En nuestro workshop del pasado 27 de Octubre, también estuvo como ponente Jesús Barrasa, Field Engineer de Neo Technology. Básicamente, el objetivo de su ponencia fue contarnos cómo poder prevenir el fraude a través de la modelización de la información en grafos. Este formalización matemática, que ha ganado bastante popularidad en los últimos años, permite una expresividad de información tan alta, que para muchas aplicaciones donde el descubrimiento de la información es crítica (como es el evitar el fraude), puede ser vital.
Pero, empecemos por lo básico. Jesús, nos describió lo que es un grafo. Un conjunto de vértices (o nodos), que están unidos por arcos o aristas. De este modo, tenemos una información representada a través de relaciones binarias entre el conjunto de elementos. Fue Leonhard Euler, matemático suizo, el inventor de la teoría de grafos en 1736. Por lo tanto, no estamos hablando de un instrumento matemático nuevo.
Un grafo, como conjunto de vértices y arcos (Fuente: https://www.flickr.com/photos/thefangmonster/352461415/in/photolist-x9suX-fDVc6-88T8hQ-7X9u8d-afsXkh-i6KLs-6PpBb6-836Ttv-85z1hy-rA46-rjfq-5RTzeU-bDcg8x-f5s1g3-a1Jv37-bsDVCK-7i62o-5WbpbF-i6LKS-aRBH8x-5RPjSa-h1Xkr2-4d5ypn-DifCQ-7SGo1D-9C4Y3c-noNEE9-7noTPo-7dYzTc-7dYzxZ-d672zw-99Z1f9-bz2Y9P-bquhCW-881tVy-4vn6sS-7Zebpn-4t7P4n-bdYG1z-ePUf2-aVcE68-f7Tsq-7JdUAY-bmhmrn-e2KEC6-63bkHm-e8zMaZ-88V6bY-9ZjTax-7SGo6Z)
Pues bien, este tipo de representación de información (en grafos) es el tipo de bases de datos que más está ganando en popularidad en los últimos años (consultar datos aquí). Su uso en aplicaciones como las redes sociales (y todo lo que tiene que ver con el Análisis de Redes Sociales o Social Network Analysis), el análisis de impacto en redes de telecomunicaciones, sistemas de recomendación (como los de Amazon), logística (y la optimización de los puntos de entrega -vértices- a través de la distancia entre puntos – longitud de las aristas -), etc., son solo algunos ejemplos de la potencia que tiene la representación de la información en grafos.
Jesús nos introdujo un caso concreto que desde Neo Technology han trabajado para la detección y prevención del fraude. Un contexto de aplicación, que además de tener cierta sensibilidad social en los últimos años, no solo es aplicable al ámbito económico, sino también a muchos otros donde el fraude ha sido recurrente y muy difícil de detectar. El problema hasta la fecha es que los límites del modelo relacional de bases de datos (el que ha imperado hasta la fecha) han traído siempre una serie de asuntos que complicaban la detección:
Complejidad al modelizar relaciones (por asuntos como la integridad relacional, etc.)
Degradación del rendimiento al aumentar el número de asociaciones y con el volumen de datos
Complejidad de las consultas
La necesidad de rediseñar el esquema de datos cuando se introducen nuevas asociaciones y tipos de datos
etc.
Estos puntos (entre otros), hacen que las bases de datos relacionales tradicionales resulten hoy en día inadecuadas cuando las asociaciones entre puntos de datos son útiles y valiosas en tiempo real. Y aquí es donde las bases de datos NoSQL (orientadas a documentos, las columnares, las de grafos, etc.), son bastante útiles para soliviantar este problema.
Introducida esta necesidad por las bases de datos de grafos, Jesús nos contó el caso concreto de los defraudadores. Personas que solicitan líneas de crédito, actúan de manera aparentemente normal, extienden el crédito y de repente desaparecen. De hecho, decenas de miles de millones de dólares son defraudados al año solo a bancos estadounidenses. 25% del total de créditos personales son amortizados como pérdidas. Para prevenir esto, la modelización de los datos como grafos puede ayudar.
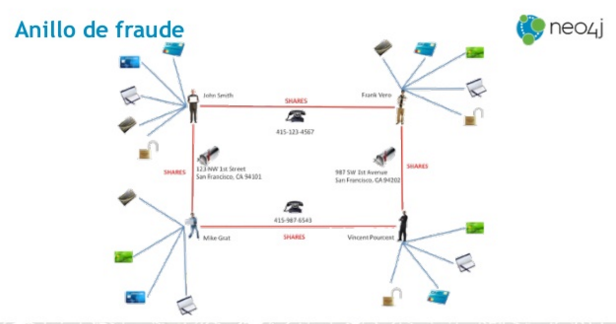
¿Qué es lo que se representa como un grafo? ¿Qué datos/información? Lo que Jesús denominó los anillos de fraude (que podéis encontrar en la imagen debajo de estas líneas). Acciones que va realizando un usuario, y que como son representadas a través de relaciones, permite no solo detectar el fraude, sino también minimizar pérdidas y prevenirlo en la medida de lo posible a través de cadenas de conexión sospechosas.
Anillo de fraude (Fuente: Neo Technology)
Como siempre, os dejamos al final de este artículo las diapositivas empleadas por Jesús. Otro caso más de aplicación del Big Data y de mejora de las sociedades, empresas e instituciones a través de la puesta en valor de los datos. En este caso, los grafos.
En el workshop que organizamos el pasado 27 de Octubre, también participó CIMUBISA, entidad municipal del Ayuntamiento de Bilbao. Básicamente, nos habló sobre la formulación estratégica de ciudad que tenía Bilbao, y cómo el Big Data impactaba sobre ella.
CIMUBISA expuso la formulación estratégica de ciudad que tiene Bilbao. Una estrategia que gira en torno a 5 ejes de actuación:
Administración 4.0
Tecnologías en el espacio urbano
Ciudadanía digital y calidad de vida
Desarrollo económico inteligente
Gobernanza
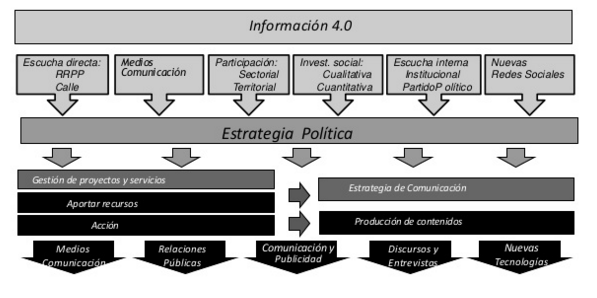
Y en esta estrategia, el dato, la información, resultan clave para ayudar a decidir. No podemos construir una administración inteligente sin una información de calidad para tomar decisiones que beneficien a la sociedad en su conjunto. Prueba de ello es la representación esquemática que se muestra a continuación, en la que la estrategia política, se artícula en torno a diferentes fuentes de información, que la estrategia «Smart City Bilbao» procesa y pone en valor. Fuentes como la escucha directa en la calle, lo que los medios de comunicación señalan sobre la ciudad, lo que se obtiene del fomento de la participación, investigaciones cuantitativas y cualitativas, escucha institucional interna, redes sociales, etc.
La información para decidir, estrategia de Smart Bilbao (Fuente: http://www.slideshare.net/deusto/smart-bilbao-los-datos-al-servicio-de-la-ciudad-big-data-open-data-etc)
¿Y con todos estos datos recogidos que se hace en Bilbao? Un análisis descriptivo, predictivo y prescriptivo. Es decir, técnicas de data mining para extraer más información aún de los datos ya capturados. Un carácter descriptivo para saber lo que pasa en Bilbao; un carácter predictivo para simular lo que pudiera pasar en Bilbao cuando se den unos valores en una serie de variables; y un carácter prescriptivo para recomendar a Bilbao en qué parámetros se ha de incidir para mejorar la gestión y la administración en aras de maximizar el bienestar del ciudadano.
En última instancia, esos datos capturados y tratados con carácter descriptivo, predictivo y prescriptivo, es visualizado. ¿De qué manera? Gráficos, tablas, dashboards, mapas de calor, etc., en áreas como la movilidad y el tráfico, la seguridad y emergencias, la gestión de residuos, eficiencia energética, etc.
Mapas para la visualización de datos de la ciudad de Bilbao (Fuente: http://www.slideshare.net/deusto/smart-bilbao-los-datos-al-servicio-de-la-ciudad-big-data-open-data-etc)
Por último, nos hablaron del proyecto Big Bilbao, un nuevo concurso que aspira a posicionar a Bilbao en el mapa en esto del Big Data. Un proyecto transformador de inteligencia de ciudad. El principal objetivo de este proyecto es crear una plataforma que permita explotar datos de distintas fuentes, estructurados y no estructurados, que permitan mejorar la eficiencia de la gestión de la ciudad. Es decir, una smart city con funcionalidades avanzadas y de altas prestaciones.
El workshop, titulado como «Aplicación del Big Data en sectores económicos estratégicos«, tenía como principal objetivo mostrar la aplicación del Big Data en varios sectores estratégicos para la economía Española (finanzas, sector público, cultura, inversión y turismo). La primera de las intervenciones corrió a cargo de Jorge Monge, de Management Solutions, que nos expuso cómo elaborar un scoring financiero y su relevancia en la era del Big Data.
La revolución tecnológica se produce a magnitudes nunca antes observadas. El sector financiero no es ajeno a ese cambio, conjugando una reestructuración sin precedentes, con un cambio de perfil de usuario muy acusado. Así, se está pasando de la Banca Digital 1.0 a la 4.0, una innovación liderada por el cliente, y donde la analítica omnicanal con datos estructurados y no estructurados se torna fundamental.
La Banca Digital 4.0 (Fuente: Management Solutions)
Las entidades financieras, gracias a esta transformación digital, disponen de gran cantidad de información pública, con la que hacer perfiles detallados no solo a sus clientes actuales, sino también a sus clientes potenciales. Dado que la capacidad de procesamiento se ha visto multiplicado por las nuevas arquitecturas del Big Data, esto tampoco supone un problema. Los modelos de scoring (como el que Jorge expuso) pertenecen al ámbito de riesgos de las entidades bancarias, intentando clasificar a los clientes potenciales en función de su probabilidad de impago. Nos contó un proyecto real en el que con datos anonimizados de una cartera de 72.000 clientes potenciales, se mezclaron datos tradicionales de transacciones, con datos de redes sociales, para conformar un modelo analítico. Éste, conformado por variables significativas de cara a evaluar el incumplimiento, permitía mejorar el poder precitivo del scoring bancario.
El reto actual radica en la gran cantidad de datos. Jorge señaló cómo aunque se genere gran cantidad de información, esta no sería útil si no pudiera procesarse. Sin embargo, la capacidad de procesamiento se ha visto multiplicada por las nuevas arquitecturas de Big Data. Destacó, aquí, Hadoop, Hive, Pig, Mahout, R, Python, etc. Varias de las herramientas que ya comentamos en un post pasado.
Por último, destacaba, que el reto ya no es tecnológico. El reto es poder entender el procesamiento que hacen estas herramientas. Así, ha surgido un nuevo rol multidisciplinar para hacer frente a este problema: el data scientist, que integra conocimientos de tecnología, de programación, de matemáticas, de estadística, de negocio, etc. Hablaremos de este perfil más adelante. Y, cerraba la sesión, destacando la importancia de la calidad de la información, el reto que suponen las variables cualitativas y la desambiguación.
Os dejamos, para finalizar el artículo, la presentación realizada por Jonge Monge. Aprovechamos este artículo para agradecerle nuevamente su participación y aportaciones de valor.
La sociedad se ha tecnificado, y cada vez estamos más interconectados. A eso unámosle que el coste computacional es cada vez menor, y cada vez se están digitalizando más procesos y actividades de nuestro día a día. Esto, claro está, representa una oportunidad para las organizaciones, empresas y personas que quieran tratar y analizar los datos en tiemporeal (Real-Time Analytics). Se puede obtener así valor para la toma de decisiones o para sus clientes: ayudar a las empresas a vender más (detectando patrones de compra, por ejemplo), a optimizar costes (detectando cuellos de botella o introduciendo mecanismos de prevención), a encontrar más clientes (por patrones de comportamiento), a detectar puntos de mejora en procesos (por regularidades empíricas de mal funcionamiento) y un largo etcétera.
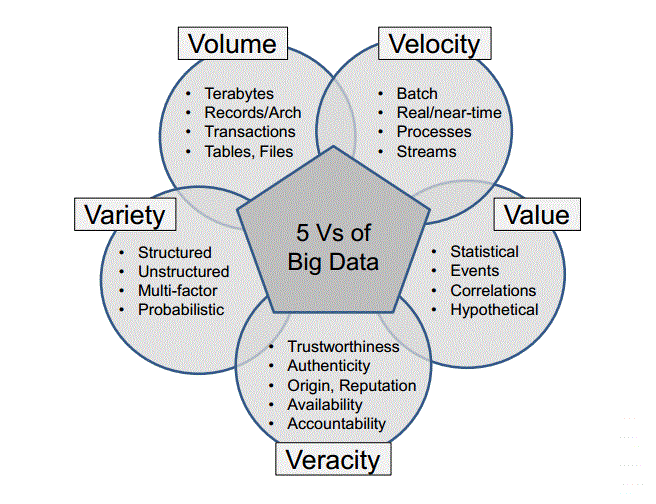
Tres sectores que se están aprovechando enormemente de las posibilidades que el BigData trae son el financiero, el área de marketing y el sector sanitario. Se trata de sectores con sus diferentes particularidades (regulación, servicio público, etc.), pero donde los datos son generados a gran velocidad, en grandes volúmenes, con una gran variedad, donde la veracidad es crítico y donde queremos generar valor. Las 5 “V”s del Big Data al servicio de la mejora de organizaciones de dichos sectores.
Las 5 «V»s del Big Data: Volumen, Velocidad, Valor, Veracidad y Variedad (Fuente: https://www.emaze.com/@AOTTTQLO/Big-data-Analytics-for-Security-Intelligence)
El próximo 3 de Noviembre a las 18:30, el Director del Programa de Big Data y Business Intelligence, Alex Rayón, entrevistará a través de un webinar a tres expertos profesionales en cada uno de los tres sectores citados: Pedro Gómez (profesional del ámbito financiero), Joseba Díaz (profesional con experiencia en proyectos sanitarios y profesional Big Data en HP) y Jon Goikoetxea(Director de Comunicación y Marketing del Grupo Noticias y el diario Deia y alumno de la primera edición delPrograma Big Data y Business Intelligence).
Inscríbete, y en pocos días recibirás instrucciones para unirte al Webinar. El enlace para la inscripción lo podéis encontrar aquí. Y si conoces a alguien que pueda interesarle esta información, reenvíasela 😉
Agradecemos, como siempre, el apoyo a nuestros patrocinadores HP, SAS y Entelgy.
[:es]Estamos empeñados en una misión: propagar una cultura de datos que ponga en manos de la gente herramientas para poder interpretar la realidad de forma certera y útil. ¿Nuestro lema? “Las opiniones son libres, pero los hechos son sagrados”, parafraseando al que fuera gran editor de The Guardian, PC Scott.
Pero que no os confunda el tonillo “periodiquero”. Los datos están en todas partes: en la administración pública, en tu equipo de fútbol, en la lista de proveedores de tu empresa, en las redes sociales, en el internet de las cosas, en la lista de pacientes de una consulta, en la biblioteca municipal, en el AMPA de tu colegio…Los datos están revolucionando nuestras vidas, y en este Programa queremos que sea para mejorarlas y hacerlas más interesantes.
En 2016, tendremos a estrellas de los datos como Mar Cabra y Juanlu Sánchez, periodistas de investigación; el mago de las visualizaciones Alberto Cairo; y el experto en estadística Juanjo Gibaja.
Los y las dateros y dateras del Programa saldrán de él con las herramientas que les permitan extraer, limpiar, analizar y visualizar datos, podrán realizar un proyecto personal o de su organización o empresa, desde su diseño a su implementación, y entrarán a formar parte de una comunidad de profesionales de élite.
No te lo pierdas.[:eu]Bienvenido a WordPress. Esta es tu primera entrada. Edítala o bórrala, ¡y comienza a escribir![:]
Hoy venimos a hablar de las ciudades inteligentes o Smart Cities, y su relación con el mundo de los datos en general, y el Big Data en particular. El término «Smart City» ha venido a bautizar un concepto, todavía muy dominado por el marketing y la industria, pero que con la urbanización constante (se espera que para 2050 el 86% de la población de los países desarrollados y el 64% de los que están en vías de desarrollo) y la mayor penetración tecnológica (y sus datos asociados), será cada vez más familiar para todos nosotros.
Las ciudades son complejos sistemas en tiempo real que generan grandes cantidades de datos. Hay diferentes agentes y sistemas que interaccionan, lo cual hace que su gestión sea complicada. Por lo tanto, un uso inteligente de las TIC puede facilitar hacer frente a los retos presentes y futuros.
Una ciudad que hace uso de las TIC para la gestión eficiente de su complejidad y su prestación de servicios (Fuente: https://s-media-cache-ak0.pinimg.com/736x/27/9d/a7/279da792f47931195932654e2f051574.jpg)
Desde una perspectiva tecnológica, en cuanto a lo que puede aportar a las ciudades, se dice que las smart cities aprovechan todo el potencial de los avances tecnológicos y de los datos para ahorrar costes a partir de la eficiencia en la gestión. Los ámbitos en los cuales una ciudad puede adquirir inteligencia son muy amplios, pero pueden resumirse en aquellos aspectos de una gestión que: mejora el transporte, mejora los servicios públicos, eficiencia y sostenibilidad de la energía, del consumo de agua, y del manejo de residuos; garantizar seguridad pública, acceso a la información pública y transparencia, etc. Por lo tanto es un concepto multidimensional que hace referencia a muchos conceptos asociados y que recurrentemente aparecen de la mano:
Inteligencia en Medio Ambiente
Inteligencia para la calidad de vida
Ciudadanía Inteligente
Gobierno Inteligente
Inteligencia para la movilidad
Inteligencia Económica
etc.
Es decir, que los datos y sus aplicaciones serán útiles siempre refiréndonos a los procesos que a una administración pública le competen (seguridad ciudadana, medio ambiente, etc.). Este discurso, que desde la tecnología (la industria que antes decíamos) se ha venido impulsando, en realidad se puede traducir en tres fuerzas que movilizan las Smart Cities: Tecnologías de la Información y la Comunicación (TIC), economía, y las personas (sociedad civil). Es decir, las TIC y sus datos asociados, son un elemento; pero sin un incentivo económico (¿qué me puede aportar esto a mí?) y sin una sociedad inclusiva que sea partícipe y se la escuche, una ciudad nunca será inteligente (referiéndose a cómo hemos entendido y bautizado este concepto al inicio).
Para que se entienda lo mucho que puede aportar la digitalización y los datos al día a día de la administración de una ciudad vamos a entender primero qué es un gobierno municipal y en qué consiste su trabajo. En términos muy simplificados, un gobierno municipal elabora planes y programas. Para su elaboración, se suelen emplear necesidades manifestadas o no manifestadas de los ciudadanos, se quiere conocer su opinión, etc. Pero, especialmente, se desea conocer el resultado y el impacto con el fin de poder mejorar constantemente.
Se puede vestir el discurso de las Smart Cities con muchas cosas: Internet of Things, adelantarse en la recogida de basuras, regadíos inteligentes, etc. Pero, al final, una administración debe satisfacer al ciudadano. Eso es lo que resume cualquier aplicación que podamos tener en la cabeza. En este punto es cuando se puede integrar la analítica digital en los planes de un gobierno inteligente. Ofrecer una perspectiva más amplia, a través de datos propios y ajenos, integrando los servicios públicos en sus dimensiones virtuales y presenciales, y todo ello, siendo analizado en tiempo real a través del «Real-Time Analytics» (estrategias analíticas de búsquedas de patrones, inteligencia dependiente del contexto), es lo que el Big Data aporta a una ciudad inteligente.
Para que una ciudad pueda adoptar las posibilidades que el Big Data le brinda, debe acometer una serie de pasos. Un primer punto interesante, es tener una visión única del ciudadano. ¿Tiene tu ciudad un servicio de este tipo? Es decir, ¿sabe mi ayuntamiento que cuando hablo en Twitter soy @alrayon, cuando subo una foto en Instagram soy @alrayon, que cuando les mando un email lo hago con mi cuenta @deusto.es y que cuando me presento en persona uso mi DNI? ¿O para ellos soy cuatro personas/identidades diferentes?
Una vez sabido esto, podemos hacer un análisis del ciudadano. En términos de gestión, para una administración pública, la «transacción«, entendida como elemento de relación mínima, es la solicitud de un servicio. ¿Algún ayuntamiento tiene hecha una comparación entre lo que buscan sus ciudadanos y lo que efectivamente solicitan? ¿Cuál es el ratio de éxito y de satisfacción de los ciudadanos en estos términos? Es decir, ¿qué interesa a mis vecinos? ¿Qué buscan, consultan? ¿Cuándo lo hacen? ¿Desde dónde vienen y hasta dónde llegan? Y, por no hablar, de la cantidad de canales que usarán para ello, y la secuencia entre dichos canales. Esta analítica sobre las peticiones y transacciones podría arrojar mucha información para la elaboración de planes y programas. Esta gran cantidad de datos generados puede ser tratada posteriormente por herramientas de Big Data.
Modelo general de atención al ciudadano (Fuente: gamadero.gob.mx)
Por otro lado. ¿están satisfechos mis ciudadanos? Y ahora ustedes me dirán que vayamos a preguntárselo con unas encuestas. Pero, ¿se han monitorizado las conversacionessociales? Es decir, ¿sabemos de sobre qué y dónde conversan mis vecinos en las redes sociales y otros medios digitales?
Para que todo esto sea posible, necesitamos que nuestras ciudades adopten la la analítica digital. Puede aportar mucho valor tanto en la recogida de datos, como en procesamiento, como en la toma de decisiones final. Las Ciudades Inteligentes requieren de tecnología para la captura de datos y el procesamiento de la información. Y, a partir del conocimiento generado, poder avanzar con la posterior toma de decisiones para el mejoramiento de la ciudad. Vamos a ver y entender estos tres pasos.
En primer lugar, la obtención de datos. Hoy en día, hay muchos datos generándose fuera de los procedimientos habituales de una administración. Una administracióne debe ser consciente que sus canales son ON y OFF. Quizás muchas de ellas no estén ON, pero sus ciudadanos sí lo están. Por lo tanto, un primer paso que debieran conocer es la sincronización de la captura del dato.
En segundo lugar, el procesamiento de datos. Imagínaros que en una determinada quiere abanderar el lema «Ciudad del conocimiento y la cultura» (habrá ya más de una con esto en la cabeza). Dentro de su plan «Fomentando la lectura», un programa puede «Fomentar la lectura en la población juvenil». Supongamos que podemos integrar, como fuentes de datos el impacto que ha tenido una campaña de comunicación que hemos puesto en marcha, unas encuestas, los dartos de préstamos y bibliotecas, la compra de libros en tiendas ON y OFF, etc.
Y un tercer elemento es la toma de decisión final. Aquí, ayuda mucho la puesta en valor del dato a través de los sistemas de visualización y reporting. La inteligencia es la capacidad para anticipar la incertidumbre. Con ella, se logró, por primera vez en la evolución, anteponer el problema a la solución.
Existe ya la norma ISO 37120:2014, que recoge los indicadores para la prestación de servicios en ciudad y la calidad de vida. El Banco Mundial Y Transparencia Internacional también dieron pasos en esa línea. España también. Desde la norma UNE 178301:2015, de Ciudades Inteligentes y Datos Abiertos (Open Data), hasta ciudades que están recorriendo este camino: Bilbao, perimera certificada UNE como Ciudad Inteligente.
¿Y qué tecnologías nos ofrece el Big Data para todo ello?
Tratamiento de información generada «abiertamente» por humanos; es decir, tratamiento de datos no estructurados, que representa una gran cantidad de datos generados en contextos de ciudad.
Tratamiento de imágenes, audios y vídeos: alertas en tiempo real por eventos que pudieran detectarse a través del procesamiento de imágenes, audios o vídeos.
Agrupación de ideas: considerando todas las aportaciones y manifestaciones que nos trasladan los ciudadanos, agrupar por conceptos, términos, ideas, etc. Es decir, clusterizar, para detectar patrones y relaciones.
Análisis de sentimiento: sobre la base de las manifestaciones de los ciudadanos, ¿podemos decir que tenemos una buena impresión entre la ciudadanía?
(y un largo etcétera)
En definitiva, el campo del Big Data al servicio de los ciudadanos, su bienestar y satisfacción. Las ciudades inteligentes del futuro deberán aprovechar estas oportunidades tecnológicas para enriquecerse socialmente y lograr unas sociedades inclusivas y participativas. Un aparato de gestión informacional y del conocimiento sin precedentes. Reaparece en la sociedad la posibilidad de conocer de manera objetiva, neutral y desinterasada la realidad a estudiar (el ciudadano, su bienestar y satisfacción), reflejada ahora en los datos masivos observados a través de una metodología –el Big Data y el uso de algoritmos- capaz de ofrecernos una imagen supuestamente perfecta de la realidad.
Probablemente si estás leyendo este blog tengas un problema analítico que quieras resolver con datos. Es posible también que tengas unos conocimientos de estadística que quieras poner en práctica, así que es hora de elegir una herramienta analítica. Así que vamos a intentar orientaros en la elección, aunque las tres herramientas de analítica nos van a permitir hacer en general los mismos análisis:
Conocimientos previos de programación. Si sabes programar y vienes de un entorno web, probablemente Python sea el más fácil de aprender. Es un lenguaje más generalista que los otros dos y solamente tendrás que aprender el uso de las librerías para hacer análisis de datos (Pandas, Numpy, Scipy, etc.). Si no es el caso y lo tuyo no es programar, SAS es más fácil de aprender que R, que es el lenguaje más diferente de los tres, dado su origen académico-estadístico.
Coste de las herramientas. SAS es un software comercial y bastante caro. Además el uso de cada una de sus capacidades se vende por paquetes, así que el coste total como herramienta analítica es muy caro. La parte buena es que tienes un soporte. Por el contrario, tanto R como Python son gratuitos, si bien es cierto que empresas como Revolution Analytics ofrecen soporte, formación y su propia distribución de R con un coste bastante inferior a SAS. Normalmente sólo las grandes empresas (bancos, compañías telefónicas, cadenas de alimentación, INE, etc.) disponen de SAS debido a su coste.
Estabilidad de la herramienta. Al ser un software comercial, en SAS no hay problemas de compatibilidad de versiones. R al tener un origen académico ofrece distintas librerías para hacer un mismo trabajo y no todas funcionan en versiones anteriores de R. Para evitar estos problemas en una gran empresa recomendaría utilizar alguna distribución comercial de Revolution Analytics por ejemplo.
Volumen de datos. Las única diferencia es que SAS almacena los datos en tu ordenador en vez de en memoria (R), si bien es cierto que las 3 tienen conexiones con Hadoop y las herramientas de Big Data.
Capacidad de innovación. Si necesitas utilizar las últimas técnicas estadísticas o de Machine LearningSAS no es tu amigo. Es un software comercial que para garantizar la estabilidad de uso entre versiones retrasa la incorporación de nuevas técnicas. Aquí el líder es R seguido de Python.
Conclusión: no es fácil quedarse con una herramienta de analítica y las personas que trabajamos en grandes compañías estamos habituados a trabajar con varias. SAS ofrece soluciones integradoras a un coste elevado. R tiene muchas capacidades de innovación debido a su origen y Python tiene la ventaja de ser un lenguaje de programación generalista que además puede servir para hacer Data Mining o Machine Learning. La elección dependerá de lo que estés dispuesto a pagar y tus necesidades específicas. Yo tengo la suerte o desgracia de trabajar en una gran empresa, así que dispongo de las 3.
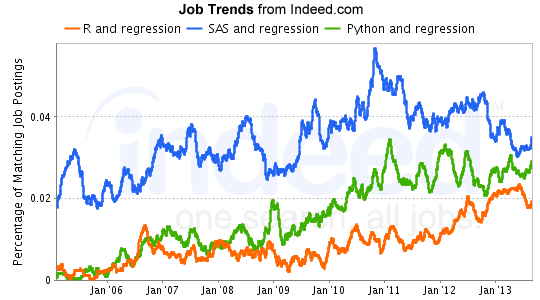
Tendencias en lo que a demanda de perfiles con conocimiento de R, SAS y Python se refiere (Fuente: http://www.statsblogs.com/2013/12/06/sas-is-abandoned-by-the-market-for-advanced-analytics/)
¿Alguna vez te has preguntado cómo eligen las grandes compañías los clientes a los que lanzan sus campañas? ¿Por qué por ejemplo puede un banco enviarme un mail o una carta para ofrecerme el último plan de pensiones que han diseñado y no a mi vecino si los dos somos clientes del mismo banco y vivimos en el mismo edificio?
La selección de a qué clientes lanzar campañas de marketing forma parte de lo que se denomina Data Mining o Minería de Datos. Tradicionalmente las grandes compañías han analizado los datos históricos que almacenan sobre sus clientes para buscar aquellos clientes que no tienen contratado un producto actualmente con ellas, pero que de alguna forma sí se parecen a otros clientes que sí tienen dicho producto. La idea es sencilla: ¿no tendría sentido sólo enviar comunicaciones sobre campañas de Marketing de un producto a los clientes que aunque no lo tengan contratado actualmente sí tengan probabilidad de hacerlo en un futuro? La base sobre la que se basan para calcular esas probabilidades es la estadística y los algoritmos de Machine Learning y las comparaciones se hacen en base a los datos históricos almacenados sobre los clientes.
Haciendo esas comparaciones basadas en los datos que tienen sobre los clientes las empresas consiguen aumentar sus tasas de éxito de contratación de productos de manera significativa y ofrecen productos que de cierta forma son mucho más personalizados, ya que tienen en cuenta mis datos como persona individual antes de ofrecérmelos. Además se ahorran mucho dinero en publicidad, ya que en cierta forma están centrando el tiro seleccionando únicamente los clientes con alta probabilidad (propensión) de compra.
Pero actualmente estamos en una nueva era caracterizada por la abundancia de información (Big Data). ¿Por qué no utilizar además de la información interna de los clientes datos que podamos obtener de fuentes externas? ¿No tendría sentido en el ejemplo del banco anterior tener en cuenta que yo en alguna ocasión he navegado por internet buscando información sobre planes de pensiones? ¿No he mostrado de alguna forma ya mi interés por el producto al haberlo buscado por internet? ¿No sería más probable que yo contratara el plan de pensiones que mi vecino que nunca se ha preocupado por su jubilación?
Como empresa podría utilizar los datos de navegación de mi web para mejorar el proceso anterior. ¿Y si además a pesar de que el banco no tiene información sobre el valor de la casa en la que vivo, obtiene información sobre el valor de la misma en el catastro u otras fuentes de información externas? El cruce de información interna sobre los clientes con información externa es lo que actualmente se denomina Big Data y permite a las grandes empresas obtener más información sobre los clientes y tal y como hemos visto con mi ejemplo, mejorar su precisión a la hora de elegir futuros clientes para sus productos.
Moraleja: si antes las grandes compañías lo sabían todo sobre nosotros, hoy todavía más. Como consuelo, al menos es más probable que sólo reciba comunicaciones sobre productos en los que es más probable que esté realmente interesado no tengan que eliminar demasiados emails comerciales porque no me interesan.
El Big Data está empezando a entrar en los procesos de negocio de las organizaciones de manera transversal. Su uso se está «democratizando», de manera que cada vez más entra en un discurso de «usuario» en lugar de ser un tema que se trate únicamente en ámbitos más técnicos y tecnológicos.
Sin embargo, en los últimos tiempos, se están creando nuevas herramientas analíticas diseñadas para las necesidades de las unidades de negocio, con sencillas, útiles e intuitivas interfaces gráficas. De este modo, el usuario de negocio impulsa la adopción de soluciones Big Data como soporte a la toma de decisiones de negocio. Prueba de ello son aplicaciones como Gephi, Tableau, CartoDB o RStudio, que han simplificado mucho el trabajo, haciendo que las habilidades técnicas no sean un limitante para adentrarse en el mundo del Big Data.
Mapa de calor en CartoDB (Fuente: camo.githubusercontent.com)
La llegada de Big Data al usuario de negocio representa una oportunidad de ampliar el número de usuarios y extender el ámbito de actuación. Se prevé así que cada vez entren más proveedores, tanto de soluciones tecnológicas como de agregadores de datos. Todo esto, sin olvidar la importancia del cumplimiento de las políticas de gobierno de TI, la protección de la información y de los datos, así como los riesgos de seguridad.
Por todo ello, hemos organizado el próximo 27 de Octubre de 2015, de 15:30 a 18:00, en nuestra Sala Garate de la Universidad de Deusto, un workshop titulado «Aplicación del Big Data en sectores económicos estratégicos«. En este evento podrá conocer varias soluciones de diferentes sectores en los que este movimiento de aplicación del Big Data para usuarios de negocio está ocurriendo. La concesión de préstamos en el sector financiero, la puesta en valor de piezas culturales, sistemas para evitar el fraude, el aumento de la seguridad ciudadana o la mejora del sistema de ventas en aeropuertos representan ejemplos donde poder observar lo descrito anteriormente. Con esto, veremos cuál es el ritmo de adopción de Big Data en las organizaciones, y cuáles son los mecanismos de implantación de las soluciones con carácter transversal en las organizaciones.
A través de este artículo queremos daros la bienvenida a nuestro blog Deusto BigData. Un espacio dedicado a temas relacionados el Big Data. Un concepto que hace referencia al gran volumen de datos que se generan en la actualidad y su impacto en diferentes contextos: las organizaciones en general (y las empresas en particular), la sociedad, las personas, etc.
Queremos contribuir a que conozcas de una manera sencilla el fascinante mundo de los datos. Puedes suscribirte a nuestro blog en el panel lateral derecho. Esperamos que disfrutes de Deusto BigData 🙂
Big Data (Imagen: By Camelia.boban (Own work), CC BY-SA 3.0)