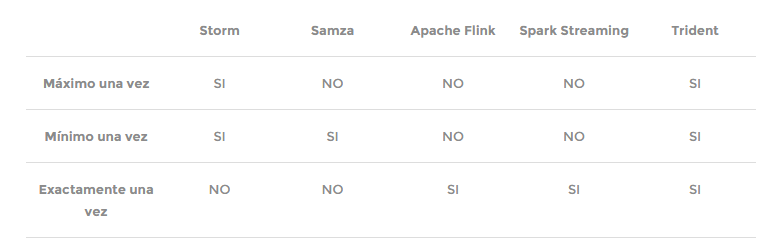
(venimos de un artículo introductorio a los tres paradigmas)
Cuando hablamos del verdadero momento en el que podemos considerar nace esta «era del Big Data», comentamos que se puede considerar el desarrollo de MapReduce y Hadoop como las primeras «tecnologías Big Data». Estas tecnologías se centraban en un enfoque de Batch Processing. Es decir, el objetivo era acumular todos los datos que se pudieran, procesarlos y producir resultados que se «empaquetaban» por lotes.
Con este enfoque, Hadoop ha sido la herramienta más empleada. Es una herramienta realmente buena para almacenar enormes cantidades de datos y luego poder escalarlos horizontalmente mientras vamos añadiendo nodos en nuestro clúster de máquinas.
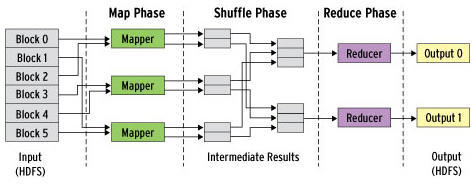
Como se puede apreciar en la imagen, el «problema» que aparece en este enfoque es que el retraso en tiempo que introduce disponer de un ETL que carga los datos para su procesamiento, no será tan ágil como hacerlo de manera continua con un enfoque de tiempo real. El procesamiento en trabajos batch de Hadoop MapReduce es el que domina en este enfoque. Y lo hace, apoyándose en todo momento de un ETL, de los que ya hablamos en este blog.
Hasta la fecha la gran mayoría de las organizaciones han empleado este paradigma «Batch». No era necesaria mayor sofisticación. Sin embargo, como ya comentamos anteriormente, existen exigencias mayores. Los datos, en muchas ocasiones, deben ser procesados en tiempo real, permitiendo así a la organización tomar decisiones inmediatamente. Esas organizaciones en las que la diferencia entre segundos y minutos sí es crítica.
Hadoop, en los últimos tiempos, es consciente de «esta economía de tiempo real» en la que nos hemos instalado. Por ello, ha mejorado bastante su capacidad de gestión. Sin embargo, todavía es considerado por muchos una solución demasiado rígida para algunas funciones. Por ello, hoy en día, «solo» es considerado el ideal en casos como:
- No necesita un cálculo con una periodicidad alta (una vez al día, una vez al de X horas, etc.)
- Cálculos que se deban ejecutar solo a final de mes (facturas de una gran organización, asientos contables, arqueos de caja, etc.)
- Generación de informes con una periodicidad baja.
- etc.
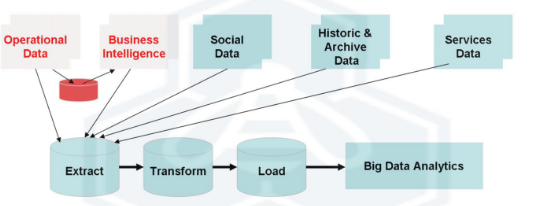
Como el tema no es tan sencillo como en un artículo de este tipo podamos describir, en los últimos años han nacido una serie de herramientas y tecnologías alrededor de Hadoop para ayudar en esa tarea de analizar grandes cantidades de datos. Para analizar las mismas -a pesar de que cada una de ellas da para un artículo por sí sola-, lo descomponemos en las cuatro etapas de la cadena de valor de un proyecto de Big Data:
1) Ingesta de datos
Destacan tecnologías como:
- Flume: recolectar, agregar y mover grandes cantidades de datos desde diferentes fuentes a un data store centralizado.
- Comandos HDFS: utilizar los comandos propios de HDFS para trabajar con los datos gestionados en el ecosistema de Hadoop.
- Sqoop: permitir la transferencia de información entre Hadoop y los grandes almacenes de datos estructurados (MySQL, PostgreSQL, Oracle, SQL Server, DB2, etc.)
2) Procesamiento de datos
Destacan tecnologías como:
- MapReduce: del que ya hablamos, así que no me extiendo.
- Hive: framework creado originalmente por Facebook para trabajar con el sistemas de ficheros distribuidos de Hadoop (HDFS). El objetivo no era otro que facilitar el trabajo, dado que a través de sus querys SQL (HiveQL) podemos lanzar consultas que luego se traducen a trabajos MapReduce. Dado que trabajar con este último resultaba laborioso, surgió como una forma de facilitar dicha labor.
- Pig: herramienta que facilta el análisis de grandes volúmenes de datos a través de un lenguaje de alto nivel. Su estructura permite la paralelización, que hace aún más eficiente el procesamiento de volúmenes de datos, así como la infraestructura necesaria para ello.
- Cascading: crear y ejecutar flujos de trabajo de procesamiento de datos en clústeres Hadoop usando cualquier lenguaje basado en JVM (la máquina virtual de Java). De nuevo, el objetivo es quitar la complejidad de trabajar con MapReduce y sus trabajos. Es muy empleado en entornos complejos como la bioinformática, algoritmos de Machine Learning, análisis predictivo, Web Mining y herramientas ETL.
- Spark: facilita enormemente el desarrollo de programas de uso masivo de datos. Creado en la Universidad de Berkeley, ha sido considerado el primer software de código abierto que hace la programación distribuida accesible y más fácil para «más públicos» que los muy especializados. De nuevo, aporta facilidad frente a MapReduce.
3) Almacenamiento de datos
Destacan tecnologías como:
- HDFS: sistema de archivos de un cluster Hadoop que funciona de manera más eficiente con un número reducido de archivos de datos de gran volumen, que con una cantidad superior de archivos de datos más pequeños.
- HBase: permite manejar todos los datos y tenerlos distribuidos a través de lo que denominan regiones, una partición tipo Nodo de Hadoop que se guarda en un servidor. La región aleatoria en la que se guardan los datos de una tabla es decidida, dándole un tamaño fijo a partir del cual la tabla debe distribuirse a través de las regiones. Aporta, así, eficiencia en el trabajo de almacenamiento de datos.
4) Servicio de datos
En esta última etapa, en realidad, no es que destaque una tecnología o herramienta, sino que destacaría el «para qué» se ha hecho todo lo anterior. Es decir, qué podemos ofrecer/servir una vez que los datos han sido procesados y puestos a disposición del proyecto de Big Data.
Seguiremos esta serie hablando del enfoque de «tiempo real», y haciendo una comparación con los resultados que ofrece este paradigma «batch».