En este humilde blog, ya hemos hablado con anterioridad de las ciudades inteligentes. Lo hicimos para referirnos al cruce entre las ciudades y el Big Data y cómo se puede contribuir mutuamente (en este artículo), y también, para hablar del caso particular de Bilbao, que ha apostado mucho -y sigue haciéndolo- por las soluciones inteligentes basadas en el análisis de datos (en este otro artículo).
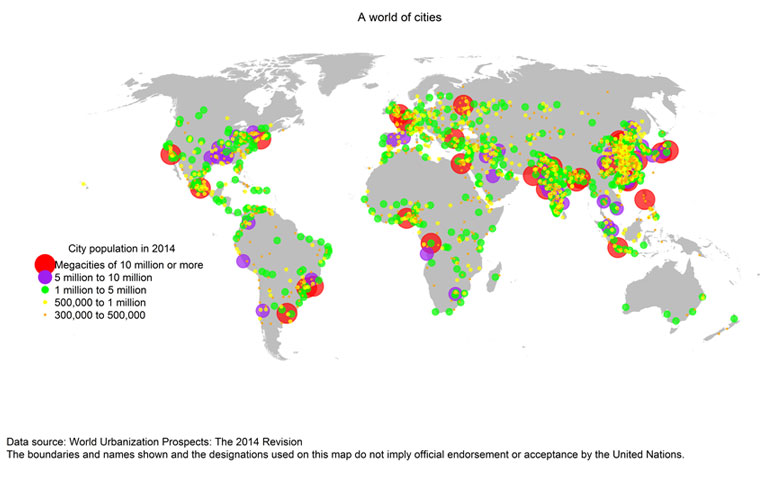
Pero no está todo escrito. Es más, es un campo, donde se sigue recibiendo mucha inversión, y donde sigue habiendo mucho interés por muchos agentes en ver las posibilidades que abre. De hecho, en el pasado foro Smart City World Expo de Barcelona, se mostraron muchas soluciones que se están llevando a cabo por el mundo para hacer de las ciudades un mejor lugar para vivir. Hay que considerar que la tecnología tiene siempre mucho que aportar allí donde hay retos humanos y sociales. La tecnología extiende el esfuerzo humano, lo complementa, y lo ayuda. Y un ente que va a tener muchos retos va a ser la ciudad, cuando se espera que en 2050 hasta un 75% de la población mundial viva en zonas urbanas. Ahora mismo, también ya estamos en una era de las megaciudades.
Carlo Ratti, un investigador del MIT en el Departamento de Estudios Urbanos y Planificación, suele referirse a estos retos y a estas soluciones que las ciudades necesitan apoyándose en un símil con la Fórmula 1. Quizás hayan visto recientemente la película Rush. En ella, se puede disfrutar del espectacular duelo que tuvieron Niki Lauda y James Hunt. Una Fórmula 1, donde todavía no había sensores en todas las esquinas, la telematría no jugaba el papel que desempeña hoy, y en el que el coche y el piloto lo era todo. Pero, hoy en día, las ventajas competitivas, además del coche y el piloto, lo de la infraestructura de procesamiento y la recogida de datos (información en tiempo real del estado de la pista, el viento, condiciones del vehículo, etc.).
Siguiendo con el símil, nos vamos de las pistas de la Fórmula 1 a las ciudades. Estamos hablando de zonas urbanas que si las dotamos de sensores -recogida de datos- y de elementos de conectividad -adquieren capacidad de comunicar el estado de las cuestiones: clima, equipamiento, etc.-se podrán gestionar de manera más eficiente los servicios. Éste, debe ser el fin de disponer de una ciudad completamente sensorizada y conectada. Poner en valor los datos transformando los modelos de prestación de servicios a los ciudadanos hacia un mundo en el que el dato se convierte en palanca de ventaja competitiva para su bienestar.
¿Y qué se está haciendo en el mundo en relación a esto? Muchas cosas. Los datos y la conectividad son los protagonistas ya en muchos sitios. Desde cruces inteligentes que reducirían no solo los tiempos de espera en semáforos o rondas, microbuses sin conductor en Países Bajos, Singapur o California, drones con aplicaciones para colaborar en situaciones de emergencia médicas, etc. Son solo algunos de los ejemplos donde los datos fluyen, hasta situarse en el centro de la gestión de una ciudad.

Como decíamos al comienzo, es cierto que las TIC ayudan al humano. Pero todavía falta mucho por realizar. Las ciudades todavía están en pleno proceso de digitalización. Y con ello me refiero básicamente a la instalación de sensores capaces de recoger datos de cualquier lugar de una ciudad. Es lo que tiene este nuevo paradigma del Big Data: recojamos datos, que luego ya nos encargamos de encontrar lógica alguna o inteligencia sobre los mismos. La eventual saturación del tráfico, volúmenes de ruido o contaminación excesivos, etc. son consecuencia de disponer de esta infraestructura.
Pero, ojo, no olvidemos que llenar una ciudad de sensores no la convertirá automáticamente en inteligente. Disponer de buenos datos ya comentamos era clave. Disponer de una buena infraestructura de datos, también. Pero una vez que disponemos de las herramientas, necesitamos otros elementos para que el proyecto sea realmente útil y provechoso:
- Liderazgo: necesitamos de políticos y representantes que se crean el valor que aportan los datos, y lo pongan en el corazón de sus políticas. No solo necesitamos que lo cuenten en los discursos, sino también que haya políticas transformadoras sobre el análisis de datos que hayan hecho.
- Habilidades analíticas y estratégicas: y claro, para que esos líderes tomen esas decisiones, las habilidades analíticas que deban incorporar en sus equipos se tornan fundamentales. Y convertir así, esos análisis de datos en toma de decisiones estratégicas.
- Toma de decisiones: decidir. Hay veces que incluso es bueno decidir, para poner en marcha el «prueba y error» de toda la vida.
Las ciudades, se beneficiarán de esta era de los datos. Pero necesitamos líderes, habilidades analíticas y decisiones. Estos otros elementos menos divulgados harán que esto de las ciudades inteligentes sea una realidad.