Mucho se ha escrito la que aparentemente va a ser la profesión más sexy del Siglo XXI. Más allá de titulares tan rimbonbantes (digo yo, que quedan muchas cosas todavía que inventar y hacer en este siglo :-), lo que viene a expresar esa idea es la importancia que va a tener un científico de datos en una era de datos ubicuos, coste de almacenamiento, procesamiento y transporte prácticamente cero y de constante digitalización. La práctica moderna del análisis de datos, lo que popularmente y muchas veces erróneamente se conoce como «Big Data», se asienta sobre lo que es la «Ciencia del Dato» o «Data Science».
En 2012, Davenport y Patil escribían un influyente artículo en la Harvard Business Review en la que exponían que el científico de datos era la profesión más sexy del Siglo XXI. Un profesional que combinando conocimientos de matemáticas, estadística y programación, se encarga de analizar los grandes volúmenes de datos. A diferencia de la estadística tradicional que utilizaba muestras, el científico de datos aplica sus conocimientos estadísticos para resolver problemas de negocio aplicando las nuevas tecnologías, que permiten realizar cálculos que hasta ahora no se podían realizar.
Y va ganando en popularidad en los últimos años debido sobre todo al desarrollo de la parte más tecnológica. Las tecnologías de Big Data empiezan a posibilitar que las empresas las adopten y empiecen a poner en valor el análisis de datos en su día a día. Pero, ahí, es cuando se dan cuenta que necesitan algo más que tecnología. La estadística para la construcción de modelos analíticos, las matemáticas para la formulación de los problemas y su expresión codificada para las máquinas, y, el conocimiento de dominio (saber del área funcional de la empresa que lo quiere adoptar, el sector de actividad económica, etc. etc.), se tornan igualmente fundamentales.
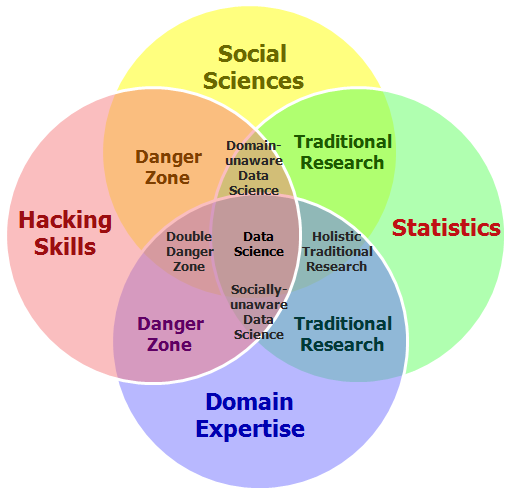
Pero, si esto es tan sexy ¿qué hace el científico de datos? Y sobre todo, ¿qué tiene que ver esto con el Big Data y el Business Intelligence? Para responder a ello, me gusta siempre referenciar en los cursos y conferencias la representación en formato de diagrama de Venn que hizo Drew Conway en 2010:
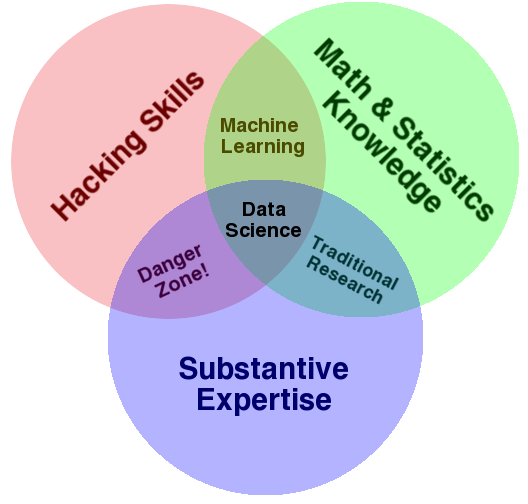
Como se puede apreciar, se trata de una agregación de tres disciplinas que se deben entender bien en este nuevo paradigma que ha traído el Big Data:
- «Hacking skills» o «competencias digitales con pensamiento computacional«: sé que al traducirlo al Español, pierdo mucho del significado de lo que expresa las «Hacking Skills». Pero creo que se entiende bien también lo que quieren decir las «competencias digitales». Estamos en una época en la que constante «algoritmización» de lo que nos rodea, el pensamiento computacional que ya hay países que han metido desde preescolar, haga que las competencias digitales no pasen solo por «saber de Ofimática» o de «sistemas de información». Esto va más de tener ese mirada hacia lo que los ordenadores hacen, cómo procesan datos y cómo los utilizan para obtener conclusiones. Yo a esto lo llamo «Pensamiento computacional», como una (mala) traducción de «Computation thinking», que junto con las competencias digitales (entender lo que hacen las herramientas digitales y ponerlo en práctica), me parecen fundamentales.
- Estadística y matemáticas: en primer lugar, la estadística, que es una herramienta crítica para la resolución de problemas. Nos dota de unos instrumentos de trabajo de enorme valor para los que trabajamos con problemas de la empresa. Y las matemáticas, ay, qué decir de la ciencia formal por antonomasía, la que siguiendo razonamientos lógicos, nos permite estudiar propiedades y relaciones entre las variables que formarán parte de nuestro problema. Si bien las matemáticas se la ha venido a conocer como la ciencia exacta, en la estadística, nos gusta más jugar con intervalos de confianza y la incertidumbre. Pero, por sus propias particularidades, se nutren mutuamente, y hace que para construir modelos analíticos que permitan resolver los problemas que las empresas y organizaciones nos planteen, necesitemos ambas dos.
- Conocimiento del dominio: para poder diseñar y desarrollar la aplicación del análisis masivo de datos a diferentes casos de uso y aplicación, es necesario conocer el contexto. Los problemas se deben plantear acorde a estas características. Como siempre digo, esto del Big Data es más una cuestión de plantar bien los problemas que otra cosa, por lo que saber hacer las preguntas correctas con las personas que bien conocen el dominio de aplicación es fundamental. Por esto me suelo a referir a «que hay tantos proyectos de Big Data como empresas». Cada proyecto es un mundo, por lo que cuando alguien te cuente su proyecto, luego relativízalo a tus necesidades 😉
Estas tres cuestiones (informática y computación, métodos estadísticos y áreas de aplicación/dominio), también fueron citadas por William S. Cleveland en 2001 en su artículo «Data Science: An Action Plan for Expanding the Technical Areas of the Field of Statistics«. Por lo tanto, no es una concepción nueva.
Este Diagrama de Venn ha ido evolucionando mucho. Uno de los que más me gustan es éste, que integra las ciencias sociales. Nuestro Programa Experto en Análisis, Investigación y Comunicación de Datos precisamente busca ese enfoque.