(venimos de una serie de un artículo introductorio a los tres paradigmas, y de uno anterior hablando del paradigma batch)
Decíamos en el artículo anterior, que a la hora de procesar grandes volúmenes de datos existen dos principales enfoques: procesar una gran cantidad de datos por lotes o bien hacerlo, en pequeños fragmentos, y en «tiempo real». Parece, así, bastante intuitivo pensar cuál es la idea del paradigma en tiempo real que trataremos en este artículo.
Este enfoque de procesamiento y análisis de datos se asienta sobre la idea de implementar un modelo de flujo de datos en el que los datos fluyen constantemente a través de una serie de componentes que integran el sistema de Big Data que se esté implatando. Por ello, se le como como procesamiento «streaming» o de flujo. Así, en tiempos muy pequeños, procesamos de manera analítica parte de la totalidad de los datos. Y, con estas características, se superan muchas de las limitaciones del modelo batch.
Por estas características, es importante que no entendamos este paradigma como la solución para analizar un conjunto de grandes datos. Por ello, no presentan esa capacidad, salvo excepciones. Por otro lado, una cosa es denominarlo «tiempo real» y otra es realmente pensar que esto se va a producir en veradero tiempo tiempo. Las limitaciones aparecen por:
- Se debe disponer de suficiente memoria para almacenar entradas de datos en cola. Fíjense en la diferencia con el paradigma batch, donde los procesos de Map y Reduce podrían ser algo lentos, dado que escribían en disco entre las diferentes fases.
- La tasa de productividad del sistema debería ser igual o más rápida a la tasa de entrada de datos. Es decir, que la capacidad de procesamiento del sistema sea más ágil y eficiente que la propia ingesta de datos. Esto, de nuevo, limita bastante la capacidad de dotar de «instantaneidad al sistema».

Uno de los principales objetivos de esta nueva arquitectura es desacoplar el uso que se hacía de Hadoop MapReduce para dar cabida a otros modelos de computación en paralelo como pueden ser:
- MPI (Message Passing Interface): estándar empleado en la programación concurrente para la sincronización de procesos ante la existencia de múltiples procesadores.
- Spark: plataforma desarrollada en Scala para el análisis avanzado y eficiente frente a las limitaciones de Hadoop. Tiene la habilidad de mantener todo en memoria, lo que le da ratios de hasta 100 veces mayor rapidez frente a MapReduce. Tiene un framework integrado para implementar análisis avanzados. Tanto Cloudera, como Hortonworks, lo utilizan.
Y, con estos nuevos modelos, como hemos visto a lo largo de esta corta pero intensa historia del Big Data, aparecen una serie de tecnologías y herramientas que permiten implementar y dar sentido a todo este funcionamiento:
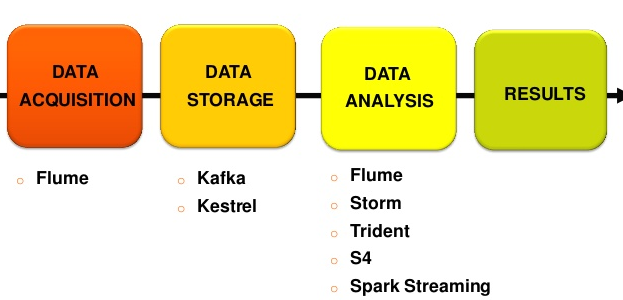
- Flume: herramienta para la ingesta de datos en entornos de tiempo real. Tiene tres componentes principales: Source (fuente de datos), Channel (el canal por el que se tratarán los datos) y Sink (persistencia de los datos). Para entornos de exigencias en términos de velocidad de respuesta, es una muy buena alternativa a herramientas ETL tradicionales.

- Kafka: sistema de almacenamiento distribuido y replicado. Muy rápido y ágil en lecturas y escrituras. Funciona como un servicio de mensajería y fue creado por Linkedin para responder a sus necesidades (por eso insisto tanto en que nunca estaríamos hablando de «Big Data» sin las herramientas que Internet y sus grandes plataformas ha traído). Unifica procesamiento OFF y ON, por lo que suma las ventajas de ambos sistemas (batch y real time). Funciona como si fuera un cluster.
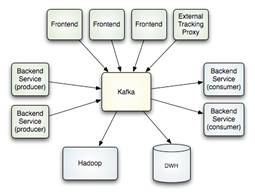
- Storm: sistema de computación distribuido, por lo que se emplea en la etapa de análisis de datos (de la cadena de valor de un proyecto de Big Data). Se define como un sistema de procesamiento de eventos complejos (Complex Event Processing, CEP), lo que le hace ideal para responder a sistemas en los que los datos llegan de manera repentina pero continua. Por ejemplo, en herramientas tan habituales para nosotros como WhatsApp, Facebook o Twitter, así como herramientas como sensores (ante la ocurrencia de un evento) o un servicio financiero que podamos ejecutar en cualquier momento.
Vistas estas tres tecnologías, queda claro que la arquitectura resultante de un proyecto de tiempo real quedaría compuesto por Flume (ingesta de datos de diversas fuentes) –> Kafka (encolamos y almacenamos) –> Storm (analizamos).
Vistas todas estas características, podemos concluir que para proyectos donde el «tamaño» sea el *verdadero* problema, el enfoque Batch será el bueno. Cuando el «problema» sea la velocidad, el enfoque en tiempo real, es la solución a adoptar.
(continuará)