El nivel de madurez de una organización para afrontar proyectos de Big Data / Analytics es un elemento que siempre debemos tener presente. Un proyecto, con la mejor tecnología, no tiene por qué ser exitoso si no sumamos otros elementos que también contribuyen al resultado global del proyecto.
En estos años, hay organizaciones que se han dedicado a obtener frameworks para medir ese nivel de madurez de una organización. Uno de los que más nos gusta es éste que veis a continuación, el Analytics Maturity Quotient (AMQ™):
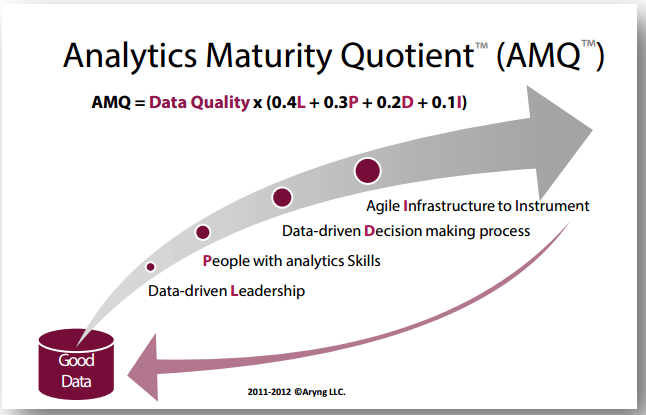
Como se puede apreciar, son cinco factores los que suman y contribuyen a ese nivel de madurez para afrontar estos proyectos en una organización:
- Calidad de los datos: todo empieza con la calidad de los datos. Nosotros estamos tan de acuerdo en ello, que nuestro primer módulo trata precisamente sobre la importancia de disponer de una buena calidad de datos. Si una organización tiene un buen sistema para el almacenamiento de datos, una buena infraesturctura de datos, ha empezado bien el proyecto. Aquí también suele citarse el paradigma «GIGO»: si metemos malos datos, por mucho que tengamos buenos modelos analíticos, no podremos obtener buenos resultados de nuestro proyecto de Big Data.
Este factor, el de calidad de datos, afecta a su vez a otros cuatro. Pero, como se puede entrever en su representación formal, es el más importante y representativo del conjunto de ellos. Debemos disponer de buenos datos. - Liderazgo «data-driven»: el 40% del éxito restante (una vez que disponemos de «buenos datos«), depende de un liderazgo institucional y organizativo que se crea de verdad que los datos y su análisis son una palanca excelente para la mejora de la toma de decisiones dentro de la compañía. En el artículo que abrió la boca a todos con esto del Big Data («Big Data: the management revolution«) de la Harvard Business Review, se ilustraba esta idea de cambiar el paradigma de toma de decisiones de la «persona que más ganaba» (el HIPPO, highest paid person’s opinion, a la fundamentación en datos). Necesitamos así líderes, CEO, gerentes, responsables de líneas, que «compren» este discurso y valor de los datos como palanca de apoyo a la toma de decisiones.
- Personas con habilidades analíticas: un 30% del éxito dependerá de disponer de un buen equipo. Éste, es ahora mismo el gran handicap en España, sin ir más lejos. Faltan «profesionales Big Data«, en todos los roles que esto puede exigir: Data Science para interrogar apropiadamente los datos, tecnólogos de Big Data con capacidades de despliegue de infraestructura, estadísticos y matemáticos, «visualizadores» de datos, etc. A esto, debemos sumarle la importancia de tener cierta orientación a procesos de negocio o mercado en general, dado que los datos son objetivos per se; de dónde se extrae valor es de su interpretación, interrogación y aplicación a diferentes necesidades de empresa. Ahora mismo, este handicap las empresas lo están resolviendo con la formación de las personas de su organización.
- Proceso de toma de decisiones «data-driven»: con el Big Data, obtendremos «insights». Ideas clave que nos permitirán mejorar nuestro proceso de toma de decisiones. Una orientación hacia el análisis de datos como la palanca sobre la que se tomarán las decisiones dentro de la compañía. Y las decisiones se toman, una vez que la orientación al dato se ha metido en los procesos. ¿Cómo tomaremos la decisión de invertir en marketing? ¿En base a la eficiencia de las inversiones y la capacidad de convertir a ventas? ¿O en base a un incremento respecto al presupuesto del ejercicio pasado? Los datos están para tomar decisiones, no para ser «un proyecto más«. Un 20% es éste factor crítico de éxito.
- Infraestructura tecnológica: por último, obviamente, es difícil emprender un proyecto de este calibre sin infraestructura tecnológica. Por tecnología Big Data no va a ser. Nosotros también le dedicamos un buen número de horas de otro módulo a ello. El panorama tecnológico es cada vez más amplio. Pero, ya ven los elementos anteriores que debemos tener en consideración antes de llegar a este punto.
En cierto modo, estos elementos (Calidad de los datos, Liderazgo, Personas, Decisiones con datos e Infraestructura), con diferentes pasos y orden de importancia, es lo mismo que viene a recomendar un libro que encuentro siempre muy interesante para comenzar con el Big Data: «Big Data: Using Smart Big Data, Analytics and Metrics to Make Better Decisions and Improve Performance«. De él, extraigo la siguiente imagen, que creo ilustra muy bien la idea:

Ya veis que esto del Big Data y Analytics no va solo de tecnología. Hay muchos otros factores. Que, todos ellos, afectan al nivel de madurez de una organización para sacar provecho de un proyecto de análisis de datos. Así que, para el próximo proyecto de Big Data que vayas a comenzar, ¿cómo tienes estos elementos de «maduros»?