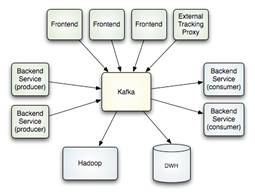
“La comunicación corporativa ya tiene claro que la mejor manera de llegar a sus receptores es con la caracterización y eso sólo se consigue a través del Big Data” (Nagore de los Ríos)

Nagore de los Ríos participará en nuestro Programa en Big Data y Business Intelligence y Programa Experto en Análisis, Investigación y Comunicación de Datos que impulsa la Universidad de Deusto. Fundadora de Irekia, portal de Gobierno Abierto del Gobierno Vasco, y consultora Senior del Banco Mundial en iniciativas de Comunicación y Open Data, acercará su experiencia en el ámbito del Big Data y otras cuestiones vinculadas con la comunicación y el Business Inteligence. Para Nagore de los Ríos, la complejidad del ámbito comunicativo en la actualidad, cuando se incorpora el Big Data, hace necesario el uso de metodologías, como Outreach Tool, para diseñar estrategias y planes de comunicación. Participará en el módulo M3.1 de nuestro Programa de Big Data, en colaboración con Mª Luz Guenaga y Alex Rayón, en las sesiones de Open Data y visualización de datos.
Periodista de formación, consultora en Comunicación, experta en Open Data, ¿cuál es tu aportación al Programa en Big Data y Business Intelligence?
Tanto el Open Data como la comunicación están muy ligados a los Datos. El Open Data porque en sí mismos son fuentes de datos que cualquiera puede extraer y con ello enriquecer su propio Big Data, cruzando sus datos con los Open Data, lo que supone aplicar el Business Intelligence de una forma mucho más enriquecida y además de manera gratuita. Es la materia prima más barata y accesible que alcanza gran valor cuando se cruza con otros datos bajo las preguntas adecuadas.
Y cuando hablamos de comunicación, en primer lugar, los datos son la primera y mejor fuente de información, la más fiable, la que nos aporta el mejor conocimiento, por lo que es clave realizar buenas preguntas a los datos para que nos ofrezcan las respuestas que deseamos conocer. En segundo lugar porque para comunicar es muy importante asegurarnos de que no generamos ruido, de que el destinatario está receptivo a nuestro mensaje y es el destinatario acertado. De este modo, el Big Data se utiliza en dos momentos claves de la comunicación, el primero de ellos a la hora de hipersegmentar a los destinatarios, saber lo que desean o necesitan escuchar y en segundo lugar a la hora de vincular los mensajes y segmentarlos de la misma manera. Muchas veces queremos comunicar demasiadas cosas a todas las personas y eso no es eficaz. Si a la Comunicación le aplicamos las técnicas de Business Intelligence y utilizamos bien el Big Data podemos obtener la respuesta exacta de quien es el que necesita recibir un determinado mensaje, y qué mensaje es el más adecuado.
Y por último el Big Data está muy ligado al Marketing y a la Comunicación sobre todo a la hora de conocer los resultados, establecer los indicadores, extraer información valiosa de las redes sociales y de lo que las personas y marcas están hablando así como observar los impactos que al emitir los mensajes somos capaces de producir o no en nuestros públicos objetivos.
Cuando hablamos de comunicar, contamos con dos ámbitos, el del periodismo tradicional y la comunicación corporativa o institucional. ¿Qué beneficios obtiene cada uno de ellos?
Ambos mundos están despertando y entendiendo que los datos son la mejor fuente de información posible. En el ámbito del periodismo se están dando cuenta de que los datos no mienten y no tienen intenciones o están condicionados, los periodistas empiezan a ver una ventaja no solo en la objetividad de sus informaciones sino también en el acceso a las fuentes y en la rapidez para encontrar las respuestas y poder con ello contar las historias que los datos guardan.
En el ámbito de la comunicación corporativa también se están dando cuenta de que para llegar a sus receptores o clientes de forma más directa la hipersegmentación es básica y sólo se consigue a través del Big Data. Gracias al Big Data además pueden localizar a nuevos receptores que son público objetivo de las marcas o empresas, más allá de los habituales medios de investigación sobre audiencias, que se centraban en los últimos años en receptores que desde las redes sociales estaban dispuestos a escuchar los mensajes de la marca o los seguidores o fans que se conseguían por otras vías del marketing.
¿De qué modo puede ayudar el Big Data a la comunicación de empresas e instituciones?
Con la aparición de las redes sociales, las organizaciones encontraron una forma más directa de llegar a su audiencia sin pasar por intermediarios, pero se encontraron con el problema de captar tráfico y atraerlas hasta sus perfiles o webs para poder hacer llegar sus mensajes. Gracias a la publicidad en internet que facilita la segmentación pudieron acotar a ese público pero seguían esperando a que fuesen los consumidores quienes, buscando productos similares o a través de palabras claves, acabasen en sus publicaciones o anuncios. Ahora con el Big Data hemos alcanzado ya el tercer nivel, y son las marcas las que por distintas vías recopilan información de los consumidores, y utilizan el mejor canal para llegar a ellos.
Otra ventaja que encuentran ahora todas las organizaciones públicas o privadas es que pueden cocrear mejor sus servicios con los destinatarios y usuarios finales. Ya no se basan en intuiciones o en evidencias o en encuestas o preguntas de satisfacción donde los usuarios decían que es lo que ellos mismos creían que necesitaban o querían (y digo creían porque muchas veces pensamos que nos vamos a comportar de una cierta manera o vamos a tener unas necesidades concretas y luego la realidad es totalmente diferente). Los servicios y productos se pueden cocrear ahora de forma más fehaciente, prediciendo el futuro y ofreciendo soluciones a lo que verdaderamente se va a consumir o necesitar
Pero para ello hace falta actuar con cierto método, por el volumen de información que se maneja.
Si hablamos de comunicación en concreto, y queremos aplicar una estrategia y un plan de comunicación toda esa información que el Big Data y el Business Inteligence nos ha aportado lo debemos canalizar y nos sirve de base para realizar una estrategia. Contar con una estrategia definida permite señalar objetivos y llegar a alcanzarlos, no perder la perspectiva, ser eficaz en el desarrollo de la ocupación correspondiente, no malgastar tiempo ni recursos, sobre todo en un mundo tan complejo como el presente. Y una vez determinada la estrategia es necesario un plan de acciones, porque el plan permite conocer de antemano qué se pretende conseguir y cómo se piensa lograrlo.
Y para diseñar esa estrategia y el plan con el que se va a ejecutar, es necesaria una metodología. En este sentido, os recomiendo una metodología abierta y gratuita que se llama Outreachtool.com, que está empezando a dar sus primeros pasos ahora.
¿Nos puedes explicar qué es Outreach Tool, y que supone para la Comunicación corporativa e institucional en el ámbito del Big Data?
Se trata de una herramienta para generar estrategias y planes de comunicación efectivos de manera abierta, sencilla, intuitiva y ágil. Está publicada bajo la licencia Creative Commons y se conforma por una metodología y una tabla dinámica, que se pueden descargar gratuitamente. Se desarrolla en tres fases y se resuelve en un calendario de acciones para desarrollar la estrategia que se genera con la metodología.
A grandes rasgos (porque la metodología es más completa) La primera fase gira en torno a la empresa, institución, marca personal para la que se prepara la estrategia. La segunda fase analiza el conjunto de receptores a los que se dirige el plan, con una profunda hipersegmentación de destinatarios. Porque no les interesa lo mismo a unos destinatarios que a otros, ni se quiere conseguir lo mismo de todos ellos. Esto marcará también lo que se va a comunicar, que se analiza en la tercera fase, cuando se concreta el qué, el cómo, el con qué y el cuándo comunicar.
Nuestro empeño con Outreach Tool ha sido obtener un mecanismo fácil de comprender y aplicar que, no obstante, no se desvirtúe al simplificar en demasía el complejo entramado de claves que afectan a la comunicación. Buscamos que no se escape ningún detalle, que no caiga en la improvisación ninguna parte esencial de una buena estrategia de comunicación, pero que, al tiempo, no te resulte un trabajo farragoso ni tedioso.
¿Y cómo interviene el Big Data en Outreach Tool?
Para realizar cualquier estrategia es imprescindible poseer información que nos indique que caminos tomar. Se puede trabajar con intuiciones, como hasta ahora se desarrollaban los planes de comunicación. También con la recogida “manual” de información con entrevistas, estudios, análisis, encuestas… Pero si esa información es obtenida a través del Big Data tendrá un grado de acierto mayor. Y, por supuesto, con la combinación de las tres vías, el resultado será todavía mejor.