(Entrada escrita por David Ruiz de Olano, Director de Programas en Deusto Business School)
Asistiendo a una jornada de Alex Rayón, es cada vez más evidente que la forma de hacer marketing tiene que cambiar. Alex es director del seminario de Big Data & Business Intelligence (BDBI), organizado entre la Facultad de Ingeniería de Deusto y Deusto Business School, y profesor e investigador en la Universidad de Deusto sobre Marketing y Big Data y muy activo en esta área.
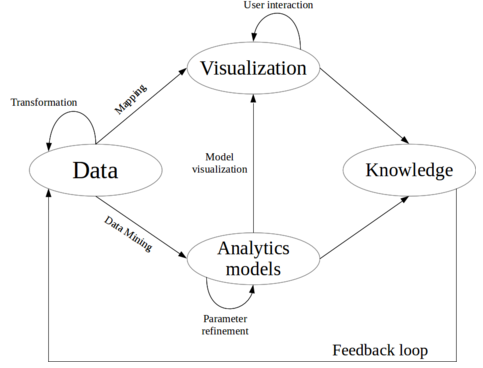
Desde el punto de vista de marketing, tradicionalmente el proceso del marketing (marketing estratégico y marketing operacional) se puede ilustrar con la siguiente figura:
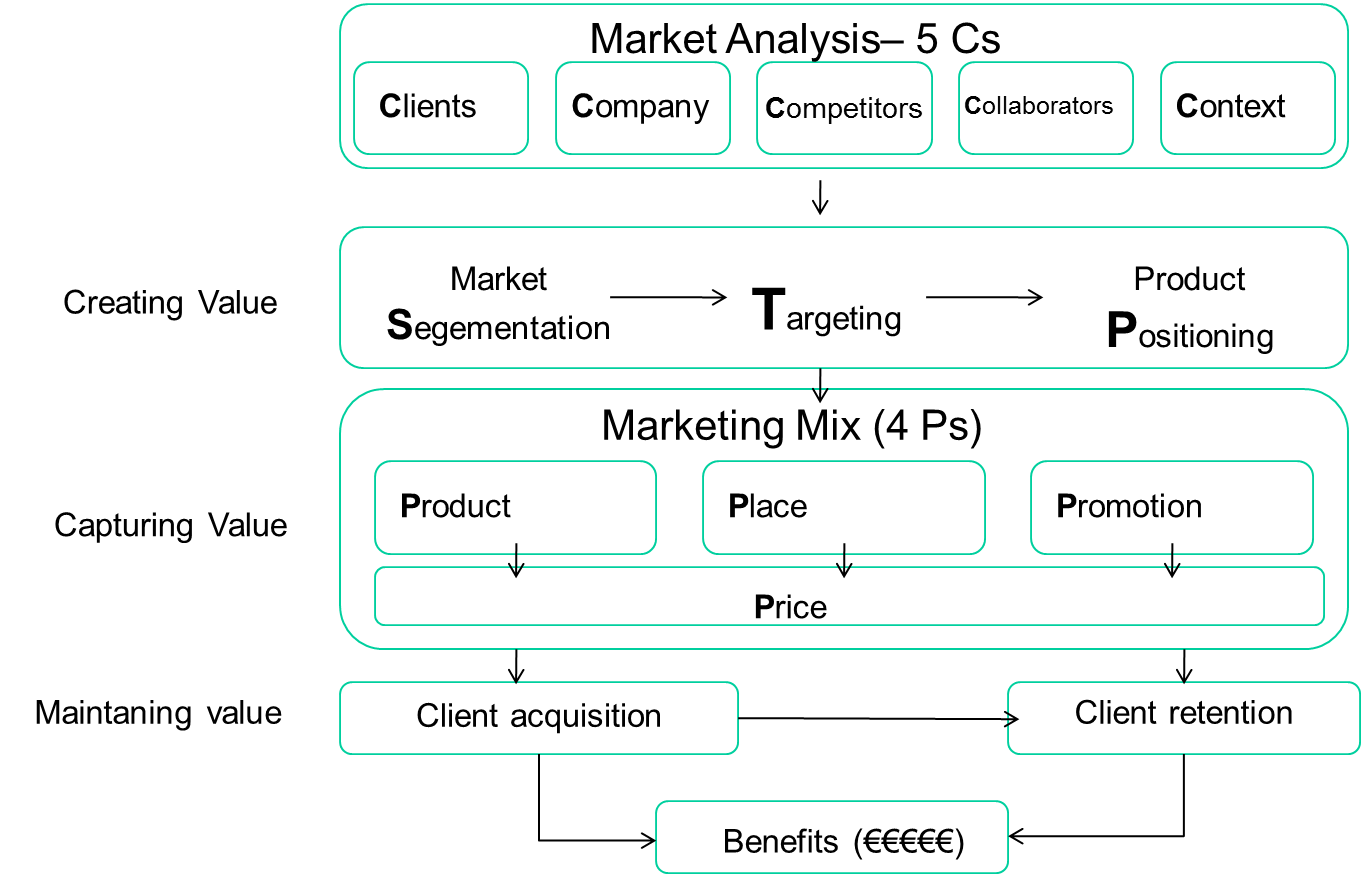
Evidentemente en el análisis de las 5C, todos los datos que se puedan traducir en información ayudarán a tener un mejor diagnóstico de nuestro entorno.
Pero lo que me interesa de esta jornada es la aplicación del BDBI en la creación de valor para el cliente. Una de las claves en el marketing es la segmentación (¿quién es mi cliente?). Tradicionalmente las empresas identifican quién es su público objetivo, basado en parámetros demográficos, sociales, económicos, comportamiento, etc… de un mercado más general. Con esta identificación, buscan cuáles son sus problemas, necesidades, etc… escogen un público determinado y se posicionan en ese nicho.
Como decía Kotler, gurú del marketing del siglo pasado – como pasa el tiempo-, si resuelves el problema de segmentación, automáticamente tendrás las respuestas para definir tus 4Ps (producto, promoción, lugar y precio) y te saldrán automáticamente. Porque una vez sabes quién es tu potencial cliente, ya sabes qué producto tienes que ofrecerle, qué ventajas tiene que tener sobre los competidores, dónde está y cómo poder llegar a él, qué precio está dispuesto a pagar. Teniendo muy claro quién es mi cliente, cuántas horas de reuniones nos podríamos ahorrar discutiendo sobre el precio…
Evidentemente BDBI tiene mucho que decir en la segmentación. Pero no tanto a priori, si no a posteriori. Con la cantidad de datos que las empresas tienes sobre nosotros, ya no hace falta hacer hipótesis de quién es nuestro cliente: basta mirar en los datos e identificarlos.
Gracias a las herramientas de BDBI (que por cierto, ni son caras ni difíciles de usar), basta un poco de curiosidad, jugar con los datos y empezar a ver correlaciones. ¿Hay alguna relación entre los clientes que compran 2 mismos productos? ¿Es nuestra segmentación inicial la que se refleja en las compras de nuestros clientes y las ventas de nuestros productos? ¿A qué horas del día hay un comportamiento de compra parecido? Por ejemplo, en Tableau, una empresa que intenta facilitar la visualización de BDBI, podéis ver un caso sobre la segmentación y el hecho de cuestionarnos nuestras hipótesis iniciales.
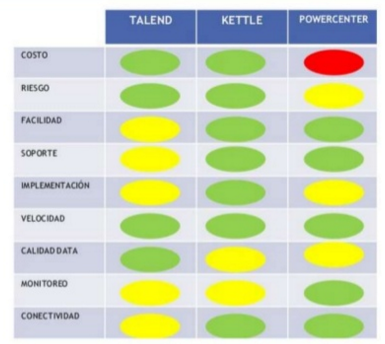
Esta aproximación que aparentemente parece que es sólo válida para comercios B2C online se pueden extraer de otros lugares. El BDBI no es exclusivo de negocios online, nacidos en la era digital. Efectivamente, lo tienen más fácil, pero todas las empresas pueden empezar a explorar. Quizás sea ese uno de los retos para la implementación del BDBI en los negocios que no vienen del mundo online. Como comentaba Alex, un 60%- 80% de los esfuerzos para una estrategia de BDBI se centran en los datos y en el ETL (Extracción, Transformación y carga o Load), encontrarlos entre las diferentes partes del negocio (ERPs, CRM, departamento financiero, controller, etc…), limpiarlos y ponerlos bonitos. Aunque Alex menciona 4 etapas y el tiempo que se va a dedicar a cada etapa:
- Etapa 1: Cargar datos (hasta un 80%)
- Etapa 2: Preguntas (5%)
- Etapa 3: Modelo estadístico/analítico (5%)
- Etapa 4: Visualización de resultados (10%)
Quizás mi visión sería empezar por las preguntas y terminar en el modelo estadístico. Pero lo que estoy seguro es que una de las grandes aportaciones del BDBI al marketing es en el tema de segmentación, pasando de una segmentación clásica a una clusterización (que hasta ahora era más complicado). La maravilla del BDBI es que no tenemos que pensar cuáles son las variables para hacer el cluster, las propias herramientas nos dirás qué cluster son los que representan mejor a los clientes y qué características. También, incluso nos permitirá saber cuál es la probabilidad de que un cliente de telefonía abandone su compañía y qué características tiene o saber la características del cliente de un banco portugués que no compra un producto y el proceso comercial asociado. Y por otra parte, ayudarnos a hacer preguntas que hasta ahora ni nos habíamos imaginado.
Lo que está claro, es que si una empresa quiere sobrevivir en los próximos 10 años, de una forma u otra, el BDBI le impactará de alguna manera. La pregunta es ¿espero a que me obliguen o empiezo a explorar ya? La creación de valor en mi organización a través del Big Data y Business Intelligence está a mi disposición.