre el precio…
Evidentemente BDBI tiene mucho que decir en la segmentación. Pero no tanto a priori, si no a posteriori. Con la cantidad de datos que las empresas tienes sobre nosotros, ya no hace falta hacer hipótesis de quién es nuestro cliente: basta mirar en los datos e identificarlos.
Gracias a las herramientas de BDBI (que por cierto, ni son caras ni difíciles de usar), basta un poco de curiosidad, jugar con los datos y empezar a ver correlaciones. ¿Hay alguna relación entre los clientes que compran 2 mismos productos? ¿Es nuestra segmentación inicial la que se refleja en las compras de nuestros clientes y las ventas de nuestros productos? ¿A qué horas del día hay un comportamiento de compra parecido? Por ejemplo, en Tableau, una empresa que intenta facilitar la visualización de BDBI, podéis ver un caso sobre la segmentación y el hecho de cuestionarnos nuestras hipótesis iniciales.
Esta aproximación que aparentemente parece que es sólo válida para comercios B2C online se pueden extraer de otros lugares. El BDBI no es exclusivo de negocios online, nacidos en la era digital. Efectivamente, lo tienen más fácil, pero todas las empresas pueden empezar a explorar. Quizás sea ese uno de los retos para la implementación del BDBI en los negocios que no vienen del mundo online. Como comentaba Alex, un 60%- 80% de los esfuerzos para una estrategia de BDBI se centran en los datos y en el ETL (Extracción, Transformación y carga o Load), encontrarlos entre las diferentes partes del negocio (ERPs, CRM, departamento financiero, controller, etc…), limpiarlos y ponerlos bonitos. Aunque Alex menciona 4 etapas y el tiempo que se va a dedicar a cada etapa:
Etapa 1: Cargar datos (hasta un 80%)
Etapa 2: Preguntas (5%)
Etapa 3: Modelo estadístico/analítico (5%)
Etapa 4: Visualización de resultados (10%)
Quizás mi visión sería empezar por las preguntas y terminar en el modelo estadístico. Pero lo que estoy seguro es que una de las grandes aportaciones del BDBI al marketing es en el tema de segmentación, pasando de una segmentación clásica a una clusterización (que hasta ahora era más complicado). La maravilla del BDBI es que no tenemos que pensar cuáles son las variables para hacer el cluster, las propias herramientas nos dirás qué cluster son los que representan mejor a los clientes y qué características. También, incluso nos permitirá saber cuál es la probabilidad de que un cliente de telefonía abandone su compañía y qué características tiene o saber la características del cliente de un banco portugués que no compra un producto y el proceso comercial asociado. Y por otra parte, ayudarnos a hacer preguntas que hasta ahora ni nos habíamos imaginado.
Lo que está claro, es que si una empresa quiere sobrevivir en los próximos 10 años, de una forma u otra, el BDBI le impactará de alguna manera. La pregunta es ¿espero a que me obliguen o empiezo a explorar ya? La creación de valor en mi organización a través del Big Data y Business Intelligence está a mi disposición.
El 3 de noviembre de 2015, el Director del Programa de Big Data y Business Intelligence, Alex Rayón, entrevistó a través de un webinar a tres expertos profesionales en cada uno de los tres sectores citados: Pedro Gómez (profesional del ámbito financiero), Joseba Díaz (profesional con experiencia en proyectos sanitarios y profesional Big Data en HP) y Jon Goikoetxea (Director de Comunicación y Marketing del Grupo Noticias y el diario Deia y alumno de la primera edición del Programa Big Data y Business Intelligence).
En la sesión pudimos conocer la aplicación del Big Data a los tres sectores (finanzas, sanidad y comunicación&marketing), conociendo experiencias reales y enfoques prácticos de la puesta en valor del dato. Os dejamos el enlace donde podéis escuchar el podcast de la sesión.
Suelo decir en los cursos que el gran reto que nos queda por resolver es «pintar bien el Big Data«. Con estas palabras semánticamente pobres, lo que trato de decir es que la representación visual del dato no es un tema trivial; y que nos podemos esforzar en hacer un gran proyecto de tratamiento de datos, integración y depuración, etc., que si luego finalmente no lo visualizamos apropiadamente, el usuario puede no estar completamente satisfecho con ello. Por ello, he querido dedicar este artículo para hablar del área del Visual Analytics o visualización analítica e inteligente de datos.
Antoine de Saint-Exupery, autor de “El principito”, dijo eso de “La perfección se alcanza no cuando no hay nada más que añadir, sino cuando no hay nada más que quitar”. Es decir, un enfoque minimalista. Y es que la visualización de información es una mezcla entre narrativa, diseño y estadística. Estos tres campos tienen que ir inexorablemente unidos para no correr el peligro de perderse con la interpretación de la idea a través de estímulos visuales. Las buenas representaciones gráficas, deben cumplir una serie de características:
Señalar relaciones, tendencias o patrones
Explorar datos para inferir nuevo conocimiento
Facilitar el entendimiento de un concepto, idea o hecho
Permitir la observación de una realidad desde diferentes puntos de vista
Y permitir recordar una idea.
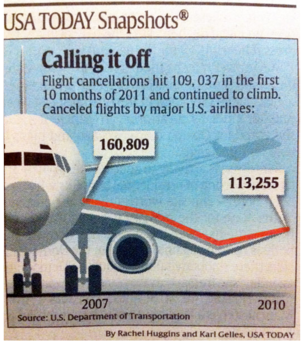
Estos serán nuestros cinco objetivos cuando representamos algo en una gráfica o representación visual. A partir de hoy, nuestras cinco obsesiones cuando vayamos a representar una idea o relación de manera gráfica. ¿Cumplen estas características tus visualizaciones de datos e información? La puesta en valor del dato, como ven, no es algo trivial. Para prueba, un caso, cogido medianamente al azar:
Cancelaciones de aviones desde 2007 a 2010 (Fuente: USA TODAY)
¿Problemas? En primer lugar, ¿qué quiere señalar? Si es una relación, tendencia o patrón, ¿no debería darnos más idea de si los números son relevantes o no? ¿qué significan? ¿cómo me afectan? No facilita entender un concepto, sino que introduce varias dimensiones (tiempo, cancelaciones de vuelos, variación de la tendencia, etc.). Y, encima, lo hace representándolo sobre el ala de un avión. ¿Quiere transmitir seguridad o inseguridad? Genera dudas. Hubiera sido esto más simple si fuera como una cebolla con una única capa: una idea, una relación, un concepto clave. No hace falta más.
La representación visual es una forma de expresión más. Como las matemáticas, la música o la escritura, tiene una serie de reglas que respetar. Hoy en día, en que la cantidad de datos y la tecnología ya no son un problema, el reto para las empresas recae en conocer los conceptos básicos de representación visual. Es lo que se ha venido a conocer como la ciencia del Visual Analytics, definida como la ciencia del razonamiento analítico facilitado a través de interfaces visuales interactivas. De ahí que hoy en día los medios de comunicación utilicen cada vez estas representaciones gráficas de datos e información con las que podemos interactuar.
El uso de representaciones visuales e interactivas de elementos abstractos permite ampliar y mejorar el procesamiento cognitivo. Por lo tanto, para transladar ideas y relaciones, ayuda mucho disponer de una gráfica interactiva. Hay muchos teóricos y autores que se han dedicado a generar teoría y práctica en este campo de la representación visual de información. De hecho, la historia de la visualización no es algo realmente nuevo. En el Siglo XVII, ya destacaron autores como Joseph Priestley y William Playfair. Más tarde, en el Siglo XIX, podemos citar a John Snow, Charles J. Minard y F. Nightingale como los más relevantes (destacando especialmente el primero, que a través de una representación geográfica logró contener una plaga de cólera en Londres). Ya en el Siglo XX, Jacques Bertin, John Tukey, Edward Tufte y Leland Wilkinson son los autores más citados en lo que a visualización y representación de la información se refiere.
Representación gráfica del brote de cólera de John Snow: nacen así, los Sistemas de Información Geográfica o SIG (Fuente: http://blog.rtwilson.com/john-snows-cholera-data-in-more-formats/)
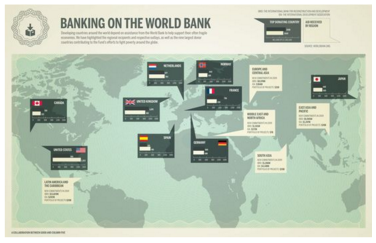
Tufte es quizás el autor más citado. Su libro “The Visual Display of Quantitative Information”, una biblia para los equipos de visualización eficientes y rigurosas. De hecho, los principios de Tufte, los podemos resumir en la integridad gráfica y el diseño estético. Siempre destaca cómo los atributos más importantes el color, el tamaño, la orientación y el lugar de la página donde presentamos una gráfica. Y es que, por mucho que nos sorprenda o por simple que nos parezca, la codificación del valor (datos univariados, bivariados o multivariados) y la codificación de la relación de valores (líneas, mapas, diagramas, etc.), no es un asunto trivial. Un ejemplo de esto sería la siguiente gráfica:
Banking the World Bank (Fuente: http://blogs.elpais.com/.a/6a00d8341bfb1653ef0153903125d9970b-550wi)
Si cogemos el gráfico anterior y yo os hago preguntas relacionadas con la identificación del mayor donante o el mayor receptor, ustedes tendrían problemas. Quizás con un patrón de color esto se hubiera resuelto. Pero ni con esas. Un mapa no es la mejora manera de representar este tipo de datos (y hoy en día se abusa mucho de los mapas). Si quiero responder a las preguntas anteriores, tengo que realizar una búsqueda de las cifras, memorizarlas y luego compararlas. Lo dicho al comienzo; una idea, un patrón, una relación, y luego, búsqueda de la mejor gráfica para ello. Por eso los gráficos de tarta… mejor dejarlos para el postre 😉 (los humanos no somos especialmente hábiles comparando trozos de un círculo cuando hablamos de áreas… que es lo que propone un gráfico de tarta con los trocitos en los que descomponemos un círculo)
Quizás la referencia más importante de todo esto que estamos hablando se encuentre en el artículo que en 1985 escribieron Cleveland y McGill, titulado “Ranking of elementary perceptual tasks”. Dos investigadores de AT&T Bell Labs, William S. Cleveland y Robert McGill, publicaron este artículo central en el Journal of the American Statistical Association. Propone una guía con las representaciones visuales más apropiadas en función del objetivo de cada gráfico, lo cual nos ofrece otro pequeño manual para ayudarnos a representar la información de manera inteligente y eficiente.
“A graphical form that involves elementary perceptual tasks that lead to more accurate judgements than another graphical form (with the same quantitative information) will result in a better organization and increase the chances of a correct perception of patterns and behavior.” (William S. Cleveland y Robert McGill, 1985)
Dicho todo esto, y con la aparición del Big Data, muchos autores comenzaron a trabajar en crear metodologías eficientes para la visualización de información. Lo que hemos denominado al comienzo como Visual Analytics: la visualización analítica, eficiente e inteligente de datos que ayuda a aumentar el entendimiento e interpretación de una idea, una relación, un patrón, etc.
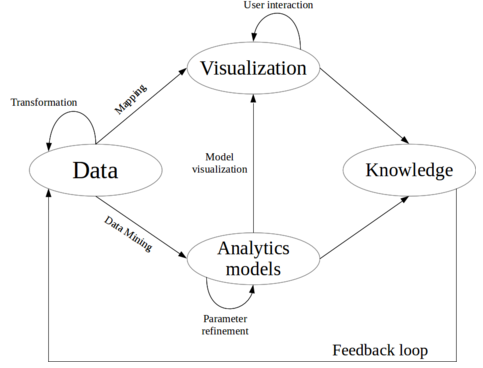
En nuestro Programa de Big Data y Business Intelligence, celebraremos próximamente una sesión en la que precisamente hablaremos de todo esto. Cómo seguir una serie de pasos y criterios a considerar para ayudar al lector, al usuario, a entender y pensar mejor. Un campo que se nutre de los conocimientos del área de Human-Computer-Interaction (HCI) y de la visualización de información. Y, como muestro en la siguiente figura (un proceso de Visual Analytics basado en trabajos de Daniel Keim y otros), aplicaremos un método para pasar del dato al conocimiento, a través de los modelos analíticos y la visualización de información que no confunda, y como decía Saint-Exupery, simplifique.
Proceso de Visual Analytics (Fuente: elaboración propia)
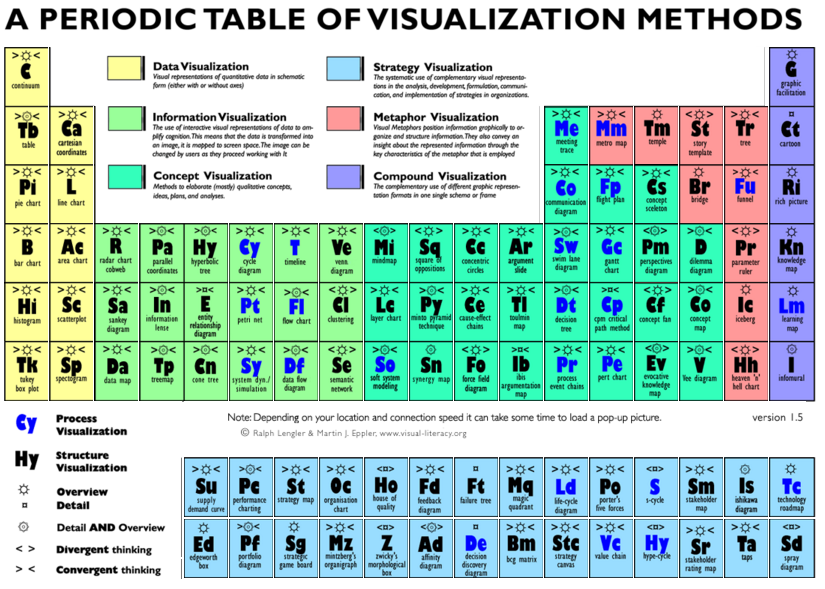
¿Cuál será el resultado de esta sesión? Un dashboard, un informe, un panel de mando de KPIs bien diseñado y elaborado. Es decir, conocimiento eficiente e inteligente para ayudar a las organizaciones a tomar decisiones apoyándose en gráficos bien elaborados. Un dashboard que cumpla con nuestros cinco principios y que permita al estudiante llevarse su tabla periódica de los métodos de visualización eficiente.
Tabla periódica de los métodos de visualización (Fuente: http://www.visual-literacy.org/periodic_table/periodic_table.html)
Asistimos en estos últimos años a una gran revolución silenciosa en el ámbito tecnológico: Internet de las cosas, aplicaciones móviles, smart cities, big data, etc. Son temas que están a diario en los blogs y publicaciones digitales, y también en boca de los profesionales. Y en mi opinión el gran desconocido en toda esta evolución es el asesor jurídico del proyecto.
Siempre que un tecnólogo, informático o emprendedor en general oye la mención al asesoramiento jurídico huye como de ello como de la pólvora. Sin embargo, es la clave para que un proyecto tecnológico salga adelante o no.
El problema es encontrar a alguien que aporte al proyecto una visión facilitadora, que provoque que el proyecto avance pero que al mismo tiempo consiga que el proyecto no se salga de los raíles de lo legalmente permitido.
Si no conseguimos este equilibrio, el resultado siempre será malo, y pueden darse dos casos de fracaso: No tengo en cuenta el asesoramiento, hasta el final del proyecto, y por lo tanto, si no estoy cumpliendo los requisitos legales, el proyecto puede quedar paralizado por este incumplimiento; o lo tengo en cuenta, pero no es el asesoramiento adecuado, y consigue paralizar o hacer inútil el proyecto.
Este equilibrio es la clave. Actualmente existen metodologías innovadoras que permitirán que los proyectos tecnológicos, bien asesorados, avancen y sean exitosos, el secreto es saber implementarlas y utilizarlas adecuadamente, y siempre con la perspectiva de que el proyecto tenga una buena orientación .
Sin embargo, y en el momento en que nos encontramos debemos mantener una doble perspectiva: debemos cumplir en lo sustancial la normativa en vigor (Ley Orgánica de Protección de Datos y Reglamento de desarrollo), pero al mismo tiempo debemos enfocar la nueva normativa, insertando estos principios en los proyectos innovadoras. Las herramientas por lo tanto deben de ser dobles, y adaptadas permanentemente.
Y ello sin olvidar las modificaciones que introducirá el Reglamento Europeo de Protección de Datos una vez que sea aprobado, el cual previsiblemente introducirá la obligación de realizar evaluaciones en todos los procesos en los que haya tratamiento masivo de datos personales, lo que, de aquí en adelante, será lo habitual.
Como conclusión, un panorama que reivindica el papel del experto en Derecho en este mundo tecnológico y reivindica además una visión jurídica estricta de este problema. Y en todo ello, destaca la protección de datos como elemento a cuidar y respetar.
El proceso de Extracción (E), Transformación (T) y Carga (L, de Load en Inglés) -ETL- consume entre el 60% y el 80% del tiempo de un proyecto de Business Intelligence. Suelo empezar con este dato siempre a hablar de las herramientas ETL por la importancia que tienen dentro de cualquier proyecto de manejo de datos. Tal es así, que podemos afirmar que proceso clave en la vida de todo proyecto y que por lo tanto debemos conocer. Y éste es el objetivo de este artículo.
La cadena de valor de un proyecto de Business Intelligence la podemos representar de la siguiente manera:
Cadena de valor de un proyecto de BI (Fuente: http://www.intechopen.com/books/supply-chain-management-new-perspectives/intelligent-value-chain-networks-business-intelligence-and-other-ict-tools-and-technologies-in-suppl)
Hecha la representación gráfica, es entendible ya el valor que aporta una herramienta ETL. Como vemos, es la recoge todos los datos de las diferentes fuentes de datos (un ERP, CRM, hojas de cálculo sueltas, una base de datos SQL, un archivo JSON de una BBDD NoSQL orientada a documentos, etc.), y ejecuta las siguientes acciones (principales, y entre otras):
Validar los datos
Limpiar los datos
Transformar los datos
Agregar los datos
Cargar los datos
Esto, tradiocionalmente se ha venido realizando con código a medida. Lo que se puede entender, ha traído muchos problemas desde la óptica del mantenimiento de dicho código y la colaboración dentro de un equipo de trabajo. Lo que vamos a ver en este artículo es la importancia de estas acciones y qué significan. Por resumirlo mucho, un proceso de datos cualquiera comienza en el origen de datos, continúa con la intervención de una herramienta ETL, y concluye en el destino de los datos que posteriormente va a ser explotada, representada en pantalla, etc.
¿Y por qué la importancia de una herramienta ETL? Básicamente, ejecutamos las acciones de validar, limpiar, transformar, etc. datos para minimizar los fallos que en etapas posteriores del proceso de datos pudieran darse (existencia de campos o valores nulos, tablas de referencia inexistentes, caídas del suministro eléctrico, etc.).
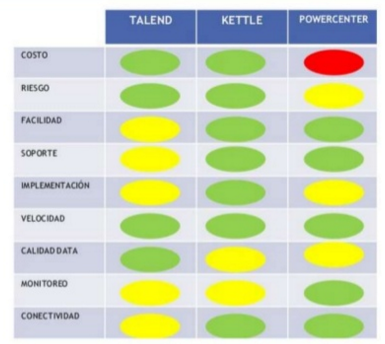
Este parte del proceso consume una parte significativa de todo el proceso (como decíamos al comienzo), por ello requiere recursos, estrategia, habilidades especializadas y tecnologías. Y aquí es donde necesitamos una herramienta ETL que nos ayude en todo ello. ¿Y qué herramientas ETL tenemos a nuestra disposición? Pues desde los fabricantes habituales (SAS, Informatica, SAP, Talend, Information Builders, IBM, Oracle, Microsoft, etc.), hasta herramientas con un coste menor (e incluso abiertas) como Pentaho Kettle, Talend y RapidMiner. En nuestro Programa de Big Data y Business Intelligence, utilizamos mucho tanto SAS como Pentaho Kettle (especialmente esta última), por lo que ayuda a los estudiantes a integrar, depurar la calidad, etc. de los datos que disponen. A continuación os dejamos una comparación entre herramientas:
Comparación Talend vs. Pentaho Kettle
¿Y qué hacemos con el proceso y las herramientas ETL en nuestro programa? Varias acciones, para hacer conscientes al estudiante sobre lo que puede aportar estas herramientas a sus proyectos. A continuación destacamos 5 subprocesos, que son los que se ejecutarían dentro de la herramienta:
Extracción: recuperación de los datos físicamente de las distintas fuentes de información. Probamos a extrar desde una base de datos de un ERP, CRM, etc., hasta una hoja de cálculo, una BBDD documental como un JSOn, etc. En este momento disponemos de los datos en bruto. ¿Problemas que nos podemos encontrar al acceder a los datos para extraerlos? Básicamente se refieren a que provienen de distintas fuentes (la V de Variedad), BBDD, plataformas tecnológicas, protocolos de comunicaciones, juegos de caracteres y tipos de datos.
Limpieza: recuperación de los datos en bruto, para, posteriormente: comprobar su calidad, eliminar los duplicados y, cuando es posible, corrige los valores erróneos y completar los valores vacíos. Es decir se transforman los datos -siempre que sea posible- para reducir los errores de carga. En este momento disponemos de datos limpios y de alta calidad. ¿Problemas?ausencia de valores, campos que tienen distintas utilidades, valores crípticos, vulneración de las reglas de negocio, identificadores que no son únicos, etc. La limpieza de datos, en consecuencia, se divide en distintas etapas, que debemos trabajar para dejar los datos bien trabajados y limpios.
Depurar los valores (parsing)
Corregir (correcting)
Estandarizar (standardizing)
Relacionar (matching)
Consolidar (consolidating)
Transformación: este proceso recupera los datos limpios y de alta calidad y los estructura y resume en los distintos modelos de análisis. El resultado de este proceso es la obtención de datos limpios, consistentes y útiles. La transformación de los datos se hace partiendo de los datos una vez “limpios” (la etapa 2 de este proceso)(. Transformamos los datos de acuerdo con las reglas de negocio y los estándares que han sido establecidos por el equipo de trabajo. La transformación incluye: cambios de formato, sustitución de códigos, valores derivados y agregados, etc.
Integración: Este proceso valida que los datos que cargamos en el datawarehouse o la BBDD de destino (antes de pasar a su procesamiento) son consistentes con las definiciones y formatos del datawarehouse; los integra en los distintos modelos de las distintas áreas de negocio que hemos definido en el mismo.
Actualización: Este proceso es el que nos permite añadir los nuevos datos al datawarehouse o base de datos de destino.
Para concluir este artículo, os dejamos la presentación de una de las sesiones de nuestro Programa de Big Data y Business Intelligence. En esta sesión, hablamos de los competidores y productos de mercado ETL.
En nuestro workshop del pasado 27 de Octubre, también estuvo como ponente Jesús Barrasa, Field Engineer de Neo Technology. Básicamente, el objetivo de su ponencia fue contarnos cómo poder prevenir el fraude a través de la modelización de la información en grafos. Este formalización matemática, que ha ganado bastante popularidad en los últimos años, permite una expresividad de información tan alta, que para muchas aplicaciones donde el descubrimiento de la información es crítica (como es el evitar el fraude), puede ser vital.
Pero, empecemos por lo básico. Jesús, nos describió lo que es un grafo. Un conjunto de vértices (o nodos), que están unidos por arcos o aristas. De este modo, tenemos una información representada a través de relaciones binarias entre el conjunto de elementos. Fue Leonhard Euler, matemático suizo, el inventor de la teoría de grafos en 1736. Por lo tanto, no estamos hablando de un instrumento matemático nuevo.
Un grafo, como conjunto de vértices y arcos (Fuente: https://www.flickr.com/photos/thefangmonster/352461415/in/photolist-x9suX-fDVc6-88T8hQ-7X9u8d-afsXkh-i6KLs-6PpBb6-836Ttv-85z1hy-rA46-rjfq-5RTzeU-bDcg8x-f5s1g3-a1Jv37-bsDVCK-7i62o-5WbpbF-i6LKS-aRBH8x-5RPjSa-h1Xkr2-4d5ypn-DifCQ-7SGo1D-9C4Y3c-noNEE9-7noTPo-7dYzTc-7dYzxZ-d672zw-99Z1f9-bz2Y9P-bquhCW-881tVy-4vn6sS-7Zebpn-4t7P4n-bdYG1z-ePUf2-aVcE68-f7Tsq-7JdUAY-bmhmrn-e2KEC6-63bkHm-e8zMaZ-88V6bY-9ZjTax-7SGo6Z)
Pues bien, este tipo de representación de información (en grafos) es el tipo de bases de datos que más está ganando en popularidad en los últimos años (consultar datos aquí). Su uso en aplicaciones como las redes sociales (y todo lo que tiene que ver con el Análisis de Redes Sociales o Social Network Analysis), el análisis de impacto en redes de telecomunicaciones, sistemas de recomendación (como los de Amazon), logística (y la optimización de los puntos de entrega -vértices- a través de la distancia entre puntos – longitud de las aristas -), etc., son solo algunos ejemplos de la potencia que tiene la representación de la información en grafos.
Jesús nos introdujo un caso concreto que desde Neo Technology han trabajado para la detección y prevención del fraude. Un contexto de aplicación, que además de tener cierta sensibilidad social en los últimos años, no solo es aplicable al ámbito económico, sino también a muchos otros donde el fraude ha sido recurrente y muy difícil de detectar. El problema hasta la fecha es que los límites del modelo relacional de bases de datos (el que ha imperado hasta la fecha) han traído siempre una serie de asuntos que complicaban la detección:
Complejidad al modelizar relaciones (por asuntos como la integridad relacional, etc.)
Degradación del rendimiento al aumentar el número de asociaciones y con el volumen de datos
Complejidad de las consultas
La necesidad de rediseñar el esquema de datos cuando se introducen nuevas asociaciones y tipos de datos
etc.
Estos puntos (entre otros), hacen que las bases de datos relacionales tradicionales resulten hoy en día inadecuadas cuando las asociaciones entre puntos de datos son útiles y valiosas en tiempo real. Y aquí es donde las bases de datos NoSQL (orientadas a documentos, las columnares, las de grafos, etc.), son bastante útiles para soliviantar este problema.
Introducida esta necesidad por las bases de datos de grafos, Jesús nos contó el caso concreto de los defraudadores. Personas que solicitan líneas de crédito, actúan de manera aparentemente normal, extienden el crédito y de repente desaparecen. De hecho, decenas de miles de millones de dólares son defraudados al año solo a bancos estadounidenses. 25% del total de créditos personales son amortizados como pérdidas. Para prevenir esto, la modelización de los datos como grafos puede ayudar.
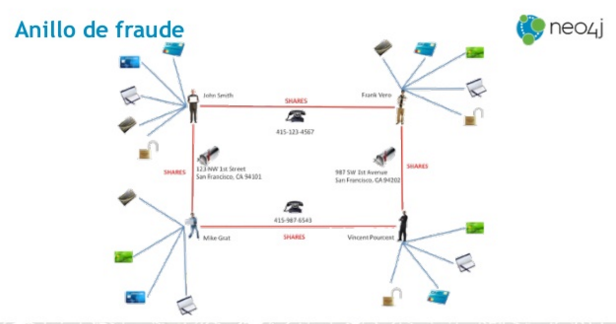
¿Qué es lo que se representa como un grafo? ¿Qué datos/información? Lo que Jesús denominó los anillos de fraude (que podéis encontrar en la imagen debajo de estas líneas). Acciones que va realizando un usuario, y que como son representadas a través de relaciones, permite no solo detectar el fraude, sino también minimizar pérdidas y prevenirlo en la medida de lo posible a través de cadenas de conexión sospechosas.
Anillo de fraude (Fuente: Neo Technology)
Como siempre, os dejamos al final de este artículo las diapositivas empleadas por Jesús. Otro caso más de aplicación del Big Data y de mejora de las sociedades, empresas e instituciones a través de la puesta en valor de los datos. En este caso, los grafos.
En el workshop que organizamos el pasado 27 de Octubre, también participó CIMUBISA, entidad municipal del Ayuntamiento de Bilbao. Básicamente, nos habló sobre la formulación estratégica de ciudad que tenía Bilbao, y cómo el Big Data impactaba sobre ella.
CIMUBISA expuso la formulación estratégica de ciudad que tiene Bilbao. Una estrategia que gira en torno a 5 ejes de actuación:
Administración 4.0
Tecnologías en el espacio urbano
Ciudadanía digital y calidad de vida
Desarrollo económico inteligente
Gobernanza
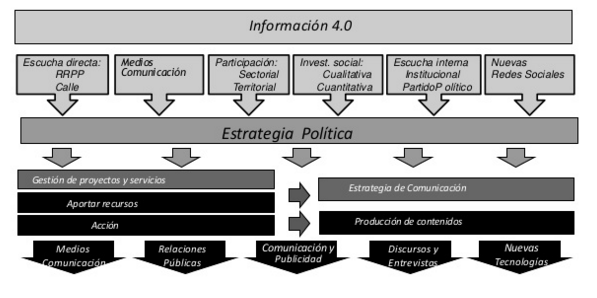
Y en esta estrategia, el dato, la información, resultan clave para ayudar a decidir. No podemos construir una administración inteligente sin una información de calidad para tomar decisiones que beneficien a la sociedad en su conjunto. Prueba de ello es la representación esquemática que se muestra a continuación, en la que la estrategia política, se artícula en torno a diferentes fuentes de información, que la estrategia «Smart City Bilbao» procesa y pone en valor. Fuentes como la escucha directa en la calle, lo que los medios de comunicación señalan sobre la ciudad, lo que se obtiene del fomento de la participación, investigaciones cuantitativas y cualitativas, escucha institucional interna, redes sociales, etc.
La información para decidir, estrategia de Smart Bilbao (Fuente: http://www.slideshare.net/deusto/smart-bilbao-los-datos-al-servicio-de-la-ciudad-big-data-open-data-etc)
¿Y con todos estos datos recogidos que se hace en Bilbao? Un análisis descriptivo, predictivo y prescriptivo. Es decir, técnicas de data mining para extraer más información aún de los datos ya capturados. Un carácter descriptivo para saber lo que pasa en Bilbao; un carácter predictivo para simular lo que pudiera pasar en Bilbao cuando se den unos valores en una serie de variables; y un carácter prescriptivo para recomendar a Bilbao en qué parámetros se ha de incidir para mejorar la gestión y la administración en aras de maximizar el bienestar del ciudadano.
En última instancia, esos datos capturados y tratados con carácter descriptivo, predictivo y prescriptivo, es visualizado. ¿De qué manera? Gráficos, tablas, dashboards, mapas de calor, etc., en áreas como la movilidad y el tráfico, la seguridad y emergencias, la gestión de residuos, eficiencia energética, etc.
Mapas para la visualización de datos de la ciudad de Bilbao (Fuente: http://www.slideshare.net/deusto/smart-bilbao-los-datos-al-servicio-de-la-ciudad-big-data-open-data-etc)
Por último, nos hablaron del proyecto Big Bilbao, un nuevo concurso que aspira a posicionar a Bilbao en el mapa en esto del Big Data. Un proyecto transformador de inteligencia de ciudad. El principal objetivo de este proyecto es crear una plataforma que permita explotar datos de distintas fuentes, estructurados y no estructurados, que permitan mejorar la eficiencia de la gestión de la ciudad. Es decir, una smart city con funcionalidades avanzadas y de altas prestaciones.
La sociedad se ha tecnificado, y cada vez estamos más interconectados. A eso unámosle que el coste computacional es cada vez menor, y cada vez se están digitalizando más procesos y actividades de nuestro día a día. Esto, claro está, representa una oportunidad para las organizaciones, empresas y personas que quieran tratar y analizar los datos en tiemporeal (Real-Time Analytics). Se puede obtener así valor para la toma de decisiones o para sus clientes: ayudar a las empresas a vender más (detectando patrones de compra, por ejemplo), a optimizar costes (detectando cuellos de botella o introduciendo mecanismos de prevención), a encontrar más clientes (por patrones de comportamiento), a detectar puntos de mejora en procesos (por regularidades empíricas de mal funcionamiento) y un largo etcétera.
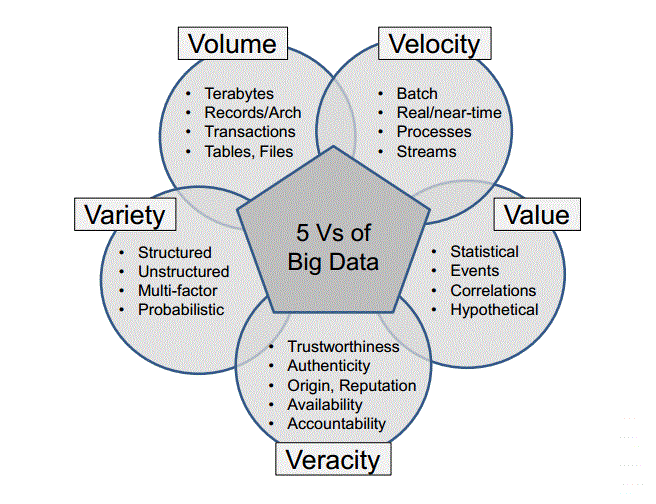
Tres sectores que se están aprovechando enormemente de las posibilidades que el BigData trae son el financiero, el área de marketing y el sector sanitario. Se trata de sectores con sus diferentes particularidades (regulación, servicio público, etc.), pero donde los datos son generados a gran velocidad, en grandes volúmenes, con una gran variedad, donde la veracidad es crítico y donde queremos generar valor. Las 5 “V”s del Big Data al servicio de la mejora de organizaciones de dichos sectores.
Las 5 «V»s del Big Data: Volumen, Velocidad, Valor, Veracidad y Variedad (Fuente: https://www.emaze.com/@AOTTTQLO/Big-data-Analytics-for-Security-Intelligence)
El próximo 3 de Noviembre a las 18:30, el Director del Programa de Big Data y Business Intelligence, Alex Rayón, entrevistará a través de un webinar a tres expertos profesionales en cada uno de los tres sectores citados: Pedro Gómez (profesional del ámbito financiero), Joseba Díaz (profesional con experiencia en proyectos sanitarios y profesional Big Data en HP) y Jon Goikoetxea(Director de Comunicación y Marketing del Grupo Noticias y el diario Deia y alumno de la primera edición delPrograma Big Data y Business Intelligence).
Inscríbete, y en pocos días recibirás instrucciones para unirte al Webinar. El enlace para la inscripción lo podéis encontrar aquí. Y si conoces a alguien que pueda interesarle esta información, reenvíasela 😉
Agradecemos, como siempre, el apoyo a nuestros patrocinadores HP, SAS y Entelgy.
Hoy venimos a hablar de las ciudades inteligentes o Smart Cities, y su relación con el mundo de los datos en general, y el Big Data en particular. El término «Smart City» ha venido a bautizar un concepto, todavía muy dominado por el marketing y la industria, pero que con la urbanización constante (se espera que para 2050 el 86% de la población de los países desarrollados y el 64% de los que están en vías de desarrollo) y la mayor penetración tecnológica (y sus datos asociados), será cada vez más familiar para todos nosotros.
Las ciudades son complejos sistemas en tiempo real que generan grandes cantidades de datos. Hay diferentes agentes y sistemas que interaccionan, lo cual hace que su gestión sea complicada. Por lo tanto, un uso inteligente de las TIC puede facilitar hacer frente a los retos presentes y futuros.
Una ciudad que hace uso de las TIC para la gestión eficiente de su complejidad y su prestación de servicios (Fuente: https://s-media-cache-ak0.pinimg.com/736x/27/9d/a7/279da792f47931195932654e2f051574.jpg)
Desde una perspectiva tecnológica, en cuanto a lo que puede aportar a las ciudades, se dice que las smart cities aprovechan todo el potencial de los avances tecnológicos y de los datos para ahorrar costes a partir de la eficiencia en la gestión. Los ámbitos en los cuales una ciudad puede adquirir inteligencia son muy amplios, pero pueden resumirse en aquellos aspectos de una gestión que: mejora el transporte, mejora los servicios públicos, eficiencia y sostenibilidad de la energía, del consumo de agua, y del manejo de residuos; garantizar seguridad pública, acceso a la información pública y transparencia, etc. Por lo tanto es un concepto multidimensional que hace referencia a muchos conceptos asociados y que recurrentemente aparecen de la mano:
Inteligencia en Medio Ambiente
Inteligencia para la calidad de vida
Ciudadanía Inteligente
Gobierno Inteligente
Inteligencia para la movilidad
Inteligencia Económica
etc.
Es decir, que los datos y sus aplicaciones serán útiles siempre refiréndonos a los procesos que a una administración pública le competen (seguridad ciudadana, medio ambiente, etc.). Este discurso, que desde la tecnología (la industria que antes decíamos) se ha venido impulsando, en realidad se puede traducir en tres fuerzas que movilizan las Smart Cities: Tecnologías de la Información y la Comunicación (TIC), economía, y las personas (sociedad civil). Es decir, las TIC y sus datos asociados, son un elemento; pero sin un incentivo económico (¿qué me puede aportar esto a mí?) y sin una sociedad inclusiva que sea partícipe y se la escuche, una ciudad nunca será inteligente (referiéndose a cómo hemos entendido y bautizado este concepto al inicio).
Para que se entienda lo mucho que puede aportar la digitalización y los datos al día a día de la administración de una ciudad vamos a entender primero qué es un gobierno municipal y en qué consiste su trabajo. En términos muy simplificados, un gobierno municipal elabora planes y programas. Para su elaboración, se suelen emplear necesidades manifestadas o no manifestadas de los ciudadanos, se quiere conocer su opinión, etc. Pero, especialmente, se desea conocer el resultado y el impacto con el fin de poder mejorar constantemente.
Se puede vestir el discurso de las Smart Cities con muchas cosas: Internet of Things, adelantarse en la recogida de basuras, regadíos inteligentes, etc. Pero, al final, una administración debe satisfacer al ciudadano. Eso es lo que resume cualquier aplicación que podamos tener en la cabeza. En este punto es cuando se puede integrar la analítica digital en los planes de un gobierno inteligente. Ofrecer una perspectiva más amplia, a través de datos propios y ajenos, integrando los servicios públicos en sus dimensiones virtuales y presenciales, y todo ello, siendo analizado en tiempo real a través del «Real-Time Analytics» (estrategias analíticas de búsquedas de patrones, inteligencia dependiente del contexto), es lo que el Big Data aporta a una ciudad inteligente.
Para que una ciudad pueda adoptar las posibilidades que el Big Data le brinda, debe acometer una serie de pasos. Un primer punto interesante, es tener una visión única del ciudadano. ¿Tiene tu ciudad un servicio de este tipo? Es decir, ¿sabe mi ayuntamiento que cuando hablo en Twitter soy @alrayon, cuando subo una foto en Instagram soy @alrayon, que cuando les mando un email lo hago con mi cuenta @deusto.es y que cuando me presento en persona uso mi DNI? ¿O para ellos soy cuatro personas/identidades diferentes?
Una vez sabido esto, podemos hacer un análisis del ciudadano. En términos de gestión, para una administración pública, la «transacción«, entendida como elemento de relación mínima, es la solicitud de un servicio. ¿Algún ayuntamiento tiene hecha una comparación entre lo que buscan sus ciudadanos y lo que efectivamente solicitan? ¿Cuál es el ratio de éxito y de satisfacción de los ciudadanos en estos términos? Es decir, ¿qué interesa a mis vecinos? ¿Qué buscan, consultan? ¿Cuándo lo hacen? ¿Desde dónde vienen y hasta dónde llegan? Y, por no hablar, de la cantidad de canales que usarán para ello, y la secuencia entre dichos canales. Esta analítica sobre las peticiones y transacciones podría arrojar mucha información para la elaboración de planes y programas. Esta gran cantidad de datos generados puede ser tratada posteriormente por herramientas de Big Data.
Modelo general de atención al ciudadano (Fuente: gamadero.gob.mx)
Por otro lado. ¿están satisfechos mis ciudadanos? Y ahora ustedes me dirán que vayamos a preguntárselo con unas encuestas. Pero, ¿se han monitorizado las conversacionessociales? Es decir, ¿sabemos de sobre qué y dónde conversan mis vecinos en las redes sociales y otros medios digitales?
Para que todo esto sea posible, necesitamos que nuestras ciudades adopten la la analítica digital. Puede aportar mucho valor tanto en la recogida de datos, como en procesamiento, como en la toma de decisiones final. Las Ciudades Inteligentes requieren de tecnología para la captura de datos y el procesamiento de la información. Y, a partir del conocimiento generado, poder avanzar con la posterior toma de decisiones para el mejoramiento de la ciudad. Vamos a ver y entender estos tres pasos.
En primer lugar, la obtención de datos. Hoy en día, hay muchos datos generándose fuera de los procedimientos habituales de una administración. Una administracióne debe ser consciente que sus canales son ON y OFF. Quizás muchas de ellas no estén ON, pero sus ciudadanos sí lo están. Por lo tanto, un primer paso que debieran conocer es la sincronización de la captura del dato.
En segundo lugar, el procesamiento de datos. Imagínaros que en una determinada quiere abanderar el lema «Ciudad del conocimiento y la cultura» (habrá ya más de una con esto en la cabeza). Dentro de su plan «Fomentando la lectura», un programa puede «Fomentar la lectura en la población juvenil». Supongamos que podemos integrar, como fuentes de datos el impacto que ha tenido una campaña de comunicación que hemos puesto en marcha, unas encuestas, los dartos de préstamos y bibliotecas, la compra de libros en tiendas ON y OFF, etc.
Y un tercer elemento es la toma de decisión final. Aquí, ayuda mucho la puesta en valor del dato a través de los sistemas de visualización y reporting. La inteligencia es la capacidad para anticipar la incertidumbre. Con ella, se logró, por primera vez en la evolución, anteponer el problema a la solución.
Existe ya la norma ISO 37120:2014, que recoge los indicadores para la prestación de servicios en ciudad y la calidad de vida. El Banco Mundial Y Transparencia Internacional también dieron pasos en esa línea. España también. Desde la norma UNE 178301:2015, de Ciudades Inteligentes y Datos Abiertos (Open Data), hasta ciudades que están recorriendo este camino: Bilbao, perimera certificada UNE como Ciudad Inteligente.
¿Y qué tecnologías nos ofrece el Big Data para todo ello?
Tratamiento de información generada «abiertamente» por humanos; es decir, tratamiento de datos no estructurados, que representa una gran cantidad de datos generados en contextos de ciudad.
Tratamiento de imágenes, audios y vídeos: alertas en tiempo real por eventos que pudieran detectarse a través del procesamiento de imágenes, audios o vídeos.
Agrupación de ideas: considerando todas las aportaciones y manifestaciones que nos trasladan los ciudadanos, agrupar por conceptos, términos, ideas, etc. Es decir, clusterizar, para detectar patrones y relaciones.
Análisis de sentimiento: sobre la base de las manifestaciones de los ciudadanos, ¿podemos decir que tenemos una buena impresión entre la ciudadanía?
(y un largo etcétera)
En definitiva, el campo del Big Data al servicio de los ciudadanos, su bienestar y satisfacción. Las ciudades inteligentes del futuro deberán aprovechar estas oportunidades tecnológicas para enriquecerse socialmente y lograr unas sociedades inclusivas y participativas. Un aparato de gestión informacional y del conocimiento sin precedentes. Reaparece en la sociedad la posibilidad de conocer de manera objetiva, neutral y desinterasada la realidad a estudiar (el ciudadano, su bienestar y satisfacción), reflejada ahora en los datos masivos observados a través de una metodología –el Big Data y el uso de algoritmos- capaz de ofrecernos una imagen supuestamente perfecta de la realidad.
Probablemente si estás leyendo este blog tengas un problema analítico que quieras resolver con datos. Es posible también que tengas unos conocimientos de estadística que quieras poner en práctica, así que es hora de elegir una herramienta analítica. Así que vamos a intentar orientaros en la elección, aunque las tres herramientas de analítica nos van a permitir hacer en general los mismos análisis:
Conocimientos previos de programación. Si sabes programar y vienes de un entorno web, probablemente Python sea el más fácil de aprender. Es un lenguaje más generalista que los otros dos y solamente tendrás que aprender el uso de las librerías para hacer análisis de datos (Pandas, Numpy, Scipy, etc.). Si no es el caso y lo tuyo no es programar, SAS es más fácil de aprender que R, que es el lenguaje más diferente de los tres, dado su origen académico-estadístico.
Coste de las herramientas. SAS es un software comercial y bastante caro. Además el uso de cada una de sus capacidades se vende por paquetes, así que el coste total como herramienta analítica es muy caro. La parte buena es que tienes un soporte. Por el contrario, tanto R como Python son gratuitos, si bien es cierto que empresas como Revolution Analytics ofrecen soporte, formación y su propia distribución de R con un coste bastante inferior a SAS. Normalmente sólo las grandes empresas (bancos, compañías telefónicas, cadenas de alimentación, INE, etc.) disponen de SAS debido a su coste.
Estabilidad de la herramienta. Al ser un software comercial, en SAS no hay problemas de compatibilidad de versiones. R al tener un origen académico ofrece distintas librerías para hacer un mismo trabajo y no todas funcionan en versiones anteriores de R. Para evitar estos problemas en una gran empresa recomendaría utilizar alguna distribución comercial de Revolution Analytics por ejemplo.
Volumen de datos. Las única diferencia es que SAS almacena los datos en tu ordenador en vez de en memoria (R), si bien es cierto que las 3 tienen conexiones con Hadoop y las herramientas de Big Data.
Capacidad de innovación. Si necesitas utilizar las últimas técnicas estadísticas o de Machine LearningSAS no es tu amigo. Es un software comercial que para garantizar la estabilidad de uso entre versiones retrasa la incorporación de nuevas técnicas. Aquí el líder es R seguido de Python.
Conclusión: no es fácil quedarse con una herramienta de analítica y las personas que trabajamos en grandes compañías estamos habituados a trabajar con varias. SAS ofrece soluciones integradoras a un coste elevado. R tiene muchas capacidades de innovación debido a su origen y Python tiene la ventaja de ser un lenguaje de programación generalista que además puede servir para hacer Data Mining o Machine Learning. La elección dependerá de lo que estés dispuesto a pagar y tus necesidades específicas. Yo tengo la suerte o desgracia de trabajar en una gran empresa, así que dispongo de las 3.
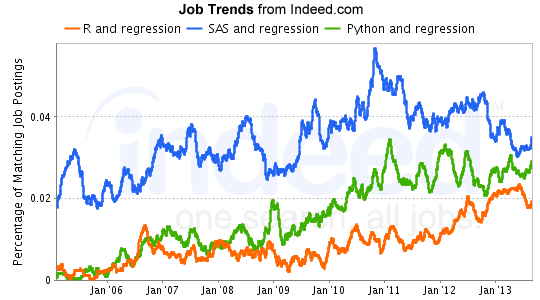
Tendencias en lo que a demanda de perfiles con conocimiento de R, SAS y Python se refiere (Fuente: http://www.statsblogs.com/2013/12/06/sas-is-abandoned-by-the-market-for-advanced-analytics/)