La Facultad de Ingeniería de la Universidad de Deusto en colaboración con Gaiaorganiza una jornada dirigida a profesionales en torno a la Industria 4.0 y el Big Data.
La evolución operativa y técnica de los sectores industriales y de servicios va a requerir de nuevas herramientas, como consecuencia de la transformación digital de las organizaciones. Este cambio requiere, por parte de los profesionales, de una inmersión en conceptos, conocimiento y tecnología que puede reforzar la trayectoria profesional de los trabajadores y/o generar nuevas oportunidades de empleo para jóvenes y profesionales.
Objetivos generales
Compartir las previsiones de evolución operativa y técnica que van a experimentar los sectores industriales, y otras actividades de servicios conexas, como consecuencia del desarrollo de la transformación digital de las organizaciones.
Poner al alcance de los asistentes conceptos y casos aplicados de empresas en el desarrollo de actividades 4.0 en sus tres fases: preproducción, producción o postproducción.
Objetivos específicos
Reflexionar sobre iniciativas que refuercen las competencias de los profesionales ante este nuevo escenario.
Reflexionar sobre las oportunidades de desarrollar nuevos servicios gracias a la implantación de las TEIC en la industria.
Ofrecer herramientas y soluciones para el desarrollo profesional en la nueva sociedad digitalizada.
Entender las oportunidades que abre este paradigma del Big Data a la industria en el País Vasco como en el desarrollo de la estrategia industria 4.0.
Programa
09:45 Inscripción y Registro (Free/ Gratuita)
10:00 Presentación de la jornada y avance de las oportunidades
Alex Rayón, Vicedecano de Relaciones Externas y Formación Continua de la Facultad de Ingeniería y Director Programa Big Data en Donostia – San Sebastián y Business Intelligence
Tomás Iriondo, Director General de Gaia. Presentación de Oportunidades en la Industria 4.0 desde el Sector TEIC
10:35 Mesa Redonda y Debate
Alex Rayón, Vicedecano de Relaciones Externas y Formación Continua de la Facultad de Ingeniería y director Programa Big Data en Donostia – San Sebastián y Business Intelligence – Moderador
La participación en esta jornada es gratuita, si bien dado el aforo limitado del espacio rogamosconfirmación de asistencia a través del siguiente enlace
Para cualquier consulta o duda sobre la sesión pueden contactar con nosotros en el correo: formacion.ingenieria@deusto.es o en el teléfono: 94 413 92 08
Universidad de Deusto Donostia (Fuente: http://deustoemprende.deusto.es/lets-discover-innogune/)
(venimos de una serie de un artículo introductorio a los tres paradigmas, y de uno anterior hablando del paradigma batch)
Decíamos en el artículo anterior, que a la hora de procesar grandes volúmenes de datos existen dos principales enfoques: procesar una gran cantidad de datos por lotes o bien hacerlo, en pequeños fragmentos, y en «tiempo real». Parece, así, bastante intuitivo pensar cuál es la idea del paradigma en tiempo real que trataremos en este artículo.
Este enfoque de procesamiento y análisis de datos se asienta sobre la idea de implementar un modelo de flujo de datos en el que los datos fluyen constantemente a través de una serie de componentes que integran el sistema de Big Data que se esté implatando. Por ello, se le como como procesamiento «streaming» o de flujo. Así, en tiempos muy pequeños, procesamos de manera analítica parte de la totalidad de los datos. Y, con estas características, se superan muchas de las limitaciones del modelo batch.
Por estas características, es importante que no entendamos este paradigma como la solución para analizar un conjunto de grandes datos. Por ello, no presentan esa capacidad, salvo excepciones. Por otro lado, una cosa es denominarlo «tiempo real» y otra es realmente pensar que esto se va a producir en veradero tiempo tiempo. Las limitaciones aparecen por:
Se debe disponer de suficiente memoria para almacenar entradas de datos en cola. Fíjense en la diferencia con el paradigma batch, donde los procesos de Map y Reduce podrían ser algo lentos, dado que escribían en disco entre las diferentes fases.
La tasa de productividad del sistema debería ser igual o más rápida a la tasa de entrada de datos. Es decir, que la capacidad de procesamiento del sistema sea más ágil y eficiente que la propia ingesta de datos. Esto, de nuevo, limita bastante la capacidad de dotar de «instantaneidad al sistema».
Plataforma de analítica Big Data en tiempo real (Fuente: https://infocus.emc.com/wp-content/uploads/sites/8/2013/02/Real-time-Analytic-Platforms-Enable-New-Value-Creation-Opportunities.png)
Uno de los principales objetivos de esta nueva arquitectura es desacoplar el uso que se hacía de Hadoop MapReduce para dar cabida a otros modelos de computación en paralelo como pueden ser:
MPI (Message Passing Interface): estándar empleado en la programación concurrente para la sincronización de procesos ante la existencia de múltiples procesadores.
Spark: plataforma desarrollada en Scala para el análisis avanzado y eficiente frente a las limitaciones de Hadoop. Tiene la habilidad de mantener todo en memoria, lo que le da ratios de hasta 100 veces mayor rapidez frente a MapReduce. Tiene un framework integrado para implementar análisis avanzados. Tanto Cloudera, como Hortonworks, lo utilizan.
Y, con estos nuevos modelos, como hemos visto a lo largo de esta corta pero intensa historia del Big Data, aparecen una serie de tecnologías y herramientas que permiten implementar y dar sentido a todo este funcionamiento:
Flume: herramienta para la ingesta de datos en entornos de tiempo real. Tiene tres componentes principales: Source (fuente de datos), Channel (el canal por el que se tratarán los datos) y Sink (persistencia de los datos). Para entornos de exigencias en términos de velocidad de respuesta, es una muy buena alternativa a herramientas ETL tradicionales.
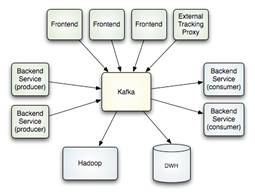
Kafka: sistema de almacenamiento distribuido y replicado. Muy rápido y ágil en lecturas y escrituras. Funciona como un servicio de mensajería y fue creado por Linkedin para responder a sus necesidades (por eso insisto tanto en que nunca estaríamos hablando de «Big Data» sin las herramientas que Internet y sus grandes plataformas ha traído). Unifica procesamiento OFF y ON, por lo que suma las ventajas de ambos sistemas (batch y real time). Funciona como si fuera un cluster.
Storm: sistema de computación distribuido, por lo que se emplea en la etapa de análisis de datos (de la cadena de valor de un proyecto de Big Data). Se define como un sistema de procesamiento de eventos complejos (Complex Event Processing, CEP), lo que le hace ideal para responder a sistemas en los que los datos llegan de manera repentina pero continua. Por ejemplo, en herramientas tan habituales para nosotros como WhatsApp, Facebook o Twitter, así como herramientas como sensores (ante la ocurrencia de un evento) o un servicio financiero que podamos ejecutar en cualquier momento.
Vistas estas tres tecnologías, queda claro que la arquitectura resultante de un proyecto de tiempo real quedaría compuesto por Flume (ingesta de datos de diversas fuentes) –> Kafka (encolamos y almacenamos) –> Storm (analizamos).
Vistas todas estas características, podemos concluir que para proyectos donde el «tamaño» sea el *verdadero* problema, el enfoque Batch será el bueno. Cuando el «problema» sea la velocidad, el enfoque en tiempo real, es la solución a adoptar.
(venimos de un artículo introductorio a los tres paradigmas)
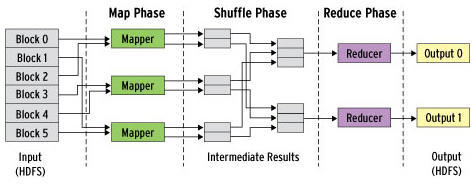
Cuando hablamos del verdadero momento en el que podemos considerar nace esta «era del Big Data», comentamos que se puede considerar el desarrollo de MapReduce y Hadoop como las primeras «tecnologías Big Data». Estas tecnologías se centraban en un enfoque de Batch Processing. Es decir, el objetivo era acumular todos los datos que se pudieran, procesarlos y producir resultados que se «empaquetaban» por lotes.
Con este enfoque, Hadoop ha sido la herramienta más empleada. Es una herramienta realmente buena para almacenar enormes cantidades de datos y luego poder escalarlos horizontalmente mientras vamos añadiendo nodos en nuestro clúster de máquinas.
Big Data Batch Processing (Fuente: http://www.datasciencecentral.com/profiles/blogs/batch-vs-real-time-data-processing)
Como se puede apreciar en la imagen, el «problema» que aparece en este enfoque es que el retraso en tiempo que introduce disponer de un ETL que carga los datos para su procesamiento, no será tan ágil como hacerlo de manera continua con un enfoque de tiempo real. El procesamiento en trabajos batch de Hadoop MapReduce es el que domina en este enfoque. Y lo hace, apoyándose en todo momento de un ETL, de los que ya hablamos en este blog.
Hasta la fecha la gran mayoría de las organizaciones han empleado este paradigma «Batch». No era necesaria mayor sofisticación. Sin embargo, como ya comentamos anteriormente, existen exigencias mayores. Los datos, en muchas ocasiones, deben ser procesados en tiempo real, permitiendo así a la organización tomar decisiones inmediatamente. Esas organizaciones en las que la diferencia entre segundos y minutos sí es crítica.
Hadoop, en los últimos tiempos, es consciente de «esta economía de tiempo real» en la que nos hemos instalado. Por ello, ha mejorado bastante su capacidad de gestión. Sin embargo, todavía es considerado por muchos una solución demasiado rígida para algunas funciones. Por ello, hoy en día, «solo» es considerado el ideal en casos como:
No necesita un cálculo con una periodicidad alta (una vez al día, una vez al de X horas, etc.)
Cálculos que se deban ejecutar solo a final de mes (facturas de una gran organización, asientos contables, arqueos de caja, etc.)
Generación de informes con una periodicidad baja.
etc.
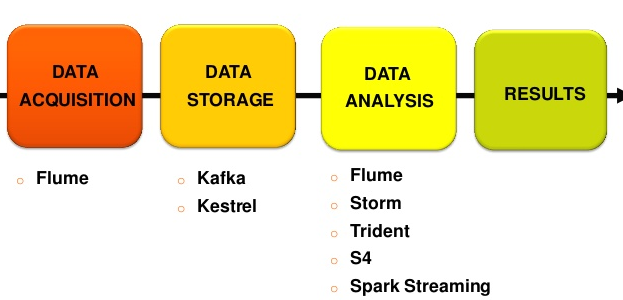
Como el tema no es tan sencillo como en un artículo de este tipo podamos describir, en los últimos años han nacido una serie de herramientas y tecnologías alrededor de Hadoop para ayudar en esa tarea de analizar grandes cantidades de datos. Para analizar las mismas -a pesar de que cada una de ellas da para un artículo por sí sola-, lo descomponemos en las cuatro etapas de la cadena de valor de un proyecto de Big Data:
1) Ingesta de datos
Destacan tecnologías como:
Flume: recolectar, agregar y mover grandes cantidades de datos desde diferentes fuentes a un data store centralizado.
Comandos HDFS: utilizar los comandos propios de HDFS para trabajar con los datos gestionados en el ecosistema de Hadoop.
Sqoop: permitir la transferencia de información entre Hadoop y los grandes almacenes de datos estructurados (MySQL, PostgreSQL, Oracle, SQL Server, DB2, etc.)
2) Procesamiento de datos
Destacan tecnologías como:
MapReduce: del que ya hablamos, así que no me extiendo.
Hive: framework creado originalmente por Facebook para trabajar con el sistemas de ficheros distribuidos de Hadoop (HDFS). El objetivo no era otro que facilitar el trabajo, dado que a través de sus querys SQL (HiveQL) podemos lanzar consultas que luego se traducen a trabajos MapReduce. Dado que trabajar con este último resultaba laborioso, surgió como una forma de facilitar dicha labor.
Pig: herramienta que facilta el análisis de grandes volúmenes de datos a través de un lenguaje de alto nivel. Su estructura permite la paralelización, que hace aún más eficiente el procesamiento de volúmenes de datos, así como la infraestructura necesaria para ello.
Cascading: crear y ejecutar flujos de trabajo de procesamiento de datos en clústeres Hadoop usando cualquier lenguaje basado en JVM (la máquina virtual de Java). De nuevo, el objetivo es quitar la complejidad de trabajar con MapReduce y sus trabajos. Es muy empleado en entornos complejos como la bioinformática, algoritmos de Machine Learning, análisis predictivo, Web Mining y herramientas ETL.
Spark: facilita enormemente el desarrollo de programas de uso masivo de datos. Creado en la Universidad de Berkeley, ha sido considerado el primer software de código abierto que hace la programación distribuida accesible y más fácil para «más públicos» que los muy especializados. De nuevo, aporta facilidad frente a MapReduce.
3) Almacenamiento de datos
Destacan tecnologías como:
HDFS: sistema de archivos de un cluster Hadoop que funciona de manera más eficiente con un número reducido de archivos de datos de gran volumen, que con una cantidad superior de archivos de datos más pequeños.
HBase: permite manejar todos los datos y tenerlos distribuidos a través de lo que denominan regiones, una partición tipo Nodo de Hadoop que se guarda en un servidor. La región aleatoria en la que se guardan los datos de una tabla es decidida, dándole un tamaño fijo a partir del cual la tabla debe distribuirse a través de las regiones. Aporta, así, eficiencia en el trabajo de almacenamiento de datos.
4) Servicio de datos
En esta última etapa, en realidad, no es que destaque una tecnología o herramienta, sino que destacaría el «para qué» se ha hecho todo lo anterior. Es decir, qué podemos ofrecer/servir una vez que los datos han sido procesados y puestos a disposición del proyecto de Big Data.
Seguiremos esta serie hablando del enfoque de «tiempo real», y haciendo una comparación con los resultados que ofrece este paradigma «batch».
Lo que podemos llamar como la cadena de valor de un proyecto Big Data consiste básicamente en recopilar/integrar/ingestar, procesar, almacenar y servir grandes volúmenes de datos. Eso es, en esencia, lo que hacemos en un proyecto de BIg Data. Para ejecutar esas funciones, como hemos comentado en este blog en varias ocasiones, tenemos una serie de tecnologías, que suelen ser citadas en ocasiones en relación a la función que ejercen. Es lo que aprendemos en nuestro módulo M2.2 del Programa de Big Data y Business Intelligence de nuestra universidad.
Dado el interés que está despertando en los últimos años la parte «procesamiento» (debido fundamentalmente a cómo se origina esto del Big Data) es interesante hablar de las diferentes alternativas tecnológicas que existen para procesar «Big Data». Ya saben, datos que se disponen en grandes volúmenes, que se generan a gran velocidad y con una amplitud de formatos importante.
Esta etapa de la cadena de valor es la responsable de recoger los datos brutos y convertirlos/transformarlos a datos enriquecidos que pueden dar respuesta a la pregunta que nos estamos haciendo. Y para enfrentar esta etapa, en los últimos años, se han desarrollado dos paradigmas fundamentales:
Paradigma «Batch Processing«: son procesos que se asientan fundamentalmente en el paradigma MapReduce, que ya explicamos en un artículo anterior, y que decíamos, permitió comenzar esta apasionante carrera alrededor del Big Data. Siguen el modelo «batch» que tan importante resultó en el mundo de la informática original: se ejecutan de manera periódica y trabajan con grandísimos volúmenes de datos.
Existen varias alternativas para proveer de estos servicios: la más importante es Hadoop MapReduce, que funciona dentro del framework de aplicaciones de Hadoop. Se apoya en el planificador YARN. Dado el bajo nivel con el que trabajan estas tecnologías, estos últimos años han nacido soluciones de más alto nivel para ejecutar estas tareas, tales como Apache Pig.
Estamos hablando de tecnologías que funcionan realmente bien con grandes cantidades de datos. Sin embargo, los procesos de Map y Reduce pueden ser algo lentos cuando estamos hablando de cantidades realmente «BIG», dado que escriben en disco entre las diferentes fases. Por ello, como siempre, se produce una evolución natural, y aparecen tecnologías que resuelven este problema, entre las que destaca Apache Spark.
Haremos un artículo separado, dada su importancia, para hablar exclusivamente y en detalle de este paradigma «Batch Processing«.
Paradigma «Streaming Processing«: a diferencia del enfoque «batch» anterior, el «streaming», como su propio concepto describe, funciona en tiempo real. Si antes decíamos que un proyecto «Big Data» consta de cuatro etapas –(1) Ingestión; (2) Procesamiento; (3) Almacenamiento y (4) Servicio-, con este enfoque, nada más ser «ingestados», son transferidos a su procesamiento. Esto, además, se hace de manera continua. En lugar de tener que procesar «grandes cantidades», son, en todo momento, procesadas «pequeñas cantidades».
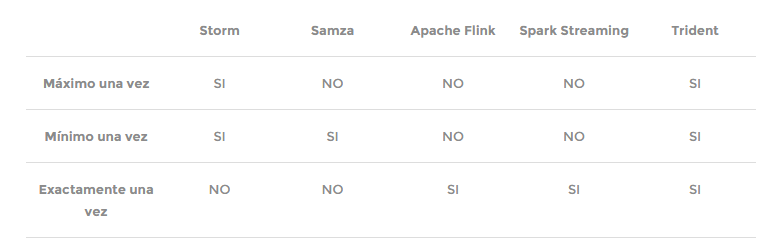
Como con el enfoque batch, hay una serie de tecnologías que permiten hacer esto. Se pueden clasificar en dos familias: 1) Full-streaming: Apache Storm, Apache Samza y Apache Flink; y 2) Microbatch: Spark Streaming y Storm Trident.
Son tecnologías que procesan datos en cuestión de mili o nanosegundos. Se diferencian entre ellas por las garantías que aportan ante fallos en la red o en los sistemas de información. La siguiente tabla resume muy bien estas diferencias. Por lo tanto, más que por «gustos», la diferencia puede radicar en cuanto a su «sistema de garantías»:
Fuente: http://madrid.bigdataweek.com/2015/11/18/tecnologias-en-el-mundo-del-big-data/
Haremos un artículo separado, dada su importancia, para hablar exclusivamente y en detalle de este paradigma «Streaming Processing«.
A estos dos, podemos añadir la arquitectura Lambda, la más reciente en llegar a este mundo de necesidades en evolución de las diferentes alternativas de procesar datos. Provee parte de solución Batch y parte de solución en Tiempo Real. Como su propio creador Nathan Marz explica aquí:
The lambda architecture solves the problem of computing arbitrary functions on arbitrary data in real time by decomposing the problem into three layers: the batch layer, the serving layer, and the speed layer.
Estamos hablando de diferentes paradigmas; esto es, de diferentes maneras de afrontar el problema. Y dada la importancia de cada uno de ellos, he considerado interesante hacer un artículo monográfico de cada una de ellas. Paradigmas que nos van a ayudar a procesar las grandes cantidades de datos de un proyecto de Big Data. Y conocer y empezar a dominar así las tecnologías que disponemos para cada paradigma.
Comentábamos en un artículo anterior, que fue allá por 2012 cuando se empieza a popularizar el término Big Data en el acervo popular. Pero eso no quiere decir, que sea entonces cuando podamos decir que comienza esta era del Big Data. De hecho, los orígenes son bastante anteriores.
Hablan de un nuevo modelo de programación que permite simplificar el procesamiento de grandes volúmenes de datos. Lo bautizan como MapReduce. Básicamente es la evolución natural y necesaria que tenían dentro de Google para procesar los grandes volúmenes de datos que ya por aquel entonces manejaban (documentos, referencias web, páginas, etc.). Lo necesitaban, porque a partir de toda esa información, sacaban una serie de métricas que luego les ayudó a popularizar industrias como el SEO y SEM. Vamos, de lo que hoy en día vive Google (Alphabet) y lo que le ha permitido ser la empresa de mayor valor bursátil del mundo.
La idea que subyace a este nuevo modelo de programación es el siguiente: ante la necesidad de procesar grandes volúmenes de datos, se puede montra un esquema en paralelo de computación que permita así distribuir el trabajo (el procesamiento de datos) entre diferentes máquinas (nodos dentro de una red) para que se pueda reducir el tiempo total de procesamiento. Es decir, una versión moderna del «divide y vencerás«, que hace que ese trabajo menor en paralelo, reduzca sustantivamente lo que de otra manera sería un único, pero GRAN trabajo.
Distribución de trabajo a través del modelo MapReduce (Fuente: http://www.admin-magazine.com/HPC/Articles/MapReduce-and-Hadoop)
En aquel entonces, estos grandes «visionarios del Big Data» (luego volvemos a ello), se dieron cuenta que este problema que tenía Google en esos momentos, lo iban a tener otras cuantas aplicaciones. Así que decidieron desarrollar un modelo de programación que se desacoplara de las necesidades concretas de Google, y se pudiera generalizar a un conjunto de aplicaciones que pudieran luego reutilizarlo. Pensaron en un inicio a todos los problemas que pudiera tener el propio buscador. Pero se dan cuenta que quizás todavía hay un universo más amplio de problemas, por lo que se abtsrae y generaliza aún más.
De hecho, lo simplificaron tanto que dejaron la preocupación del programador en dos funciones:
Map: transforma un conjunto de datos de partida en pares (clave, valor) a otro conjunto de datos intermedios también en pares (clave, valor). Un formato, que hará más eficiente su procesamiento y sobre todo, más fácil su «reconstruccón» futura.
Reduce: recibe los valores intermedios procesados en formato de pares (clave, valor) para agruparlos y producir el resultado final.
Este paradigma lo adoptó Google allá por 2004. Y dado el rendimiento que tenía, se comenzó a emplear en otras aplicaciones (como decíamos ahora). Se comienzan luego a desarrollar versiones de código abierto en frameworks. Esto hace muy fácil su rápida adopción, y quizás deja una lección para la historia sobre cómo desarrollar rápidamente un paradigma.
Uno de los frameworks que comienza a ganar en popularidad es Apache Hadoop. Y, para muchos, aquí nace esta era del «Big Data». El creador del framework Hadoop se llama «Doug» Cutting, una persona con una visión espectacular. En cuanto leyó la publicación de Dean y Ghemawat se dio cuenta que si crease una herramienta bajo el paradigma MapReduce, ayudaría a muchos a procesar grandes cantidades de datos. Cutting acabó luego trabajando en Yahoo!, que es donde realmente empujó el proyecto Hadoop (qué vueltas da la vida…).
El ecosistema Hadoop consta de una serie de módulos como los que se pueden encontrar en la imagen debajo de estas líneas. Pero en su día, fueron dos sus principales componentes, y los que dan otro nuevo empuje a esta era del Big Data:
HDFS: una implementación open-source de un sistema distribuido de ficheros (que ya había descrito Google en realidad).
MapReduce: utilizando HDFS como soporte, la implementación del modelo de programación que hemos descrito al comienzo.
La historia sobre el origen y verdadero impulso a esta era del «Big Data», puede cerrarse con la salida de Yahoo! de Cutting en 2009. Se incorpora a Cloudera, empresa que comienza a dar servicio, soporte y formación de Hadoop a otras empresas. Para esa fecha, Hadoop ya era un ecosistema de módulos y aplicaciones, que merecen cada una un hilo aparte para entender las grandes aportaciones que hicieron las personas que hemos comentado en este artículo. Por cierto, mucha de esta historia la cuenta el propio Cutting en este hilo de Quora.
En definitiva, primero MapReduce, y luego el framework Hadoop, pueden ser considerados como el origen de esta era Big Data de la que tanto hablamos hoy en día. Y, las empresas de Internet (Google, Yahoo, hablaremos luego de Twitter, Facebook, Linkedin, etc.), las que propician la aparición de tecnologías de Big Data que luego son llevadas a otros sectores.
Es innegable que la palabra «Big Data» lleva ya tiempo con nosotros y está de moda. Su uso no ha parado de crecer desde mediados de 2012, que es cuando aparecen varios artículos que comienzan a popularizar el paradigma.
Es tanto su uso, que ha dado un salto desde los foros más tecnológicos a los más populares. Son varios periódicos generalistas que se atreven a encabezar sus noticias con titulares como éstos:
Este tipo de titulares, ha provocado que ahora todo el mundo diga que «hace Big Data» o que todos los problemas de una empresa «se arreglen haciendo Big Data«. Ojo, no con esto se debe quitar valor a lo que hacen. Lo que ocurre, es que quizás no estén poniendo en valor el paradigma del Big Data. Sino que puede que estén haciendo un proyecto de Data Mining o Minería de datos de toda la vida. Pero de eso, no se habla en las noticias. En la siguiente gráfica de Google Trends podéis ver cómo para la categoría de «Noticias», últimamente se cita mucho «Big Data», pero bastante menos «Data Mining» o «Minería de Datos».
Creo que debiéramos empezar a ser un poco más rigurosos en su uso. Es decir, debiéramos empezar a preguntarnos si es «Big Data» todo lo que decimos que lo es. Y es que sino a este paso, ocurrirá como ya pasó con términos como «calidad» o «innovación«, que de tanto uso, ahora la gente se muestra reacia al valor que aportan disponer de importantes equipos de calidad e innovación.
Y es que el uso de los métodos de análisis de datos para la mejora de la competitividad y el día a día de las organizaciones no es nada nuevo. Hace décadas que llevamos haciendo uso de estas técnicas. Quizás no en todos los sectores (lo que ahora sí podemos decir está ocurriendo). Pero en el sector financiero o asegurador, llevan décadas empleando técnicas de minería de datos para sacar valor de sus grandes volúmenes de datos. Lo han empleado siempre para la detección de fraudes, perfiles de propensión al impago o para el scoring en la concesión de créditos.
Sí que es cierto que estos métodos, ahora son más sofisticados. Pero eso realmente no se debe a la evolución de los algoritmos solo, sino a la existencia de una mayor cantidad de datos, de muy diferentes fuentes, almacenados en muy diferentes formatos y sobre todo, generados a gran velocidad. Y esto último sí que hace distinguir un proyecto de Big Data de otro que no lo es.
Lo que ocurre en un momento determinado en el tiempo es que se empieza a popularizar el término «Big Data» cuando otro tipo de empresas no financieras ni aseguradoras, especialmente las grandes tecnológicas, comienzan a aplicar esas técnicas de minería de datos. Pero se dan cuenta que muchas de las técnicas que se venían empleando no son válidas. Básicamente por:
El gran volumen de datos que disponen
La gran variedad de formatos de datos
La velocidad a la que generan nuevos datos
Sí, estamos hablando de las famosas 3 «V» que se concibieron inicialmente, que son las 3 (por mucho que ahora haya una burbuja de «V») que creo siguen caracterizando y definiendo mejor a este paradigma del «Big Data». Volumen, Variedad y Velocidad. Y son estas 3 «V», las que hace que nos demos cuenta que lo que veníamos haciendo hasta la fecha no es válido. Se necesitan nuevas tecnologías. Y se desarrollan varias nuevas tecnologías que hacen más fácil tan ardua labor, especialmente el modelo MapReduce y los sistemas de ficheros distribuidos. Y, el trabajo que anteriormente era imposible o muy difícil hacerlo, ahora se hace posible gracias a un conjunto de máquinas (clústers) que se distribuyen el trabajo, y que en agregado, superan a cada máquina que anteriormente existía.
Por todo ello, creo que es compartido por todos afirmar que no todas las empresas que hagan uso de técnicas de minería de datos están haciendo uso del Big Data. Como paradigma que es, existen una seria de condicionantes del problema que lo hacen singular y diferente. Y por ello, es importante dejar claro que, por favor, no usemos el término allí donde no aplique. Y aplica, en aquellos contextos que se rigen por ese paradigma de las 3 «V» que caracterizan muy bien los retos que tienen muchas empresas por delante.
Lugar: Hirikalabs. Digital Culture & Technology Laboratory.
Este sábado 16 de Julio la experta en tecnologías de los movimientos sociales y comunidades de hackers Stefania Milan estará en Tabakalera el sábado, 16 de julio, a las 16:00, en Hirikilabs, hablando de activismo de datos. La profesora de nuestra universidad Miren Gutiérrez moderará el debate. Te puedes registrar en este enlace.
Stefania es profesora asistente de New Media y Cultura Digital de la Universidad de Amsterdam, directora del laboratorio de datos J Lab, dedicado a análisis del fenómeno Big Data, y la investigadora principal de DATACTIVE, un proyecto acerca de políticas de Big Data, financiado por el Consejo Europeo de Investigación.
Es una apasionada de la interacción entre las tecnologías y la sociedad, y en particular, investiga las posibilidades de auto-organización y emancipación que ofrece la tecnología digital. Experta en ciencias políticas por formación, se siente en casa en la investigación interdisciplinaria que abarca los estudios críticos de internet y los Big Data, de los movimientos sociales, y de la tecnología.
La presentación se centra en la epistemología de los datos y la noción de activismo datos. Vivimos en una época de abundancia de datos, uno en el que los datos son mucho más que una mercancía o una herramienta para la vigilancia, sino más bien una metáfora del poder. El boom actual de los «datos» como motor de las sociedades contemporáneas ha afectado no sólo a los gobiernos y las empresas, sino también a la sociedad civil organizada. Los datos son una metáfora de la transparencia y una herramienta para la movilización también, y han inspirado una serie de prácticas en ciudadanía, incluyendo las iniciativas de los hackers cívicos, y las campañas que se aprovechan de la «libertad de información» la legislación. El proyecto, todavía en su infancia, explora cómo los movimientos y la ciudadanía utilizan los datos y las técnicas de periodismo de datos (como el arte de conseguir historias a partir de números) para provocar el cambio social.
Stefania tiene un doctorado en Ciencias Políticas y Sociales del Instituto Universitario Europeo (IUE) (2009). Antes de unirse a la EUI, estudió Ciencias de la Comunicación en la Universidad de Padua, Italia.
Es co-presidenta del Grupo de Trabajo de Política de Comunicación IAMCR. Actualmente es parte del Comité Ejecutivo de la circunscripción de uso no comercial de la ICANN. También miembro varias asociaciones académicas, entre ellas la Asociación Internacional de Comunicación, Giganet, la Asociación de Estudios Internacionales, la Asociación Europea de Sociología. Como consultora, ha trabajado para la Comisión Europea, el Ministerio de Educación italiano, y muchas ONG internacionales.
Nada más hacerse público el caso de los Papeles de Panamá, escribimos un artículo en este blog para describir cómo el paradigma del Big Data (con sus método de trabajo del dato, sus tecnologías, su aproximación al dato, etc.) había jugado un papel fundamental para ser clave y posibilitar el procesamiento de la mayor filtración de la historia del periodismo (2.6 terabytes, y 11,5 millones de documentos -Wikileaks, para que se hagan a la idea, fueron 1,7 GB “solo”-).
Tuvieron muchos problemas con la calidad de los datos. Estaban muy «sucios», y dedicaron gran cantidad del tiempo a ponerlos limpios y eficientes para su procesamiento.
Nos introdujo las tecnologías que han estado detrás de la investigación y cómo han jugado un papel totalmente determinante para que fuera un éxito el proyecto. En esta entrada ya detallamos todas las tecnologías, pero por resumir las más determinantes, Mar nos habló de Talend como ETL, NEO4J para almacenamiento y Linkurious para la representación visual. Su expresividad y las facilidades para el descubrimiento de conocimiento, fueron aspectos críticos.
Entre los 11,5 millones de documentos de la filtración, prácticamente 5 millones eran emails, 3 millones formatos de bases de datos, 2.1 millones PDFs, 1.1 millones eran imágenes y el resto, otro tipo de documentos. Como vemos, el grado de no-estructuración de la información y los datos era tan alto, que la importancia de las tecnologías que facilitan el procesamiento de datos no estructurados, ha sido de vital importancia.
Nos habló mucho sobre cómo la visualización resulta crítica para que la gente luego entienda el conocimiento hallado de una manera bastante resumida y ágil. En la visualización que han realizado en colaboración con The Guardian, destacó The Power Players, que podéis consultar aquí.
No solo se trata de la mayor filtración de la historia del periodismo, sino también de la mayor colaboración de la historia del periodismo. La importancia que ha tenido el haber compartido datos dentro del marco de un consorcio, trabajando con una tecnología de red social abierta, ha sido crítica. Se han evitado los silos de datos, clave para que se pudieran compartir los documentos del despacho Mossack Fonseca.
Las tecnologías de bases de datos de grafos les han permitido una navegación por la información tan eficiente, que han sido capaces de procesar en meses lo que de otra manera les hubiera llevado años. De esto ya hablamos en una entrada anterior. Ella lo llamó «magia» destacando lo siguiente (literal):
Hago clicks en “puntos” y encuentro historias!
Descubro nuevos nombres con las búsquedas fuzzy
Encuentra el camino más corto (shortest path)
Si a alguien le interesa, y quiere adentrarse en la base de datos de grafos generada y estructurada para modelizar los Papeles de Panamá, puede acceder aquí. Un ejercicio de transparencia y colaboración al que Mar no paraba de invitarnos.
Para terminar, os dejo los vídeos de su intervención completa, así como la entrevista que la hicimos (que resume los puntos comentados anteriormente). Un caso, como ven, el de los Papeles de Panamá, en el que el Big Data ha aportado a la sociedad mucho.
Nunca antes se había utilizado las tecnologías Big Data para estudiar la pesca ilegal. Un nuevo informe del Overseas Development Insitute (ODI), el mayor centro de investigación de temas relacionados con el desarrollo de Reino Unido, y porCausa, una organización española especializada en periodismo de investigación, las utiliza precisamente para analizar y hacer emerger prácticas dudosas en alta mar.
El informe proporciona pruebas de estas prácticas, que comprometen la eficacia del sistema de gobernanza multilateral diseñado para acabar con la pesca ilegal.
Uno de los hallazgos de la investigación surge de la visualización de las señales que emitieron los 35 reefers-enormes buques de carga congeladores- que operaron en la región durante 2013. Por ejemplo, se ve claramente que algunos de ellos pudieron haber contribuido a la pesca ilegal en las zonas económicas exclusivas de Senegal y Costa de Marfil, donde el trasbordo de pescado está prohibido.
Los datos sobre los que se cimenta el informe provienen de la mayor base de datos dedicada a barcos pesqueros -con datos históricos de más de 740.000 barexcos y miles de millones de posiciones geográficas registradas desde 2009- que está en manos de la empresa FishSpektrum. Para comunicar y visualizar los resultados de dicha investigación, se utiliza tecnología de la empresa CartoDB, que ha colaborado en el proyecto.
Tras interrogar la base de datos para determinar qué reefers operaron en África Occidental en 2013 y sus detalles (propiedad, operador, dueño, bandera, capacidad de carga, etc.), se adquirieron sus señales AIS, que están obligados a emitir regularmente buques de cierto tamaño y que son capturadas por satélites y antenas terrestres.
Cada señal se emite con una frecuencia variable en función del tipo de barco -pesqueros cada 10 minutos, reefers cada media hora aproximadamente- y contiene una marca temporal estándar o timestamp y la posición geográfica de cada barco. Estas señales se han cruzado con otras fuentes de datos geográficos sobre el litoral, sus puertos y las zonas de exclusión económica de la costa africana usando tecnología GIS para producir el set de datos que alimenta la visualización en CartoDB.
La visualización consiste en una aplicación web estática que usa la API de CartoDB para mostrar las rutas de cada reefer sobre un mapa junto con una animación de su posición durante el año 2013. Esta herramienta hace accesible el gran volumen de información que se posee actualmente de cada reefer para realizar análisis de su comportamiento.
Así quedan en evidencia comportamientos sospechosos que muestran un patrón movimientos errático o en zigzag, típico de los reefers que están a la búsqueda de barcos pesqueros con las bodegas llenas que deseen deshacerse de su pescado para seguir faenando.
La práctica del transbordo de pescado en las zonas exclusivas es muy común, pero hay mucha presión política y de grupos de campaña para que se prohíba cuando no puede ser supervisada por observadores a bordo de los reefers por ser un verdadero “coladero” de pesca ilegal. La Unión Europea, por ejemplo, veda la entrada de pescado transbordado por barcos con bandera de cualquier país de la Unión.
Como ven, el Big Data, ayudando también en causas sociales que permitan mejorar nuestra sociedad.
El pasado viernes 17 de Junio, invitaron a @deusto #bigdata a participar en una jornada organizada por la Universidad de Islas Baleares en torno al Big Data y sus aplicaciones. Obviamente, en Baleares, donde el turismo supone aproximadamente la mitad del PIB de la región, mucha de la conversación se centró en cómo operadores, plataformas, etc. utilizan el análisis masivo de datos para el desarrollo turístico.
Entre las ponencias, una de las que más me llamó la atención fue la del CEO y fundador de Mallorca Wifi, Maurici Socias. Una persona con la que luego tuve rato para conversar y entender bien lo que para mí ha sido un auténtico descubrimiento y muy grata sorpresa. Un emprendedor nato que llevo más de 20 años en el sector de las telecomunicaciones, en constante “reinvención” por la propia evolución del sector. He de decirles que es una auténtica gozada escucharle hablar de sus proyectos desde los tiempos de Terra, pasando por los inicios de Google y el Marketing Digital en España, hasta llegar a la competición atroz actual en la que el Big Data y el Marketing Intelligence pueden aportar tanto a la eficiencia de las acciones de una compañía. Quería, por ello, compartir con todos vosotros el modelo de Mallorca Wifi y cuál es su relación con el mundo del Big Data.
Fuente: Mallorca Wifi
Una de las cosas que llama la atención cuando le escuchas describir qué es Mallorca Wifi es su propuesta de valor como “agencia de medios”. Sí, Mallorca Wifi es una agencia de medios. Una agencia, eso sí, que creo, no tiene mucha competencia. ¿Por qué? Por su capacidad de segmentar, personalizar la oferta, hilar bien fino y sobre todo, hacer un marketing centrado en el consumidor.
Os he hablado en anteriores ocasiones de lo que puede aportar el Big Data al mundo del marketing actual. Seguimos, aún hoy en día, y a pesar de las grandes bondades tecnológicas existentes, en un marketing masivo, en el que impactamos a muchas personas a la vez, con la esperanza matemática que solo por estadística, “alguno caerá”. El problema de este modelo, no solo es que su concepción se hizo en una época en la que las capacidades tecnológicas eran bastante limitadas y tenía bastante sentido, sino que es que además, los consumidores estamos muy cansados de los modelos publicitarios actuales. Son totalmente invasivos, nos generan una mala experiencia de usuario y consumidor, por lo que resultan poco eficientes para las marcas.
Sin embargo, las empresas siguen todavía apostando por esos modelos. Quizás es que los puestos de dirección de marketing necesiten también ese espíritu emprendedor por soportes que tengan un nuevo modelo. Nuevos formatos en los que el consumidor sea consecuencia y no causa; es decir, no vayamos a donde haya consumidores, sino traigamos a los consumidores a un nuevo esquema de relación. Un esquema en el que los impactos publicitarios tengan valor y no les resulte incómodo.
Pues bien, aunque pueda sorprender, un nuevo soporte de valor y centrado en el consumidor es Mallorca Wifi. Sí, un operador de infraestructura Wifi, es, bajo mi punto de vista, uno de los soportes más eficienes que puede haber. Y, hasta donde sé, un modelo sin precedentes en España. ¿Qué hace Maurici con Mallorca Wifi? Básicamente ofrecer a un visitante de Palma (extendiendo ahora su ámbito de actuación por toda la isla) wifi gratis sin solicitarle datos a cambio. Sin que tengamos que introducir datos de registro tan molestos como anticuados para las capacidades tecnológicas actuales. Y totalmente gratis, insisto. Y sin financiación pública.
Aquí es cuando le pregunté a Maurici una cosa tan básica como: “Entonces, ¿cómo ganáis dinero?”. Pues básicamente introduciendo la posibilidad para las marcas de “patrocinar” la conexión al Wifi en puntos estratégicos de Palma de Mallorca. Piensen en ustedes mismos, cuando no quieren consumir ese recurso tan escaso como son los datos, y prefieren conectarse a una wifi gratuita que encima no le pide datos personales. La relación que estableceré con esa empresa, esa marca, que le da Wifi gratis, será bastante afectiva, y estará usted muy agradecido por ello. En definitiva, convertir una infraestructura Wifi en un nuevo soporte publicitario. Bajo mi punto de vista, un modelo totalmente innovador y de valor. Que tardarán todavía muchas empresas en entender, pero que aquellas que lo hagan, le sacarán importantes beneficios, por el engagement que genera con el usuario.
Fuente: Mallorca Wifi
¿Y qué tiene que ver todo esto con el Big Data? Pues bastante. De hecho, Maurici está ahora explorando la posibilidad de abrir una nueva línea de trabajo en torno a ello. Piensen ustedes que todos aquellos dispositivos móviles que lleven la Wifi encendido (que son prácticamente todos), tratan de conectarse a los puntos de acceso que tiene Mallorca Wifi. En ese momento, se obtienen muchos datos sobre el dispositivo, pudiendo llegar a caracterizar a ese usuario por el idioma del móvil (de dónde viene), cómo se desplaza (por tener intercalados los puntos de acceso), a qué velocidad lo hace, si acude a esos puntos con bastante regularidad, si lo hace siempre acompañado de otro dispositivo móvil, a qué hora lo hace, etc.
Si esos datos son anonimizados, y agregados en su conjunto, la capacidad de Mallorca Wifi de diseñar y lanzar una línea de negocio basado en datos de marketing contextual es bastante potente. Y, bajo mi punto de vista, otro caso más de lo que considero un movimiento brillante: dotarse de una infraestructura (wifi en este caso) que sea capaz de generar datos, que luego resulten de valor para diferentes propuestas de valor. Lo mismo que ocurre con una tarjeta de fidelización, un CRM o las líneas de telecomunicación tradicionales que tanto han trabajo con el Big Data.
El marketing contextual inteligente, se hace así posible, gracias a los datos que genera una red inteligente como esta. Todo ello, respetando al usuario, su privacidad y la ley. Brillante, y realmente inteligente. Mi más sincera enhorabuena y ánimo a personas emprendedoras que apuestan por la innovación y el dato como futuras palancas de desarrollo. Mallorca Wifi, una agencia de medios sobre una red Wifi gracias al Big Data.