(artículo escrito por Jon Goikoetxea Goiri, sociólogo y alumno de la primera promoción del Programa de Big Data y Business Intelligence, consultor en Marketing estratégico, analítico e Investigación de Mercados y exdirector de marketing de DEIA y GRUPO NOTICIAS -área de Estrategia y Medios Digitales- (2009-2016).
*********************************
La paradoja fundamental de la situación actual de los medios de comunicación -al menos desde el punto de vista de sus modelos de negocio– reside en que al desarrollo de la demanda no le acompaña simultáneamente una evolución positiva de sus modelos de negocio. Nunca anteriormente se consumió comunicación e información en semejante medida. Y, sin embargo, cada vez resulta más complicado hallar un solo medio de comunicación con sus cifras de negocio siquiera en equilibrio. Y ello a nivel mundial.
En los últimos decenios, y de manera significativamente más acelerada en los últimos años, la transformación de los modelos de negocio de los medios de comunicación ha abarcado desde la reestructuración de la propuesta de valor de producto/servicio hasta el significado del consumo para el usuario, lector, espectador, oyente. El cambio en las pautas, la distribución, las configuraciones de la demanda y, last but not least, en la esencia misma del ‘qué’ comunicativo: los antaño medios de información han devenido genéricos medios de comunicación. Los periódicos en amplísimas ediciones digitales. Las televisiones, en una multiplicidad de canales targetizados, formatos multiplataforma de emisión y con la incorporación del consumo diferido. Las radios, en la amplificación de sus programaciones a través de podcast y reemisiones a la carta.
La digitalización de la creación y distribución de contenidos audiovisuales ha convertido a la mera captación de la atención en el campo de batalla, en la sustancia, la naturaleza, en la materia prima del modelo Media actual. Ello ha afectado de manera definitiva a los soportes comunicativos tradicionales, y significadamente a la prensa al tratarse del único medio de pago, frente a radio, televisión y, actualmente, los medios digitales de orientación generalista.
Pero la digitalización también ha incluido a la generación de datos -al dato mismo- en la fórmula misma para aproximarse a la reformulación de su valor, para aprehender qué está ocurriendo con el sentido y las pautas de consumo de Medios. Para adaptar, expresado simplificadamente, la estructura de la oferta de medios a las nuevas configuraciones de la demanda, de la audiencia, del público. Al fin y al cabo, la digitalización es dato. En sí misma.
Comprender y dotar de sentido a lo que está ocurriendo es el pilar mismo de la reconversión industrial en la que se hallan los medios de comunicación. Ubicar el dato en el núcleo, la condición de posibilidad misma para la reformulación de su valor, o para ahondar en sus condiciones de monetización, si se prefiere el apremio.
Ese tránsito traumático de lo analógico a lo digital, ese salto abismal que puede metaforizarse en la conversión del módulo de prensa tradicional en herramientas de gestión de campañas de publicidad programática personalizada ha supuesto también la transformación de los paradigmas de análisis impactando directamente sobre las segmentaciones del marketing como base para la toma de decisiones. La complejidad del consumo de medios actual requiere de paradigmas analíticos a esa altura.

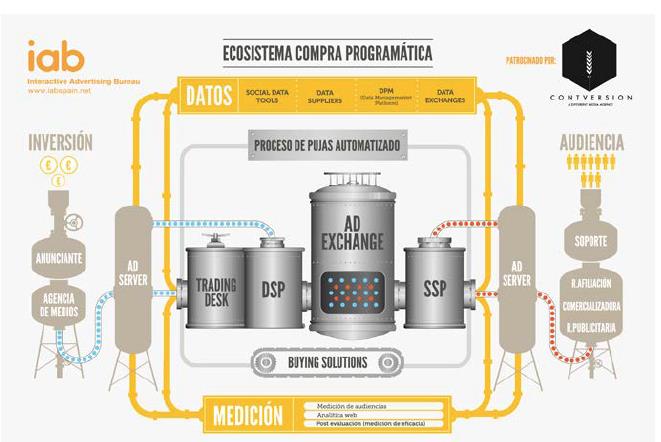
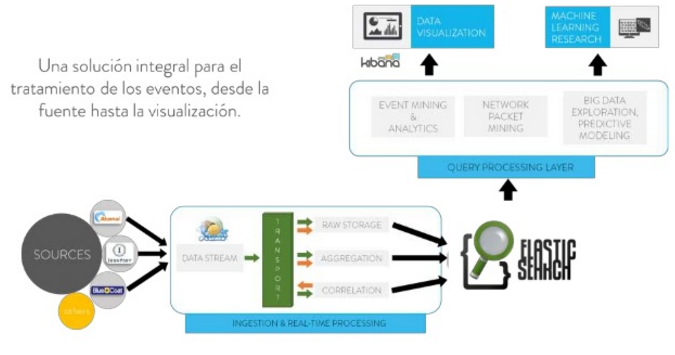
Y todo ello, por último, en un hábitat en el que el volumen, la variedad, la diversidad, y la velocidad de generación de datos de consumo e interacción de los usuarios crece extraordinariamente, muy probablemente por encima de la capacidad de empresas y organizaciones -de los medios de comunicación en su configuración actual- para organizarlos, dotarlos de un framework analítico sólido, productivo y continuo y digerirlos con orientación de generación de valor de negocio.
Una única cuestión es segura, entre todo: el dato estará en el centro del futuro de los medios de comunicación. Conformará el eje del cambio de paradigma que acompañará todo ello, desde la rutinaria perspectiva contenido-céntrica a una usuario-céntrica y dotada de esquemas de análisis que trasciendan los marcos actuales de comprensión del consumo de medios y contemplen algoritmos y modelizaciones de carácter más avanzado y complejo. A la altura analítica de lo que ocurre. El Big Data llama a las puertas del futuro de los medios de comunicación.