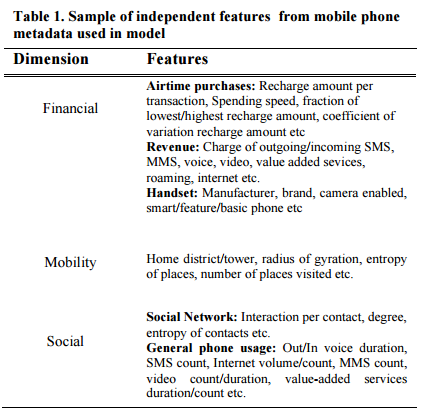
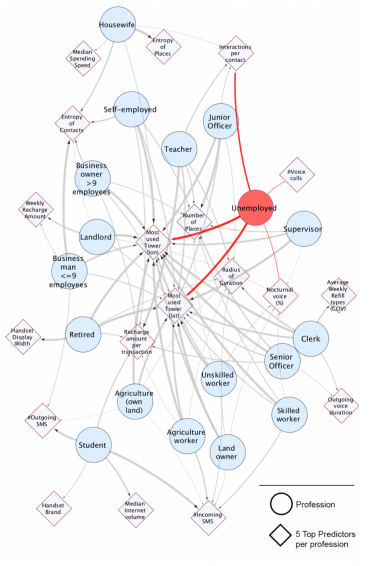
(Artículo escrito por Izaskun Larrea, alumna de la promoción de 2017 en el Programa en Big Data y Business Intelligence en Bilbao)
The question lies at the heart of our campaign, which argues that government’s role should be to collect and administer high-quality raw data, but make it freely available to everyone to create innovative services». “Free our Data campaign”. Reino Unido. Junio de 2006.
¿La Seguridad Social será solvente para nuestros nietos? ¿Cuál es el impacto de las nuevas inversiones en salud, educación y carreteras? ¿Cuál será la proyección de las políticas en la Industria 4.0 de la C.A. de Euskadi? Estas son, algunas de las preguntas que se pueden resolver con Big Data.
El Big Data es una combinación de la información masiva de datos y los recursos tecnológicos. Al igual que las empresas, las administraciones públicas (AAPP) pueden conocer mucho más a los ciudadanos, lo que leen, lo que perciben, etc.
La combinación e implantación de políticas de Gobierno Abierto, “Big Data” y “Open Data” pueden brindar importantes y sustanciosos beneficios a los ciudadanos. Estudios como demosEuropa (2014) concluyen que los países que apuestan por la transparencia de sus administraciones públicas mediante normas de buen gobierno cuentan con instituciones más fuertes, que favorecen la cohesión social.
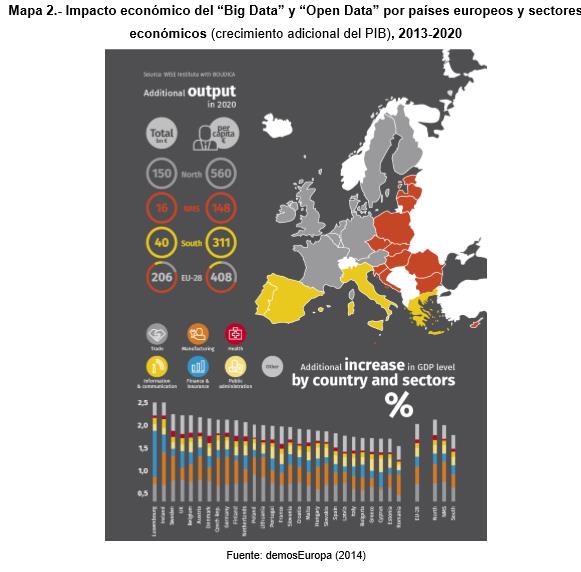
Según un estudio realizado en la Unión Europea la implementación de las políticas de Gobierno Abierto “Big Data” y “Open Data” tendrán un efecto considerable. El impacto dependerá, lógicamente, del grado de extensión y desarrollo de nuevas tecnologías en cada economía y sector productivo, así como del grado de dependencia y utilidad de dicha información en cada uno de ellos. De hecho, aunque se prevé un impacto positivo en todos los sectores económicos, las ramas de actividad sobre las que se espera un mayor impacto serán la industria manufacturera y el comercio, seguidas de las actividades inmobiliarias, el sistema sanitario y la administración pública (ver siguiente mapa).

En cuanto al impacto geográfico, conviene llamar la atención sobre el caso particular de España, ya que será uno de los países en los que menos repercusión económica tenga el “Big Data” y “Open Data”. Ello se debe al todavía limitado desarrollo de este tipo de tecnologías que permitan aflorar adecuadamente los beneficios que pueden llegar a reportar a la economía, así como de una mayor representatividad de las PYMES en el tejido empresarial español. Ahora bien, el hecho de que el impacto estimado del “Big Data” y “Open Data” sea mayor en los países del norte europeo, donde se han desarrollado mucho más estas tecnologías, pone de manifiesto que éstas ofrecen rendimientos crecientes que conviene aprovechar, independientemente del posicionamiento de cada uno de los países.
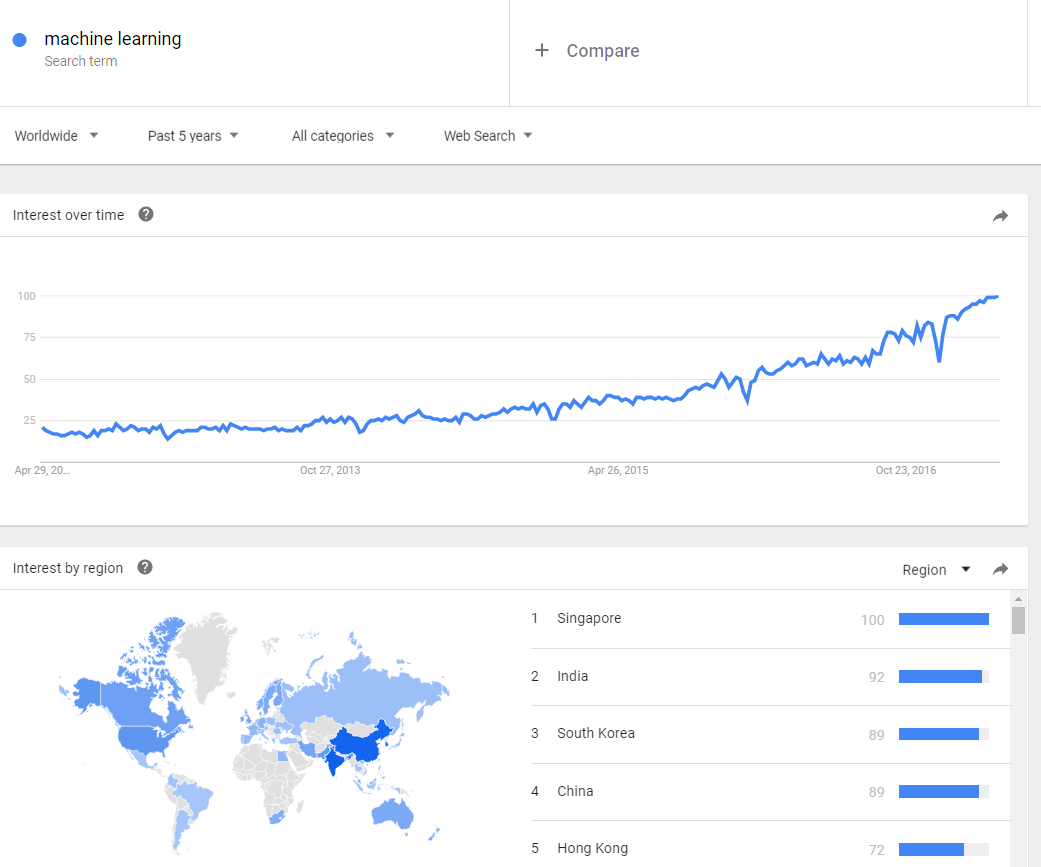
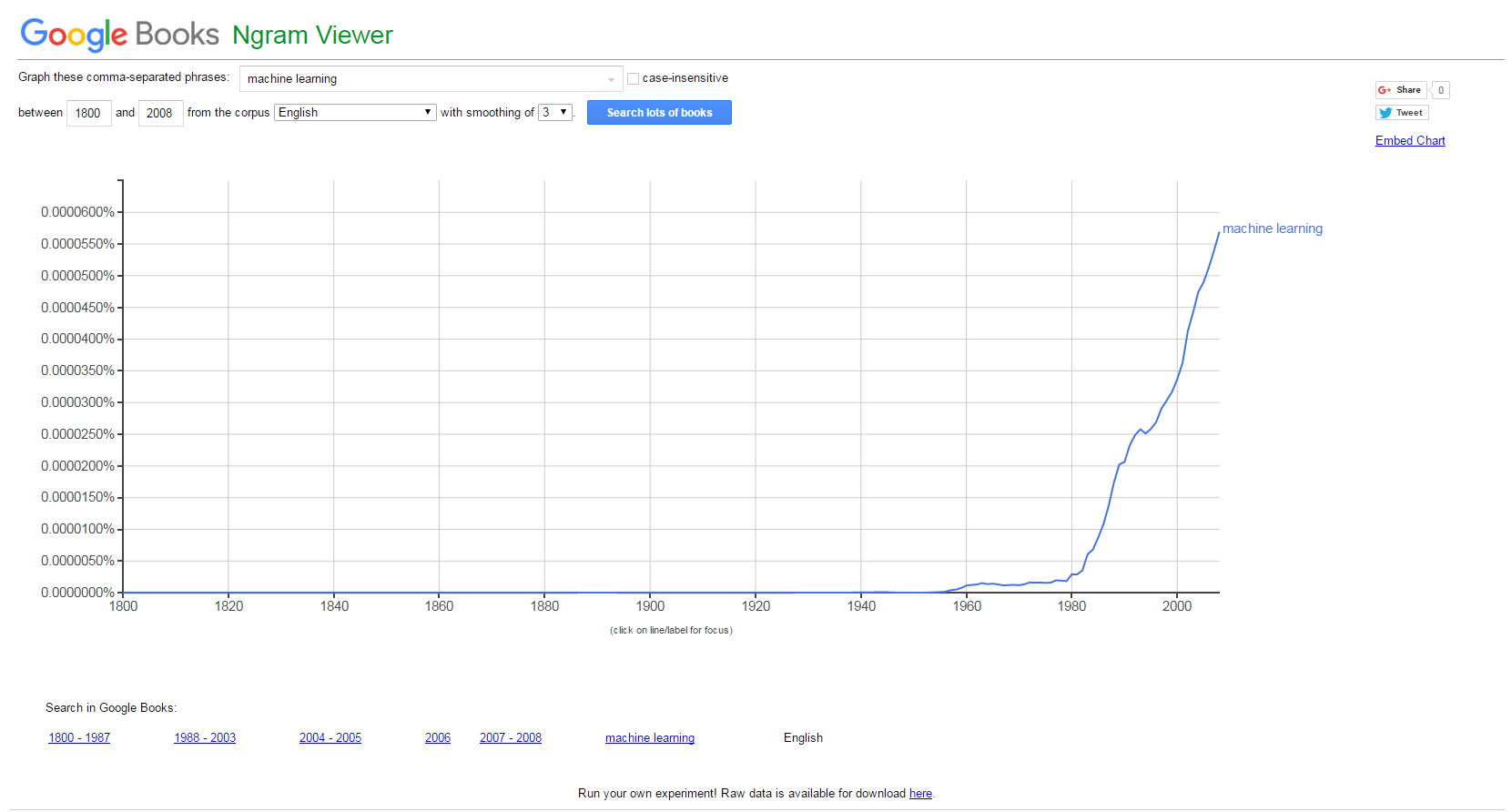
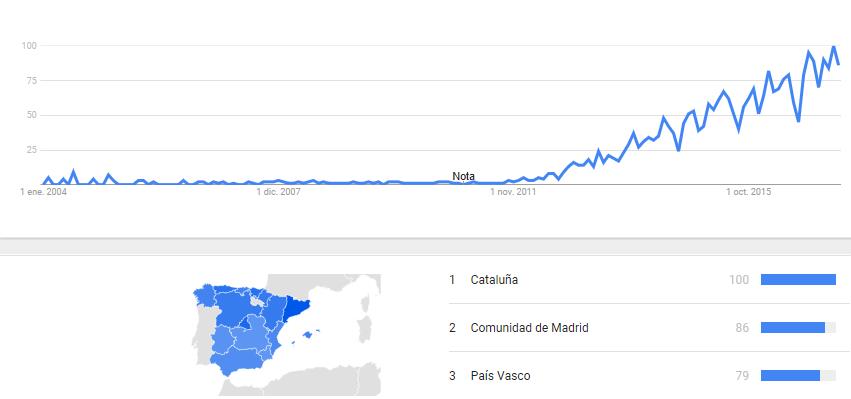
Aunque podemos percibir que la C.A. de Euskadi puede tener un comportamiento similar a las regiones del norte y centro de Europa visualizando el siguiente gráfico, dónde se refleja el interés de los ciudadanos por el Big Data.
Un elevado número de países han planteado iniciativas de “Open Data”, con el objetivo de incentivar la actividad económica, favorecer la innovación y promover la rendición de cuentas por parte de las AA.PP. Estas iniciativas en absoluto se limitan a los países más avanzados, sino que se están aplicando en múltiples territorios como herramienta de desarrollo económico, como es el caso de India. No obstante, la formulación de buenas prácticas requiere una selección de los principales referentes a escala internacional. Para ello, es posible analizar estudios recientes como, por ejemplo, el Barómetro elaborado por la World Wide Web Foundation.
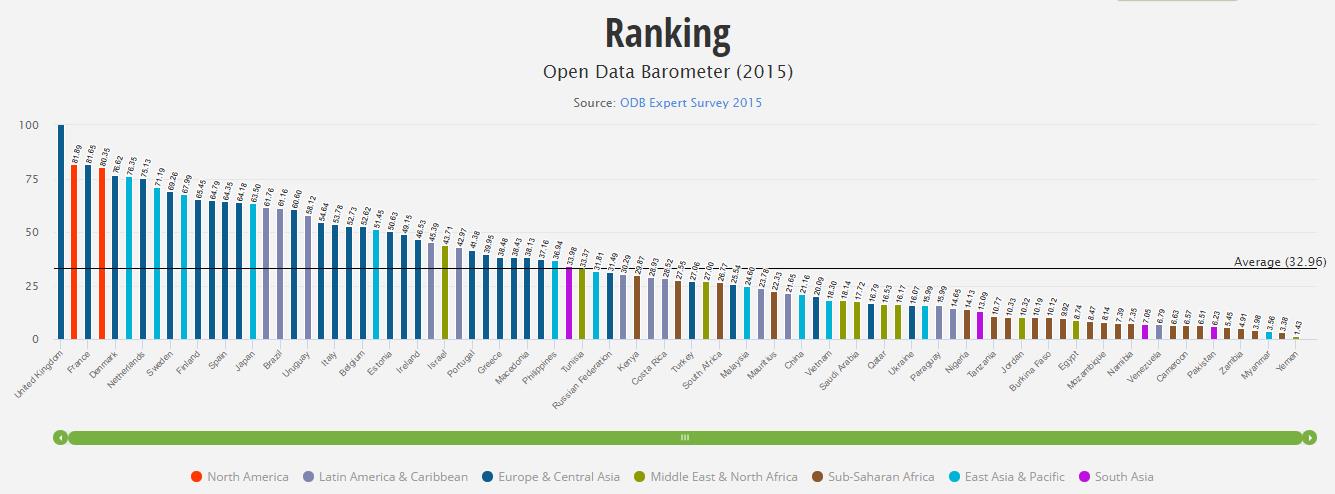
Reino Unido es el país más avanzado en materia de “Open Government Data” (OGD), tanto en lo que se refiere a la adaptación de sus instituciones, ciudadanos y tejido empresarial, como en la implementación de iniciativas públicas y en el impacto conseguido por las mismas.
El Reino Unido es reconocido ejemplo como uno de los principales referentes a escala internacional en materia de Gobierno Abierto. Sus actividades en torno a la liberación de datos comenzaron en 2006, a instancias de diversas campañas impulsadas por la sociedad civil y los medios de comunicación (como “Free our Data”), y ha logrado mantener un claro apoyo a estas estrategias tanto por parte de los últimos Primeros Ministros como de los principales partidos políticos británicos.
Entre los objetivos de la estrategia de apertura de datos de Reino Unido destaca la importancia atribuida a la innovación y a la dinamización económica que estas iniciativas pueden favorecer. En este sentido, se ha creado un organismo no gubernamental, el Open Data Institute (de financiación público-privada), cuya misión específica es apoyar la creación de valor económico a partir de los datos puestos a disposición de ciudadanos y empresas. Asimismo, las distintas áreas de la Administración han recibido el mandato de diseñar estrategias propias de apertura de datos, incluyendo acciones específicas que incentiven el uso de sus datos y la realización de informes públicos periódicos sobre sus avances en este ámbito.
Por otra parte, el Reino Unido ha puesto en marcha soluciones que tratan de contribuir a resolver los problemas que surgen al publicar grandes volúmenes de datos correspondientes a áreas de actividad o responsabilidad muy diversa. En este sentido, cabe subrayar:
- La creación de los Sector Transparency Boards en diversos departamentos de la Administración. Estos grupos de trabajo cuentan con la participación de representantes de la sociedad civil y de las empresas, y tienen como objetivo canalizar las solicitudes de datos y orientar al Gobierno sobre las prioridades a seguir para liberar nuevos conjuntos de datos.
- El desarrollo de programas de formación, competiciones y eventos diseñados para incentivar el uso de datos públicos por parte de la sociedad civil.
- La asignación de financiación pública a programas dirigidos a incrementar el aprovechamiento de los datos liberados por parte del tejido empresarial.
- Asimismo, se observan esfuerzos dirigidos a incrementar la calidad, estandarización y facilidad de explotación de los datos distribuidos (como los derivados del servicio cartográfico, el registro catastral, el registro mercantil).