Hay dos grandes formas de entender esta era del Big Data: como una evolución del Business Intelligence -herramientas que extraen inteligencia de la información de una compañía y sobre ésta elaboran algunas predicciones-, o como una disrupción. La primera consideración, suele descartarla.
El Business Intelligence, se significó en una época en la que eran los datawarehouse la norma. Es decir, grandes almacenes de datos, estructurados, con una administración rígida. No solo ya desde la óptica del almacenamiento del dato es diferente su consideración, sino también desde la mirada de procesamiento de datos. El BI tenía un marcado carácter descriptivo. En esta nueva era del Big Data, creo que la predicción es la norma y lo que todo el mundo quiere hacer. Adelantarse al futuro, pero de una manera más informada y evidenciada. Es decir, asentándose en la mayor cantidad de información posible.
Y esto, claro, como hemos comentado muchas veces, es más posible que nunca antes en la historia, por la gran cantidad de datos existentes. Pero, son datos, que muchas veces, no podemos estructurar (la lógica seguida por los datawarehouse). Son datos, además, que muchas veces, no se pueden «juntar» con otros; es mejor mantenerlos por separado, y luego ya tratar de juntarlos en tiempo de procesamiento para la extracción de valor.
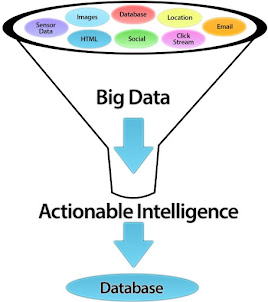
Esta lógica, va un paso más allá dentro del paradigma del Big Data. Supone considerar el dato como otro activo más. Es más, supone considerar el dato como el activo más crítico de la organización. Y así, disponer de un «data capital», como otro activo más de la organización, que permita ser luego capitalizado y activado para su puesta en valor en la organización. Es decir, el almacenamiento en bruto de datos, puede ser interesante, sin mayor orden, estructura ni criterio de clasificación.
El problema es que en este momento, la mayor parte de las empresas (tanto grandes, medianas como pequeñas), está aún en la fase inicial: recopilan la información y la almacenan. Pero todavía no saben muy bien qué se puede hacer con ella. Por ello mismo, ya hay algunos que empiezan a considerar que en este estadío, en el que todavía las organizaciones no saben muy bien qué hacer, pero sí que disponen de datos, es fundametal articular una estrategia de almacenamiento de datos con sentido.
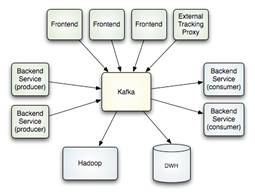
Y aquí, emerge con fuerza el concepto de «data lake». Como se puede ver en la siguiente representación gráfica, se trata de un repositorio de datos estructurados y no estructurados, sin ningún preprocesamiento, guardando los datos en bruto, y sin esquema. A los que venimos originariamente de la administración de bases de datos y sus esquemas rígidos, un concepto, un paradigma, sustantivamente diferente. Al carecer de esquema, añadir nuevos datos, será relativamente fácil.
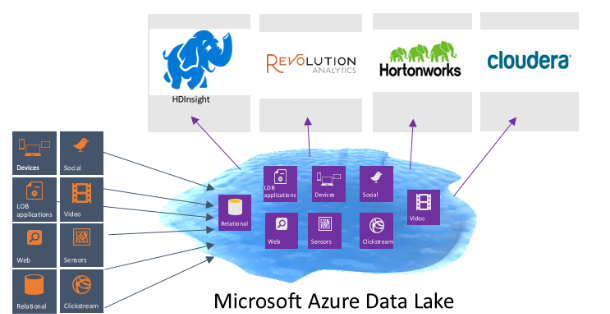
Se trata, en definitiva, de proveer a las empresas de un mecanismo de almacenamiento de datos sin mayor compromiso. Ya veremos en qué momento se nos ocurre qué hacer. El problema que veníamos arrastrando, es que los sistemas de esquemas de datos, en muchas ocasiones, condicionaban luego lo que poder hacer con los datos. Porque ya representaban «algo».
Con esta explicación, se puede entender por qué esta era del Big Data, es para mí un paso más allá del Business Intelligence. En la era del BI, todos los datos que recogíamos (estructurados y no estructurados), los ordenábamos y clasificábamos según el esquema. En un data lake, también recogemos todos los datos, pero no los alteramos, limpiamos o manipulamos. Su valor queda bruto, y ya veremos en su día qué hacer con ello.
Sin alterar la «materia prima» y dejarla en bruto, dejamos abierto el campo de explotación. Y estas opciones, tan prometedoras para muchas empresas, es lo que está haciendo que cada vez más empresas me pregunten por los data lakes. Es algo que para la capitalización del dato dentro de las organizaciones, se alinea muy bien. Ya veremos algún día qué preguntas hacerles a los datos. Todavía no lo sabemos, pero no nos importa. Sabemos que esos datos tendrán valor.
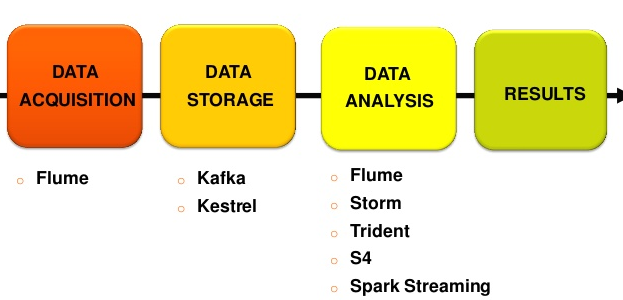
Por todo esto, ya hay muchos profesionales del Big Data que dicen de cambiar el paradigma ETL (Extract, Transform, Load, del que ya hablé aquí) por ELT (Extract, Load, Transform). Es decir, ya transformaremos después, no antes, lo que suele restringir mucha las opciones de lo que podremos hacer. Los data lakes, precisamente adoptan ese rol de almacén de datos «neutro», en el que no condicionamos luego lo que se podrá hacer. Y por eso, las herramientas ELT (que no son nuevas, por otro lado), también pudieran vivir un renacimiento.
Para cerrar, una imagen muy representativa de la idea trasladada hoy.