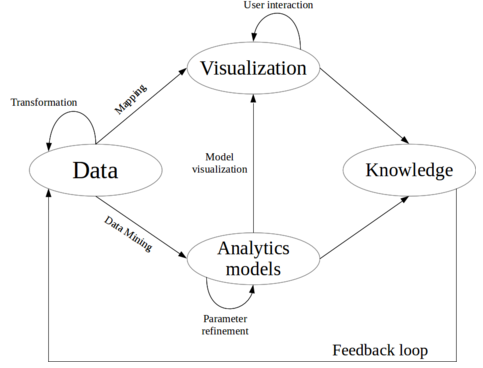
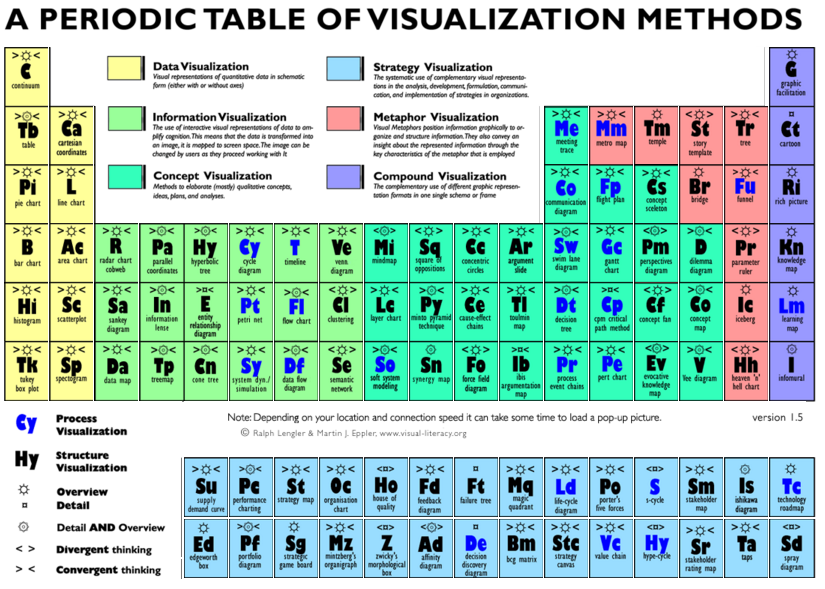
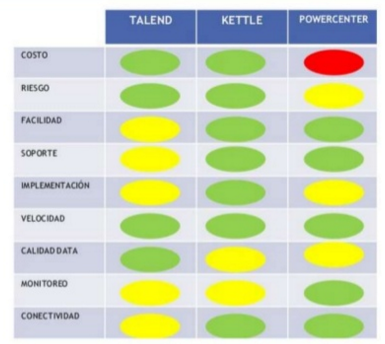
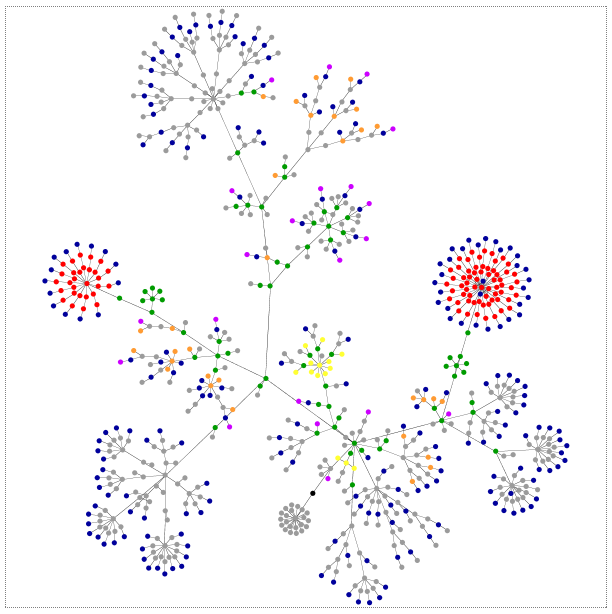
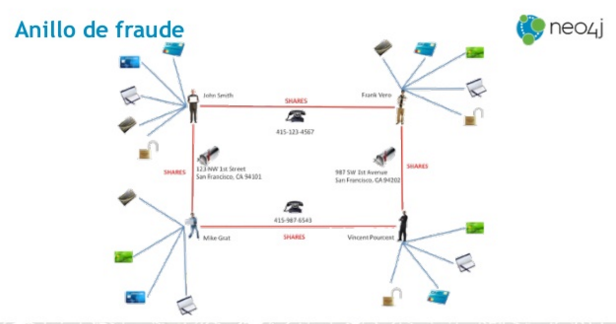
Recientemente, mi compañero Iñaki Pariente, nos ilustraba sobre la importancia de la componente jurídica en todo proyecto de Big Data. Estos días, en el Parlamento Europeo, se está produciendo mucha actividad en torno a todo ello. Concretamente, están trabajando una Propuesta de Reglamento General de Protección de Datos, del Parlamento Europeo y del Consejo.
El núcleo de lo que se está tratanto es la protección de las personas físicas en lo que respecta al tratamiento de datos personales y la libre circulación de estos datos. En adelante, a efectos de simplificación, me referiré a ello como Reglamento General de Protección de Datos (RGPD).
La legislación vigente en la Unión Europea en materia de protección de datos es la Directiva 95/46/CE. Esta fue adoptada en 1995 con un doble objetivo: defender el derecho fundamental sobre la protección de datos y garantizar la libre circulación de estos datos entre los Estados miembros (en una época en que la libre circulación de capitales, personas y bienes era algo del día a día). Se complementó posteriormente mediante la Decisión Marco 2008/977/JAI, como instrumento general a escala de la Unión Europea para la protección de datos personales tratados en contextos de cooperación policial y judicial.
Y ahora pasamos a 2015. La rapidez con que la evolución digital está cambiando muchos de los planos de nuestra sociedad y nuestra economía, ha supuestos nuevos retos en lo que a la protección de datos personales se refiere. Ahora, el volumen de datos es mucho mayor, permitiendo que tanto empresas privadas como entidades públicas pueden aprovecharlos. Además, las personas físicas, generan y difunden un volumen de datos nunca visto hasta la fecha.
A la par, los legisladores se dan cuenta que para poder desarrollar una sociedad realmente digital y un Mercado Único Digital (también debatido e impulsado hace unos meses en la Comisión Europea), es fundamental generar confianza en entornos online. Si la confianza no existe, las personas no nos veremos tan implicados en comprar online o a relacionarnos con la administración a través de Internet. La protección de datos personales desempeña, por tanto, una función esencial en la Agenda Digital para Europa y más concretamente en la Estrategia Europa 2020 para el crecimiento y la competitividad.
Esta nuevo reglamento de protección de datos, afectará a muchas personas e instituciones. Si tienes una empresa o aspiras a trabajar en una radicada en Europa o que haga negocios en Europa, tienes más de 250 trabajadores o tu núcleo de negocio se centra en el procesamiento de datos (que cada vez son más las empresas en ello), tu empresa tendrá, bajo propuesta de dicho Reglamento que contratar un Data Protection Officer (DPO en adelante).
Eso de «centrarse en el procesamiento de datos«, que resulta ciertamente ambiguo, por lo que he podido leer se refiere a «tratamientos de datos masivos, que afecten a centenares de miles o millones de usuarios y que se mantengan periódicamente actualizados como la elaboración de perfiles de clientes o en el mundo de marketing«. Por lo tanto, creo que no son pocas las empresas que quedarán afectadas por ello.
¿Y qué es esto del DPO y en qué medida me afectaría? Este perfil tendrá que encargarse de tareas mucho más extensas que las atribuidas al responsable de seguridad, figura regulada en el Reglamento que desarrolla la Ley Orgánica de Protección de Datos de España (que data de 1999). Este último, actualmente se encarga de «coordinar y controlar las medidas de seguridad«. Pero, el DPO tendrá una función no solo de seguridad, sino con una mirada hacia dentro de la organización y hacia fuera:
- Dentro de la empresa: informar y asesorar a todos los trabajadores de la organización en lo que a sus obligaciones con respecto a la normativa de protección de datos se refiere. Además, deberá elaborar los protocolos de asignación de responsabilidades y educación en esta materia, y velar por su cumplimiento. Por lo tanto, amplía sus funciones en esta materia.
- Fuera de la empresa: será el encargado de responder a las solicitudes de información de la autoridad de control -la Agencia Española de Protección de Datos (AEPD) o equivalentes en Comunidades Autónomas- y cooperar con ellao para cualquier solicitud.
Este proceso de «blindaje» será tan exigente que hará que las empresas tengan que publicar los datos de contacto de sus Data Protection Officer, así como comunicárselo a la autoridad de control. Esto hará un ejercicio de transparencia y accountability que emana la importancia que adquiere. Es más, el proyecto de reglamento determina que no podrá ser despedido o sancionado mientras ejerza y ejecute sus tareas (artículo 36.3), ni tampoco encontrar injerencias o instrucciones en el ejercicio de sus tareas. Dada la naturaleza del desempeño de sus funciones, está obligado a guardar secreto y confidencialidad. Y, aunque puede, dentro del organigrama de trabajo, tener asignadas otras funciones o tareas, éstas no pueden dar lugar a un conflicto de intereses.
¿Y qué pasa si no cumplo este reglamento? Las multas por no cumplir reglamentos Europeos son importantes; hasta un 2% de los Ingresos de la organización o 100 millones por cada infracción. Esto invita a la cooperación y complicidad por parte de las instituciones.
Como ven, la reglamentación para la protección de datos personales vuelve a endurecerse y hacer que Europa, siga fiel a su estilo de garantzar los derechos fundamentales de sus ciudadanos. Entenderán así, que la protección de datos quedó excluida de las negociaciones sobre el crucial tratado de Asociación Transatlántica de Comercio e Inversión que negocian la Unión Europea y Estados Unidos. Otro tema que traerá largas reflexiones. Y ahí veremos el papel del Data Protection Officer como eje clave en las organizaciones.